
Рефераты по геополитике
Рефераты по государству и праву
Рефераты по гражданскому праву и процессу
Рефераты по делопроизводству
Рефераты по кредитованию
Рефераты по естествознанию
Рефераты по истории техники
Рефераты по журналистике
Рефераты по зоологии
Рефераты по инвестициям
Рефераты по информатике
Исторические личности
Рефераты по кибернетике
Рефераты по коммуникации и связи
Рефераты по косметологии
Рефераты по криминалистике
Рефераты по криминологии
Рефераты по науке и технике
Рефераты по кулинарии
Рефераты по культурологии
Рефераты по зарубежной литературе
Рефераты по логике
Рефераты по логистике
Рефераты по маркетингу
Рефераты по международному публичному праву
Рефераты по международному частному праву
Рефераты по международным отношениям
Рефераты по культуре и искусству
Рефераты по менеджменту
Рефераты по металлургии
Рефераты по муниципальному праву
Рефераты по налогообложению
Рефераты по оккультизму и уфологии
Рефераты по педагогике
Рефераты по политологии
Рефераты по праву
Биографии
Рефераты по предпринимательству
Рефераты по психологии
Рефераты по радиоэлектронике
Рефераты по риторике
Рефераты по социологии
Рефераты по статистике
Рефераты по страхованию
Рефераты по строительству
Рефераты по схемотехнике
Рефераты по таможенной системе
Сочинения по литературе и русскому языку
Рефераты по теории государства и права
Рефераты по теории организации
Рефераты по теплотехнике
Рефераты по технологии
Рефераты по товароведению
Рефераты по транспорту
Рефераты по трудовому праву
Рефераты по туризму
Рефераты по уголовному праву и процессу
Рефераты по управлению
Курсовая работа: История статистики
Курсовая работа: История статистики
Работу выполнил: Serk
МГТУ «Станкин»
2003 год
Тема 1. Статистическая сводка. Группировка
Статистическая сводка является вторым этапом статистического исследования после наблюдения. Она состоит в том, что первичные материалы, полученные в результате наблюдения, обрабатываются, сводятся вместе и характеризуются итоговыми обобщающими показателями.
Составными элементами сводки являются: 1) программа сводки; 2) подсчет групповых итогов; 3) оформление конечных результатов сводки в виде таблиц и графиков.
Программа статистической сводки содержит перечень групп, на которые расчленена изучаемая совокупность по определенным признакам, а также перечень показателей, необходимых для характеристики каждой группы. Программа сводки имеет, как правило, вид свободных статистических таблиц, которые следует заполнить расчетными данными.
В сводке статистического материала важное звено занимают группировки, так как простой подсчет итогов без распределения единиц совокупности на группы по тем или иным признакам не дает полной характеристики объекта изучения.
К статистическим группировкам прибегают при решении следующих задач:
а) анализ структуры исследуемой совокупности;
б) выявление связей и взаимозависимостей между экономическими явлениями.
Для решения первой задачи строят структурные группировки.
Для решения второй задачи строят аналитические группировки.
Группировки бывают простые и комбинационные. Простая группировка образуется по одному признаку, комбинационная - по двум и более признакам. Можно осуществлять группировки как по количественному признаку, так и по атрибутивному. В количественной группировке группировочный признак выражается вариантами чисел. В атрибутивной группировке группировочный признак количественного выражения не имеет, так как характеризует качество изучаемого явления.
В экономико-статистическом анализе делаются группировки как с равными, так и с неравными интервалами. При построении группировки с равными интервалами величину интервала групп определяют по следующей формуле:
![]() ,
,
где Xmax - максимальное значение признака в изучаемой совокупности; Xmin - минимальное значение признака в изучаемой совокупности; n - число групп.
При выборе числа групп необходимо учитывать следующее: 1) в каждую группу может попасть по возможности достаточно большое число единиц; 2) число единиц в группах не должно резко отличаться друг от друга, т.е. должно быть примерно одного порядка; 3) групп должно быть не более 6-7.
Группировки с неравными интервалами целесообразно применять в тех случаях, когда исходные статистические данные разнятся на весьма значительную величину, т.е. когда слишком велик размах вариации в исходной совокупности.
Рассмотрим пример на построение аналитической группировки.
Таблица 1.1
Данные о стоимости основных фондов и товарной продукции предприятий
|
№ п/п |
Средняя годовая стоимость основных производственных фондов, млн. руб. | Товарная продукция, млн. руб. |
№ п/п |
Средняя годовая стоимость основных производственных фондов, млн. руб. | Товарная продукция, млн. руб. |
| 1 | 396 | 947,6 | 11 | 220 | 390,1 |
| 2 | 305 | 602,7 | 12 | 318 | 537,6 |
| 3 | 198 | 399,6 | 13 | 290 | 436,8 |
| 4 | 386 | 897,0 | 14 | 327 | 700,0 |
| 5 | 315 | 642,6 | 15 | 208 | 590,4 |
| 6 | 330 | 675,0 | 16 | 318 | 591,6 |
| 7 | 205 | 348,3 | 17 | 245 | 511,8 |
| 8 | 302 | 582,4 | 18 | 340 | 669,6 |
| 9 | 211 | 378,3 | 19 | 249 | 537,6 |
| 10 | 306 | 494,1 | 20 | 199 | 315,0 |
По отчетным данным 20 промышленных предприятий нужно построить аналитическую группировку для установления зависимости объема товарной продукции от средней годовой стоимости основных производственных фондов (табл. 1.1).
Для построения группировки выделим группировочный признак. Таким группировочным признаком является средняя годовая стоимость основных производственных фондов. Примем число групп по данному признаку n = 5. Величину интервала в группах определяем по приведенной выше формуле. Тогда h = (396 – 198) : 5 = 39,6 млн. руб.
Образуем группы предприятий по средней годовой стоимости основных производственных фондов. Нижнюю границу первого интервала составит минимальная величина группировочного признака 198 млн. руб. Верхняя граница первого интервала составит 198 + 39,6 = 237,6 млн. руб.
При группировках по непрерывно варьирующим количественным признакам границу интервалов обозначают так, что верхняя граница предыдущего интервала служит нижней границей последующего интервала.
Таким образом, нижней границей второго интервала будет величина 237,6 млн. руб., а верхней границей данного интервала - величина 237,6 + 39,6 = 277,2 млн. руб. Аналогично определяются границы последующих интервалов.
Получаем следующие интервалы для 5 групп предприятий по средней годовой стоимости основных производственных фондов: 198 - 237,6; 237,6 - 277,2; 277,2 - 316,8; 316,8 - 356,4; 356,4 - 396,0. В первую группу вошло 6 предприятий; во вторую - 2; в третью - 6; в четвертую - 4; в пятую - 2.
Так как по условию задачи необходимо установить зависимость объема товарной продукции от средней годовой стоимости основных производственных фондов, то в каждой выделенной группе определяем суммарную величину объема товарной продукции по совокупности предприятий в группе и в расчете на одно предприятие.
По первой группе предприятий со средней годовой стоимостью основных производственных фондов от 198 млн. руб. до 237,6 млн. руб. объем товарной продукции составит: 399,6 + 348,3 + 378,3 + 350,1 + 590,4 + 315,0 = 2381,7 млн. руб., и в расчете на одно предприятие: 2381,7 : 6 = 396,9 тыс. руб. Аналогичные расчеты производим по другим группам.
Результаты расчетов сведем в табл. 1.2.
Таблица 1.2
Расчет среднего объема товарной продукции по группам предприятий
| Группа предприятий по средней годовой стоимости производственных фондов | Число предприятий | Объем товарной продукции, млн. руб. | Объем товарной продукции в среднем одного предприятия в группе, млн. руб. |
| 198 - 237,6 | 6 | 2381,7 | 396,9 |
| 237,6 - 277,2 | 2 | 1049,4 | 524,2 |
| 277,2 - 316,8 | 6 | 3433,6 | 572,3 |
| 316,8 - 356,4 | 4 | 2499,8 | 624,7 |
| 356,4 - 396,0 | 2 | 1844,6 | 922,7 |
На основе построенной группировки видна четкая зависимость объема товарной продукции от средней годовой стоимости основных производственных фондов предприятия.
Используя условие данной задачи, построим структурную группировку.
Для построения структурной группировки необходимо сформировать группы по второму признаку - величине товарной продукции. Возьмем число групп n = 5; границы интервалов групп определяем по формуле величины интервала группировки h, где
![]() 126,52
млн. руб.
126,52
млн. руб.
Группы предприятий, образованные по объему товарной продукции, следующие: 315,0 - 441,52; 441,52 - 568,04; 568,04 - 694,56; 694,56 - 821,08; 821,08 - 947,6.
В дальнейшем, осуществляя распределение предприятий в группах по средней годовой стоимости основных производственных фондов на подгруппы по объему товарной продукции, сформируем структурную группировку (табл. 1.3).
На основе структурной группировки отчетливо видно распределение предприятий по объему товарной продукции в зависимости от той или иной средней годовой стоимости производственных фондов.
Таблица 1.3
Структурная группировка предприятий по двум показателям
| Группа предприятий по средней годовой стоимости ОПФ, млн. руб. | Число предприятий | в том числе с объемом товарной продукции, млн. руб. | ||||
| 315,0 - 441,52 | 441,52 - 568,04 | 568,04 - 694,56 | 694,56 - 821,08 | 821,08 - 947,6 | ||
| 198 - 237,6 | 6 | 5 | 1 | |||
| 237,6 - 277,2 | 2 | 2 | ||||
| 277,2 - 316,8 | 6 | 1 | 4 | |||
| 316,8 - 356,4 | 4 | 1 | 2 | 1 | ||
| 356,4 - 396,0 | 2 | 2 | ||||
Предприятия сосредоточены, главным образом, по диагонали, что еще раз подчеркивает наметившуюся тенденцию увеличения объема товарной продукции при возрастании стоимости основных производственных фондов предприятия.
Тема 2. Ряды распределения. Статистические таблицы
В результате обработки и систематизации первичных статистических данных получают ряды цифровых показателей, которые характеризуют отдельные стороны изучаемых явлений. Эти ряды называют статистическими.
Статистические ряды делят на два вида: ряды распределения и ряды динамики. Ряды распределения характеризуют распределение единиц совокупности по какому-либо признаку. Ряды динамики характеризуют изменение изучаемых явлений во времени.
Ряды распределения, в свою очередь, делятся на атрибутивные и вариационные. Атрибутивный ряд распределения образуется по качественному признаку. Вариационный ряд образуется по количественному признаку.
Среди вариационных рядов распределения выделяют дискретные и интервальные ряды.
В дискретном вариационном ряду распределения отдельные варианты имеют определенные конкретные значения. В интервальном вариационном ряду варианты колеблются в определенных пределах. Вариационные ряды изображают в системе прямоугольных координат в виде диаграмм.
Дискретные вариационные ряды изображают в виде так называемого полигона распределения. Варианты откладываются на оси абсцисс, частоты - на оси ординат. Точки пересечения соединяются отрезками прямой.
Интервальные вариационные ряды изображают в виде гистограммы. На оси абсцисс откладывают границы интервалов, на оси ординат - число единиц совокупности, приходящееся на единицу ширины интервала (плотность распределения). В интервалах строят прямоугольники.
Для изображения интервальных вариационных рядов с равными интервалами на оси абсцисс откладывают границы интервалов, а на оси ординат - число единиц совокупности в данном интервале. Строят прямоугольники с равными интервалами.
Интервальный вариационный ряд можно изображать также в виде кумуляты. На оси абсцисс откладывают границы интервалов, на оси ординат - нарастающие частоты, соответствующие верхним границам интервалов. Точки пересечения соединяют отрезками прямой.
Статистические ряды как результат статистической сводки и группировки всегда излагаются в виде статистических таблиц.
Статистическая таблица представляет собой форму наиболее рационального, наглядного и систематизированного изложения цифровых результатов сводки и обработки статистического материала.
При построении статистических таблиц следует четко разграничивать статистическое подлежащее и статистическое сказуемое. Статистическим подлежащим таблицы является сам объект (перечень его единиц или их групп), который характеризуется числовыми показателями. Статистическим сказуемым таблицы являются числовые показатели, которые характеризуют изучаемый объект.
Статистическое подлежащее располагают, как правило, в строках, статистическое сказуемое - в графах таблицы.
В зависимости от строения подлежащего различают три вида таблиц: простые, групповые, комбинационные.
Простые (перечневые) таблицы в подлежащем содержат перечень рассматриваемых объектов.
Групповые таблицы в подлежащем содержат группировку единиц изучаемого объекта, образованную по какому-либо одному признаку.
Комбинационные таблицы в подлежащем содержат группировку единиц, образованную по двум и более признакам.
При построении таблиц следует строго придерживаться определенных правил:
1. Каждая таблица должна быть пронумерована и иметь заголовок, который в краткой форме должен отражать содержание таблицы, место и время явления.
2. В таблице используются только общепринятые сокращения.
3. В таблице должны быть приведены единицы измерения. Если единица измерения общая, она выносится справа над таблицей в скобках.
4. Цифровые данные целесообразно сокращать.
5. К таблице можно делать примечания, которые располагают под таблицей со сноской под чертой.
6. При переносе таблицы на другой лист, графы таблицы целесообразно обозначать арабскими цифрами.
Тема 3. Графическое изображение статистических данных
Графиками в статистике называют условные изображения числовых величин и их соотношений в виде различных геометрических фигур в системе прямоугольных координат.
Графики являются средством обобщения и анализа статистических данных. С помощью графиков выявляются основные тенденции развития экономических явлений и взаимные связи между явлениями.
Статистические графики различают по содержанию и способу построения.
По содержанию изображаемых статистических показателей графики делят на следующие виды: 1) графики сравнения; 2) графики структуры; 3) графики динамики; 4) графики выполнения плана; 5) графики взаимосвязанных показателей.
По способу построения различают столбиковые, ленточные, линейные, круговые, квадратные, секторные диаграммы.
Для построения графиков сравнения целесообразно использовать линейную, столбиковую, ленточную, квадратную, круговую диаграммы.
Столбиковая диаграмма изображается в виде столбиков, основания которых откладываются на оси абсцисс, высота - на оси ординат. Ширина столбиков произвольная, но одинаковая.
Линейная диаграмма изображается в виде линии, соединяющей точки пересечения расчетных величин в ряде динамики.
Ленточную диаграмму целесообразно строить в том случае, если объект характеризуется двумя показателями, как правило, противоположными по смыслу. В ленточной диаграмме в отличие от столбиковой столбики расположены не вертикально, а горизонтально в системе прямоугольных координат.
Квадратную диаграмму целесообразно строить в том случае, когда между сравниваемыми показателями разница настолько велика, что установление подходящего масштаба оказывается затруднительным. Сторона каждого квадрата определяется как корень квадратный из соответствующей величины. Тогда площадь квадратов визуально будет характеризовать ту или иную исходную величину.
Круговые диаграммы строятся аналогично квадратам. Радиус круга есть корень квадратный из определенной величины.
Для построения графиков структуры, как правило, используют столбиковые и секторные диаграммы.
Особенностью построения секторной диаграммы является то, что объем круга в секторной диаграмме принимается за 100 процентов, а величины секторов пропорциональны процентному отношению составных частой к их общему итогу.
Построение графиков динамики осуществляется, как правило, с помощью столбиковой или линейной диаграмм.
Графическое изображение показателей выполнения плана можно осуществить в виде линейной, ленточной и столбиковой диаграмм в системе прямоугольных координат. При этом на оси абсцисс откладывают периоды динамики, на оси ординат - показатели выполнения плана.
Для графического изображения показателей выполнения плана часто используют числовые сетки с двумя сопряженными шкалами. Одна шкала характеризует выполнение плана в абсолютных величинах, другая - в относительных величинах (проценты выполнения плана). Числовые сетки используют для характеристики выполнения планового задания за период динамики либо в разрезе цехов и участков.
Построение графиков взаимосвязанных показателей, один из которых равен произведению двух других, можно осуществлять с помощью так называемых "знаков Варзара". "3нак" строится вне системы прямоугольных координат в виде прямоугольника, основание которого пропорционально одному показателю - сомножителю, высота - другому.
При построении графиков (диаграмм) в системе прямоугольных координат необходимо придерживаться следующих правил:
1. Каждый график должен иметь название, которое располагают под ним. В названии в краткой форме следует отразить содержание, место и время явления. Все графики нумеруются.
2. Оси координат должны быть названы и иметь единицы измерения.
3. На числовой оси следует откладывать только целые числа и в равном масштабе (например: 20; 40; 60 и т.д., или 1500; 3000; 4500 и т.д.). Заканчиваться числовая ось должна той величиной, которая немногим больше максимальной величины в исходной совокупности.
4. Если на одной числовой оси необходимо расположить величины, относящиеся к одному и тому же явлению, но резко отличающиеся друг от друга по абсолютному значению, числовую ось можно разорвать знаком (≈), что означает разрыв масштаба.
5. Если необходимо отразить на одном графике (в одной системе прямоугольных координат) два-три явления, то вводят столько же дополнительных числовых осей (осей ординат). Каждая числовая ось должна иметь свою размерность и свой масштаб.
Тема 4. Абсолютные и относительные статистические величины
Под абсолютными величинами в статистике понимают показатели, которые характеризуют размеры (уровни, объемы) изучаемых экономических явлений.
Абсолютные величины являются исходной базой статистического анализа.
В отличие от абсолютных величин относительные величины являются величинами производными и рассчитываются на основе абсолютных.
В статистическом анализе используют следующие виды относительных величин: величины динамики, величины выполнения плана, величины структуры, величины координации, величины интенсивности, величины сравнения.
При изучении относительных величин динамики необходимо, прежде всего, уяснить их роль в характеристике развития явления во времени. Следует обратить внимание на характер базы сравнения (постоянная, переменная).
Приведем пример расчета относительных величин динамики (табл. 4.1).
Таблица 4.1
Выпуск товарной продукции на предприятии
| Месяц | Тыс. руб. | Относительная величина динамики с постоянной базой сравнения | Относительная величина динамики с переменной базой сравнения | ||
| в коэффициентах | в процентах | в коэффициентах | в процентах | ||
| Январь | 1390,7 | 1,000 | 100,0 | – | – |
| Февраль | 1426,9 | 1,026 | 102,6 | 1,026 | 102,6 |
| Март | 1492,6 | 1,073 | 107,3 | 1,046 | 104,6 |
| Апрель | 1547,5 | 1,113 | 111,3 | 1,037 | 103,7 |
Вычислим относительные величины динамики с постоянной базой сравнения, приняв за базу январь: 1426,9 : 1390,7 = 1,026 ´ 100 = 102,6%; 1492,6 : 1390,7 = 1,073 ´ 100 = 107,3% и т.д.
Вычислим относительные величины динамики с переменной базой сравнения, используя соотношения каждого последующего месяца к предыдущему: 1426,9 : 1390,7 = 1,026; 1492,6 : 1426,9 = 1,046 ´ 100 = 104,6% и т.д.
При вычислении относительных величин структуры следует уяснить их связь с группировкой статистических данных.
Приведем пример расчета (табл. 4.2).
Таблица 4.2
Распределение рабочих по тарифным разрядам
| Тарифный разряд | Число рабочих в цехе | |
| человек | в процентах к итогу | |
| 1 | 3 | 1,5 |
| 2 | 12 | 6,1 |
| 3 | 63 | 32,0 |
| 4 | 68 | 34,5 |
| 5 | 34 | 17,3 |
| 6 | 17 | 8,6 |
| Итого: | 197 | 100,0 |
Для характеристики структуры рабочих по тарифным разрядам (в процентах) определяют удельный вес численности рабочих по соответствующим разрядам в общей численности рабочих. Так, удельный вес численности рабочих 1 разряда составляет (3 : 197) ´ 100 = 1,5% и т.д. (см. табл. 4.2).
При вычислении относительных величин координации за базу сравнения принимается какая-либо одна часть изучаемого явления, а остальные части соотносятся с ней.
Для примера воспользуемся данными табл. 4.2. Если
взять за базу сравнения численность рабочих 2 разряда, тогда относительные величины
координации составят: ![]() = 0,25;
= 0,25; ![]() = 5,3;
= 5,3; ![]() = 5,7;
= 5,7; ![]() = 2,8;
= 2,8; ![]() = 1,4, т.е. на каждого
рабочего 2 разряда приходится в 4 раза меньше рабочих 1 разряда, 5 рабочих 3
разряда; 6 рабочих 4 разряда и т.д.
= 1,4, т.е. на каждого
рабочего 2 разряда приходится в 4 раза меньше рабочих 1 разряда, 5 рабочих 3
разряда; 6 рабочих 4 разряда и т.д.
При вычислении относительных величин интенсивности необходимо помнить, что они являются именованными показателями: так, коэффициент фондоотдачи показывает, какой объем продукции приходится на единицу стоимости основных производственных фондов; показатель производительности труда характеризует величину объема продукции в расчете на единицу трудовых затрат и т.д.
При вычислении относительных величин сравнения нужно запомнить, что сравнению между собой подвергаются одноименные величины, относящиеся к разным объектам, взятые, как правило, за один и тот же период времени. Например, соотношение выпуска продукции на двух предприятиях в отчетном периоде составило 102%.
Тема 5. Средние величины
Средние величины в статистике выполняют роль обобщающих показателей, характеризующих изучаемую совокупность единиц по какому-либо признаку.
В статистике используют различные виды средних величин: средняя арифметическая простая, средняя арифметическая взвешенная; средняя гармоническая, средняя геометрическая; структурные средние - мода и медиана.
При изучении данной темы особое внимание следует обратить на то, что каждый вид средней величины определяется в зависимости от конкретного экономического условия и от поставленной задачи. В противном случае средняя величина даст ошибочный результат и будет являться искаженной характеристикой изучаемой статистической совокупности.
Средняя величина рассчитывается по качественно однородной совокупности, значения которой примерно одного порядка.
Это - основное условие применения средней.
Нельзя забывать о том, что средние величины в статистике являются величинами именованными и выражаются в тех же единицах, в которых выражен признак.
Необходимо также уяснить значение средних моды и медианы, с помощью которых изучают структуру исследуемой совокупности.
Проиллюстрируем на конкретных примерах порядок расчета каждого вида средних величин.
1. Распределение рабочих-наладчиков участка одного из цехов промышленного предприятия по стажу работы и квалификационным разрядам характеризуется следующими данными:
Таблица 5.1
Данные о составе рабочих
| Стаж работы, лет | Число рабочих, чел. | |||
| Всего | в том числе имеющих разряд | |||
| 4 | 5 | 6 | ||
| До 10 | 9 | 2 | 4 | 3 |
| 10-20 | 7 | – | 2 | 5 |
| 20-30 | 3 | – | 1 | 2 |
| 30-40 | 2 | – | – | 2 |
Определить: а) средний разряд рабочих каждой возрастной группы; б) средний стаж рабочих участка.
Решение:
а) Для нахождения среднего разряда рабочих каждой возрастной группы следует применить среднюю арифметическую взвешенную:
![]() ;
;
в качестве веса (m) выступает конкретный разряд рабочих. Так, для рабочих со стажем работы до 10 лет средний тарифный разряд составит:
![]() =
= ![]() =
=
![]() = 5 разряд.
= 5 разряд.
И так далее по другим возрастным группам.
б) Для нахождения среднего стажа рабочих на участке применяют ту же среднюю арифметическую взвешенную, но уже для интервального ряда распределения.
Причем, в качестве "x" будут срединные значения признака в группах, а в качестве веса (m) принимают численность рабочих соответствующей группы:
![]() =
= 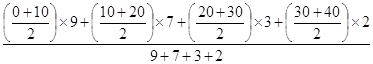 =
=
![]() = 14 лет.
= 14 лет.
2. По следующим данным распределения рабочих цеха по проценту выполнения месячного задания определить моду и медиану.
Таблица 5.2
Данные о выполнении производственного задания
| Выполнение месячного задания, процент | Число рабочих, чел. | Накопленные частоты от начала ряд |
| 95-100 | 3 | 3 |
| 100-105 | 20 | 23 |
| 105-110 | 10 | 33 |
| 110-115 | 5 | 38 |
| 115-120 | 4 | 42 |
| Итого | 42 | – |
Модой в статистике называют наиболее часто встречающееся в исследуемой совокупности значение признака. Следовательно, в данной задаче модальным будет интервал от 100 до 105 процентов, так как на него приходится наибольшее число рабочих (20 чел.).
Моду определяют по формуле:
Mo = x0 + ![]() ∙
(x1 – x0),
∙
(x1 – x0),
где x0 и x1 - соответственно нижняя и верхняя границы модального интервала;
m2 - частота модального интервала;
m1 и m3 - частоты интервала, соответственно, предыдущего и следующего за модальным.
Подставим значения в формулу:
Mo =
100 + ![]() ´ (105 – 100) = 103,1%.
´ (105 – 100) = 103,1%.
Иначе говоря, наибольшее число рабочих выполняют месячное задание на 103,1%.
Медианой в статистике называют срединное значение признака в исследуемой совокупности. Следовательно, медианным является интервал, на который приходится 50% накопленных частот данного ряда, что по условию задачи 42 : 2 = 21.
В нашей задаче медиана находится в интервале от 100 до 105% , так как на данный интервал приходится накопленная частота 23.
Медиану определяют по формуле:
Me = x0 + ![]() ∙
(x1 – x0),
∙
(x1 – x0),
где x0 и x1 - соответственно нижняя и верхняя границы медианного интервала;
N - сумма частот ряда;
N0 - сумма частот, накопившаяся до начала медианного интервала;
N1 - частота медианного интервала.
Подставим соответствующее значение в формулу:
Me =
100 + ![]() ´ 5 = 104,5%.
´ 5 = 104,5%.
Таким образом, 50% всех рабочих выполняют производственное задание менее чем на 104,5%; 50% - более чем на 104,5%.
Тема 6. Ряды динамики
Рядами динамики называют ряды, которые характеризуют изменение явления во времени. Ряды динамики бывают моментные и интервальные. Моментные ряды характеризуют изменение явления в динамике на определенный момент времени (чаще - на начало или конец периода). Интервальные ряды характеризуют изменение явления в динамике за определенный период времени (месяц, квартал, год).
В экономическом анализе используют аналитические показатели динамики. К ним относят абсолютный прирост, средний абсолютный прирост, темп роста, темп прироста, средний темп роста, абсолютное значение одного процента прироста. Данные показатели широко используются в статистической практике, что вызывает необходимость тщательного изучения порядка их расчета.
Рассмотрим на примере расчет аналитических показателей ряда динамики (табл. 6.1).
Таблица 6.1
Данные о производстве в цехе
| Месяц | Выпуск цехом товарной продукции, тыс. руб. | Показатели динамики | |||||
| Абсолютный прирост (D), тыс. руб. |
Темп роста (Тр) |
Темп прироста (Тпр) |
Абсолютное значение 1% прироста (А), тыс. руб. | ||||
| Цепной | Базисный | Цепной | Базисный | ||||
| 1 | 236 | – | – | 100,0 | – | – | – |
| 2 | 244 | 8 | 103,4 | 103,4 | 3,4 | 3,4 | 2,4 |
| 3 | 246 | 2 | 100,8 | 104,2 | 0,8 | 4,2 | 2,5 |
| 4 | 249 | 3 | 101,2 | 105,5 | 1.2 | 5,5 | 2,5 |
| 5 | 250 | 1 | 100,4 | 105,9 | 0,4 | 5,9 | 2,5 |
| 6 | 252 | 2 | 100,8 | 106,8 | 0,8 | 6,8 | 2,5 |
Абсолютный прирост (D) определяется как разность между отчетным и предыдущим уровнями ряда динамики, т.е. по формуле:
D = yi – yi–1,
где yi, yi–1 - уровни ряда динамики.
Так, например, абсолютный прирост продукции цеха в феврале по сравнению c январем составил: 244 – 236 = 8 тыс. руб., а в марте по сравнению с февралем: 246 – 244 = 2 тыс. руб. и т.д.
Средний абсолютный прирост (![]() ) определяется на основе
данных абсолютных приростов по следующей формуле:
) определяется на основе
данных абсолютных приростов по следующей формуле:
![]() или
или
![]() ,
,
где n - число уровней ряда динамики;
y1 и yn - соответственно первый и последний уровни ряда динамики.
Темп роста (Тр) определяется по формуле:
Тр = ![]() ´ 100%,
´ 100%,
где y0 - уровень ряда динамики, взятый за базу сравнения.
Темп роста рассчитывается по принципу цепных и базисных соотношений. В том числе, когда за базу сравнения принимается предыдущий период - это цепные показатели темпа роста, когда сравнение осуществляется с любым другим уровнем ряда динамики, взятым за базу сравнения - базисные темпы роста.
Так, в феврале по сравнению с январем выпуск продукции в цехе составил: Тр2 = (244 : 236) ´ 100% = 103,4%, а в марте по сравнению с февралем: Тр3 = (246 : 244) ´ 100% = 100,8% и т.д.
Если за базу сравнения взять январь, то выпуск продукции в цехе в марте по сравнению с январем составил: (246 : 236) ´ 100% = 104,2%, а в апреле по сравнению с январем: (249 : 236) ´ 100% = 105,5% и т.д.
Темп прироста (Тпр) в отличие от темпа роста характеризует относительный прирост явления в отчетном периоде по сравнению с тем уровнем, с которым осуществляется сравнение и определяется:
Тпр = Тр – 100.
Так, в марте объем продукции цеха по сравнению с февралем увеличился на 0,8% (100,8 – 100), а по сражению с январем - на 4,2% (104,2 – 100) и т.д.
Абсолютное значение одного процента прироста (А) характеризует абсолютный эквивалент одного процента прироста и определяется по формуле:
А = ![]() .
.
Так, в марте абсолютное значение одного процента прироста составило: (2 : 0,8) = 2,4 млн. руб. и т.д.
Средний темп роста (![]() )
за период динамики определяют по формуле средней геометрической двояким
способом - на основе данных цепных коэффициентов динамики, либо на основе
данных абсолютных уровней ряда динамики по формуле:
)
за период динамики определяют по формуле средней геометрической двояким
способом - на основе данных цепных коэффициентов динамики, либо на основе
данных абсолютных уровней ряда динамики по формуле:
![]() ∙100
∙100
или
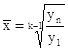 ∙100,
∙100,
где x1, x2, …, xn - коэффициенты динамики по отношению к предыдущему периоду;
n - число коэффициентов динамики;
k - число абсолютных уровней ряда динамики.
Так, за первое полугодие средний годовой темп роста
продукции в цехе составил: ![]() =
= ![]() =
= ![]() = 1,014 ´ 100 = 101,4% или
= 1,014 ´ 100 = 101,4% или ![]() =
=
![]() =
= ![]() = 1,014 ´ 100 = 101,4%.
= 1,014 ´ 100 = 101,4%.
Один из важнейших вопросов, возникающих при изучении рядов динамики - это выявление тенденции развития экономической закономерности в динамике. Для этой цели применяются разнообразные статистические методы, в частности, метод укрупнения интервалов, метод скользящей средней, метод аналитического выравнивания.
Наиболее простым в использовании является метод укрупнения интервалов, основанный на укрупнении периодов времени, к которым относятся уровни ряда. Выявление тенденции осуществляется по новому укрупненному ряду динамики.
Другой метод - метод скользящей средней заключается в замене первоначальных уровней ряда динамики средними арифметическими, найденными по способу скольжения, начиная с первого уровня ряда с постепенным включением последующих уровней.
Наиболее совершенным методом выявления тенденции ряда динамики является метод аналитического выравнивания, который заключается в замене первоначальных уровней ряда новыми, найденными во времени "t" построением аналитического уравнения связи.
Рассмотрим на примере возможности применения каждого из методов выравнивания при выявлении тенденции ряда динамики.
Известны следующие данные выполнения программы участком "молдинги" цеха ЗИЛ-130 прессового корпуса за 1989 г. (табл.6.2).
Таблица 6.2
| Месяц | Выполнение программы, млн. руб. | t |
t2 |
ty |
|
| I | 18,6 | -6 | 36 | -111,6 | 18,1 |
| II | 17,3 | -5 | 25 | -86,5 | 18,2 |
| III | 18,9 | -4 | 16 | -75,6 | 18,3 |
| IV | 18,2 | -3 | 9 | -54,6 | 18,3 |
| V | 17,9 | -2 | 4 | -35,8 | 18,4 |
| VI | 19,1 | -1 | 1 | -19,1 | 18,5 |
| VII | 19,6 | 1 | 1 | 19,6 | 19,2 |
| VIII | 17,5 | 2 | 4 | 35,0 | 19,1 |
| IX | 19,2 | 3 | 9 | 57,6 | 19,0 |
| X | 19,8 | 4 | 16 | 79,2 | 18,9 |
| XI | 18,3 | 5 | 25 | 91,5 | 18,8 |
| XII | 19,4 | 6 | 36 | 116,4 | 18,7 |
| Итого: | 223,8 | 0 | 182 | 16,1 | 223,5 |
1. По методу укрупнения интервалов имеем новые укрупненные поквартально уровни ряда динамики:
у1 = 18,6 + 17,3 + 18,9 = 54,8;
y2 = 18,2 + 17,9 + 19,1 = 55,2 и т.д.
Выровненный ряд динамики примет вид: 54,8 55,2 56,3 57,5.
То есть наблюдается четно выраженная тенденция увеличения выпуска молдингов цехом за 1989 г.
2. Употребляя те же данные, применим метод скользящей средней, используя семичленную скользящую среднюю. Тогда:
![]() =
=
![]() = 18,5;
= 18,5;
![]() =
=
![]() = 18,4 и т.д.
= 18,4 и т.д.
Выравненный с помощью семичленной скользящей средней ряд динамики примет вид: 18,5 18,4 18,6 18,7 18,8 19,0.
Таким образом, подтверждается тенденция увеличения выпуска молдингов в течение 1989 г.
3. Используя метод отсчета от условного нуля введем условное обозначение времени "t", придав ему определенные значения так, чтобы ∑t = 0 (см. табл. 6.2).
Судя по выявленной с помощью двух предыдущих методов
тенденции выпуска молдингов в течение года, можно сказать, что наиболее вероятна
линейная зависимость данного распределения от времени "t"
и данному распределению соответствует уравнение прямой ![]() =
a0 + a1t.
=
a0 + a1t.
Для нахождения параметров a0 и a1 используем систему уравнений
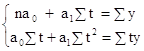 ,
,
так как ∑t = 0, о имеем
a0 = ![]() =
=
![]() = 18,6;
= 18,6;
a1 = ![]() =
=
![]() = 0,09.
= 0,09.
Следовательно, уравнение прямой примет вид:
![]() = 18,6 + 0,09t и будет в
данном случае искомым, так как ∑y = ∑
= 18,6 + 0,09t и будет в
данном случае искомым, так как ∑y = ∑![]() .
.
Тема 7. Показатели вариации
Наряду со средней величиной, характеризующей типичный уровень варьирующего признака, около которого колеблются отдельные значения признака, рассматривают показатели вариации (колеблемости) признака, позволяющие количественно измерить величину этой колеблемости.
К показателям вариации относят: размах вариации, среднее линейное отклонение, дисперсию, среднее квадратическое отклонение, коэффициент вариации.
Простейшим показателем вариации является размах вариации, который рассчитывается по следующей формуле:
R = Xmax – Xmin,
где Xmax, Xmin - соответственно, максимальное и минимальное значения признака в исследуемой совокупности.
Размах вариации характеризует диапазон колебаний признака в изучаемой совокупности и измеряется в тех же единицах, в которых выражен признак.
Рассчитывают среднее линейное отклонение, которое бывает невзвешенное и взвешенное. Если каждое значение признака встречается в совокупности один раз, то применяется формула среднего линейного отклонения невзвешенного:
![]() ,
,
где x - значение признака;
n - количество вариант.
Если имеется некоторая повторяемость значений признака, то применяется формула среднего линейного отклонения взвешенного:
![]() ,
,
где m - частота.
Среднее линейное отклонение характеризует абсолютный размер колеблемости признака около средней и измеряется в тех же единицах, в которых выражен признак.
Наиболее точным показателем вариации является среднее квадратическое отклонение. Для его определения предварительно рассчитывают показатель дисперсии. Дисперсия невзвешенная определяется по формуле:
σ2 =![]() .
.
Дисперсия взвешенная определяется по формуле:
σ2 =![]() .
.
Тогда, соответственно, для расчета среднего квадратического отклонения невзвешенного используют формулу:
σ =![]() ,
,
а для расчета среднего квадратического отклонения взвешенного - следующую формулу:
σ =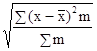 .
.
Как и среднее линейное отклонение, среднее квадратическое отклонение характеризует абсолютный размер колеблемости признака около средней, однако является более точной характеристикой.
В отличие от среднего линейного и среднего квадратического отклонения коэффициент вариации является мерой относительной колеблемости признака около средней и характеризует степень однородности признака в изучаемой совокупности. Он определяется по формуле:
υσ = ![]() ´ 100%.
´ 100%.
Если исследуемую совокупность единиц расчленить на группы, то вправе считать, что общая дисперсия всей совокупности варьирует (изменяется) под влиянием дисперсий для каждой отдельной группы, так называемых групповых или частных дисперсий и межгрупповой дисперсии. Эти дисперсии связаны между собой правилом сложения дисперсий. При использовании правила сложения дисперсий в экономическом анализе по величине частной дисперсии может решаться задача выявления наиболее эффективной в производстве системы (формы, структуры и т.п.) организации труда, его оплаты и т.п.
Частные или групповые дисперсии характеризуют колеблемость изучаемого признака в каждой отдельной группе и определяются по следующей формуле:
![]()
и их средняя величина
![]() ,
,
где i = 1, 2, …, n - номер группы;
mi - численность единиц в группе.
Межгрупповая дисперсия характеризует колеблемость частных
средних около общей средней ![]() и
определяется следующим образом:
и
определяется следующим образом:
γ2 =![]() .
.
При соблюдении правила сложения дисперсий должно соблюдаться равенство:
σ2 = ![]() +
γ2.
+
γ2.
Проиллюстрируем расчет показателей вариации по данным о распределении рабочих по стажу работы (табл. 7.1).
1. R = Xmax – Xmin = 14 – 10 = 4 года, т.е. диапазон колебания стажа рабочих в исследуемой совокупности составляет 4 года.
2. ![]() =
= ![]() = 11,4 года
= 11,4 года
![]() =
=
![]() = 1,1 года.
= 1,1 года.
Таблице 7.1
Стаж работы рабочих
| Стаж работы рабочего, лет (x) | Число рабочих, чел. (m) | x∙m |
x – |
| x – |
(x – |
(x – |
| 10 | 14 | 140 | -1,4 | 19,6 | 1,96 | 27,44 |
| 11 | 11 | 121 | -0,4 | 4,4 | 0,16 | 1,76 |
| 12 | 8 | 96 | 0,6 | 4,8 | 0,36 | 2,88 |
| 13 | 6 | 78 | 1,6 | 9,6 | 2,56 | 15,36 |
| 14 | 4 | 56 | 2,6 | 10,4 | 6,76 | 24,04 |
| Итого | 43 | 491 | – | 48,8 | 11,80 | 74,48 |
В среднем на 1,1 года отклоняется стаж отдельных рабочих от среднего стажа по совокупности.
3. σ2 =![]() =
=
![]() = 1,73;
= 1,73;
σ =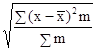 =
= ![]() = 1,3 года.
= 1,3 года.
Величина σ = 1,3 года характеризует колеблемость стажа работы рабочих в данной совокупности:
υσ = ![]() ´ 100 =
´ 100 = ![]() ´ 100 = 11,4%.
´ 100 = 11,4%.
Таким образом, на 11,4% варьирует состав рабочих по стажу работы в исследуемой совокупности.
Тема 8. Индексы
В статистике индексами называют относительные величины, показывающие соотношение показателей во времени, пространстве, а также фактических показателей с плановыми.
Индексы измеряются в процентах.
Для некоторых простых, единичных явлений, которые допускают непосредственное сравнение, строят индивидуальные индексы. Дня явлений сложных, состоящих из непосредственно несоизмеримых элементов, строят сводные индексы. Так, для характеристики динамики производства конкретного вида продукции, применяется индивидуальный индекс. Если же исследователя интересует динамика выпуска всей продукции предприятия, то в этом случае строится сводный индекс, так как отдельные виды продукции предприятия непосредственно несоизмеримы.
Разработанная статистикой теория индексов позволяет решить следующие задачи:
1) определять соотношение показателей во времени, пространстве, фактических данных с плановыми;
2) выявлять абсолютные результаты измерения показателей в аналогичных направлениях;
3) определять относительное и абсолютное влияние отдельных факторов на такое изменение при условии, что факторы представлены в виде произведения.
В теории индексов наиболее часто используются следующие обозначения: I - индивидуальный индекс; J - сводный индекс.
Порядок построения индивидуальных индексов весьма прост: в числителе дроби записывается показатель на уровне отчетного периода, в знаменателе - на уровне базисного периода. Например:
Ip = ![]() ;
It =
;
It = ![]() ;
Iq =
;
Iq = ![]() и
т.д.,
и
т.д.,
где Ip - индивидуальный индекс цен;
It - индивидуальный индекс трудоемкости;
Iq - индивидуальный индекс продукции;
p1 и p0 - цена единицы продукции, соответственно, в отчетном и базисном периодах, руб.;
t1 и t0 - трудоемкость изготовления единицы продукции, соответственно, в отчетном и базисном периодах, ч;
q1 и q0 - количество произведенной продукции, соответственно, в отчетном и базисном периодах, шт.
Существуют цепные и базисные индивидуальные индексы. В цепных индексах каждый последующий период сравнивается с предыдущим, например:
![]() ;
;
![]() ;
; ![]() и
т.д.
и
т.д.
Нетрудно заметить, что перемножение цепных индексов дает в итоге сравнение явлений, разделенных рядом промежутков времени (базисные индексы):
![]() =
=
![]() ´
´ ![]() ´
´ ![]() .
.
Естественно, если в задаче известен базисный индекс и какие-то из цепных, то для нахождения других цепных индексов необходимо производить деление.
Следует знать, что индексы динамики, планового задания и выполнения плана связаны между собой известным из теории относительных величин соотношением:
Iдинамики = Iпл. задания ´ Iвыполнения плана.
Если в задаче требуется найти абсолютное изменение какого-то явления, то оно определяется как разница между числителем и знаменателем индекса:
(p1 – p0); (t1 – t0) и т.д.
Если при этом ставится задача определить, как влияет это изменение на какое-то многофакторное явление, то найденная разность между числителем и знаменателем качественного индекса (цен, трудоемкости и т.п.) умножается на соответствующий количественный фактор (количество продукции, численность работающих и т.п.) на уровне отчетного периода. Разность между числителем и знаменателем количественного индекса (продукции, численности работающих и т.п.) умножается на соответствующий качественный фактор (трудоемкость и т.п.) на уровне базисного периода:
(p1 – p0)q1 - размер экономии (перерасхода) денежных средств от снижения (повышения) цен;
(t1 – t0)q1 - размер увеличения (уменьшения) затрат труда на производство продукции от повышения (снижения) трудоемкости;
(q1 – q0)p0 - размер экономии (перерасхода) денежных средств от изменения объема выпуска продукции;
(q1 – q0)t0 - размер увеличения (уменьшения) затрат труда на производство продукции от изменения объема выпуска продукции и т.д.
В отличие от индивидуальных индексов, сводные индексы представляют собой результат сравнения сложных явлений, состоящих из непосредственно несоизмеримых элементов.
Сводные индексы представляют собой соотношение сумм произведений индексируемых величин и их соизмерителей. В качестве соизмерителей могут выступать: трудоемкость изготовления продукции (t), цена единицы продукции (p), себестоимость единицы продукции (z). Название сводного индекса определяется изменяющимся (индексируемым) показателем. Индексируемый показатель записывают в числителе на уровне отчетного периода, в знаменателе - на уровне базисного периода или на уровне планового задания. Если индексируется качественный показатель (цена, трудоемкость, себестоимость), то соответствующий ему количественный соизмеритель фиксируется на уровне отчетного периода. Если индексируется количественный показатель, то соответствующий ему качественный соизмеритель фиксируется на уровне базисного периода или на уровне планового задания. Исходя из этого, сводный индекс цен запишется:
Jp =![]() ;
;
сводный индекс трудоемкости: Jt =![]() ;
;
сводный индекс себестоимости: Jz =![]() ;
;
сводный индекс физического объема продукции:
Jq =![]() (при наличии соизмерителя p);
(при наличии соизмерителя p);
Jq =![]() (при наличии соизмерителя t);
(при наличии соизмерителя t);
Jq =![]() (при наличии соизмерителя z).
(при наличии соизмерителя z).
Индексы цен, трудоемкости и себестоимости продукции
относятся к индексам постоянного состава, так как q = const. Индексы
физического объема продукции независимо от соизмерителя относятся к индексам
структурных сдвигов, так как учитывается изменение в ассортименте и объеме
продукции. В том случае, когда в сводном индексе индексируется сам показатель и
его соизмеритель, оба составляющих в числителе записываются на уровне отчетного
периода, в знаменателе - на уровне базисного периода, а название сводного
индекса определяется индексируемыми составляющими. Так, сводный индекс объема
продукции в стоимостном выражении запишется Jqp =![]() ; индекс затрат труда на производство продукции Jqt =
; индекс затрат труда на производство продукции Jqt =![]() ;
индекс денежных затрат на производство продукции Jqz =
;
индекс денежных затрат на производство продукции Jqz =![]() .
.
Такие индексы относятся к индексам переменного состава, так как варьируют оба составляющих.
В статистическом анализе используется взаимосвязь индексов переменного состава и структурных сдвигов, которая проявляется в виде двух свойств индексов.
Первое свойство индексов: индекс переменного состава равен произведению индексов постоянного состава и структурных сдвигов:
Jqp = Jq ∙
Jp; ![]() =
=
![]() ;
;
Jqt = Jq ∙
Jt; ![]() =
=
![]() ;
;
Jqz = Jq ∙
Jz; ![]() =
=
![]() .
.
Второе свойство индексов: разность числителя и знаменателя индекса переменного состава равна сумме разностей числителя и знаменателя индексов постоянного состава и структурных сдвигов:
Dqp(qp) = Dqp(q) + Dqp(p); ∑q1p1 – ∑q0p0 = (∑q1p0 – ∑q0p0) + (∑q1p1 – ∑q1p0);
Dqt(qt) = Dqt(q) + Dqt(t); ∑q1t1 – ∑q0t0 = (∑q1t0 – ∑q0t0) + (∑q1t1 – ∑q1t0);
Dqz(qz) = Dqz(q) + Dqz(z); ∑q1z1 – ∑q0z0 = (∑q1z0 – ∑q0z0) + (∑q1z1 – ∑q1z0).
Рассмотрим пример:
По одному из подразделений промышленного предприятия известны следующие данные (табл. 8.1).
Таблица 8.1
| Вид продукции | Количество произведенной продукции, тыс. шт. | Цена 1 шт., руб. | ||
| Базисный период | Отчетный период | Базисный период | Отчетный период | |
| А | 15 | 20 | 0,8 | 0,7 |
| Б | 1,5 | 2 | 2,0 | 1,5 |
| В | 5 | 10 | 1,0 | 0,8 |
Рассчитаем индивидуальные индексы продукции и индивидуальные индексы цен.
Индивидуальные индексы по соответствующим видам продукции составят:
Iq(А) = ![]() =
= ![]() ´ 100 = 133,3%;
´ 100 = 133,3%;
Iq(Б) = ![]() =
= ![]() ´ 100 = 133,3%;
´ 100 = 133,3%;
Iq(В) = ![]() =
= ![]() ´ 100 = 200%.
´ 100 = 200%.
То есть в отчетном периоде по сравнению с базисным произведено продукции вида "А" и "Б", соответственно, на 33,3% больше, а вида "В" - на 100% больше.
Индивидуальные индексы цен по соответствующим видам продукции составят:
Ip(А) = ![]() =
= ![]() ´ 100 = 87,5%;
´ 100 = 87,5%;
Ip(Б) = ![]() =
= ![]() ´ 100 = 75,0%;
´ 100 = 75,0%;
Ip(В) = ![]() =
= ![]() ´ 100 = 80,0%.
´ 100 = 80,0%.
То есть цена единицы продукции вида "А" в отчетном периоде по сравнению с базисным снизилась на 12,5% (100 – 87,5), вида "Б" - на 25% (100 – 75) и вида "В" - на 20% (100 – 80).
Индивидуальные индексы конкретного вида продукции в стоимостном выражении, соответственно, составят:
Ip(А) = ![]() =
= ![]() ´ 100 =
´ 100 = ![]() ´ 100 = 116,7%;
´ 100 = 116,7%;
Ip(Б) = ![]() =
= ![]() ´ 100 =
´ 100 = ![]() ´ 100 = 100%;
´ 100 = 100%;
Ip(В) = ![]() =
= ![]() ´ 100 =
´ 100 = ![]() ´ 100 = 160%.
´ 100 = 160%.
Таким образом, объем продукции в стоимостном выражении вида "А" в отчетном периоде по сравнению с базисным увеличится на 16,7% (116,7 – 100), вида "В" - на 60% (160 – 100) и вида "Б" - останется без изменения (100 – 100).
Для того, чтобы ответить на вопрос, как уменьшился объем всей продукции предприятия в отчетном периоде по сравнению с базисным, необходимо рассчитать сводные индексы продукции, цен и физического объема продукции.
Сводный индекс объема продукции в стоимостном выражении составит:
Jqp = ![]() =
=
![]() ´ 100 =
´ 100 = ![]() ´ 100 = 125%;
´ 100 = 125%;
Сводный индекс цен составит:
Jp = ![]() =
= ![]() ´ 100 =
´ 100 = ![]() ´ 100 = 83,3%;
´ 100 = 83,3%;
Сводный индекс физического объема продукции составит:
Jq = ![]() =
= ![]() ´ 100 =
´ 100 = ![]() ´ 100 = 150%.
´ 100 = 150%.
Используя первое свойство индексов, имеем:
Jqp = Jq ∙ Jp; 125% = 1,5 ´ 0,833 ´ 100%.
Используя второе свойство индексов, имеем:
Dqp(qp) = Dqp(q) + Dqp(p), т.е. (25 – 20) = (30 – 20) + (25 – 30) или (+5) = (+10) + (-5).
Таким образом, можно сделать вывод: объём продукции в стоимостном выражении увеличился в целом на 25%, или на 5´(25 – 20) тыс. руб., в том числе за счет снижения цен на 16,7% (83,3 – 100) объем снизился на 5 тыс. руб. (25 – 30), а за счет увеличения физического объема продукции на 50% (150 – 100) объем продукции в стоимостном выражении увеличился на 10 тыс. руб.
Тема 9. Взаимосвязи явлений
Первый этап изучения связи явлений - выделение основных причинно-следственных связей и отделение их от второстепенных. Второй этап - построение модели. Последний этап - интерпретация результатов.
Признаки-аргументы называются факторами, а признаки-функции - результатами (результативными признаками).
Связи между явлениями делят по степени тесноты связи (полная или функциональная связь, неполная или статистическая связь), по направлению (прямая, обратная), по аналитическому выражению (линейная, нелинейная).
Для выявления связи, ее характера, направления используют методы приведения параллельных данных, балансовый, аналитических группировок, графический. Суть метода приведения параллельных данных: приводят два ряда данных о двух признаках, связь между которыми хотят выявить, и по характеру изменений делают заключение о наличии связи. Балансовый метод заключается в построении балансов - таблиц, где итог одной части равен итогу другой.
Методы аналитических группировок и графический изложены в соответствующих темах.
Удобная форма изложения данных - корреляционная таблица (табл. 9.1).
Таблица 9.1
Корреляционная таблица
| Часовая выработка ткани, м | Количество станков, обслуживаемых одной работницей, шт. | |||||||
| 5-7 | 7-9 | 9-11 | 11-13 | 13-15 | 15-17 | 17-19 | Итого | |
| 10 - 15 | 7 | 4 | 2 | 1 | 14 | |||
| 15 - 20 | 3 | 8 | 5 | 4 | 20 | |||
| 20 - 25 | 2 | 11 | 8 | 2 | 23 | |||
| 25 - 30 | 5 | 13 | 7 | 1 | 26 | |||
| 30 - 35 | 1 | 16 | 3 | 20 | ||||
| 35 - 40 | 2 | 6 | 19 | 3 | 30 | |||
| 40 - 45 | 3 | 7 | 18 | 28 | ||||
| Итого: | 10 | 14 | 21 | 30 | 33 | 32 | 21 | 161 |
Таблица показывает, что частоты концентрируются у диагонали, идущей из левого верхнего угла в правый нижний. Это указывает на то, что связь между количеством обслуживаемых работницей станков и ее часовой выработкой ткани прямая (с увеличением числа обслуживаемых станков увеличивается выработка) или близкая к прямой (концентрация частот идет почти по прямой линии).
По данным таблицы можно рассчитать среднюю выработку
по каждой из семи групп работниц, выделенных по числу обслуживаемых станков.
Обозначив эти средние значения через ![]() и
произведя расчеты, получаем:
и
произведя расчеты, получаем: ![]() = 14,0;
= 14,0; ![]() = 16,79;
= 16,79; ![]() = 22,51;
= 22,51; ![]() = 24,67;
= 24,67; ![]() = 32,65;
= 32,65; ![]() = 36,88;
= 36,88; ![]() = 41,79.
= 41,79.
Данные таблицы и результаты расчетов можно изобразить
графически с помощью поля корреляции. Ломаная линия на графике (линия значений ![]() ) называется эмпирической
линией регрессии.
) называется эмпирической
линией регрессии.
Показатели тесноты связи. Для оценки тесноты связи применяется ряд показателей, одни из которых называются эмпирическими или непараметрическими, другие (выводимые строго математически) - теоретическими.
Коэффициент знаков (коэффициент Фехнера) вычисляется на основании определения знаков отклонений вариантов двух взаимосвязанных признаков от их средних величин.
Если число совпадений знаков обозначать через a, число несовпадений - через b, а сам коэффициент - через i , то можно записать формулу этого коэффициента так:
![]() .
.
Коэффициент корреляции рангов (коэффициент Спирмена) рассчитывается не по значениям двух взаимосвязанных признаков, а по их рангам следующим образом:
ρx/y = 1 – ![]() ,
,
где di - разности рангов; n - число пар рангов.
Для определения тесноты связи между тремя и более признаками применяется ранговый коэффициент согласия - коэффициент конкордации, который вычисляется по формуле:
w = ![]() ,
,
где m - количество факторов;
n - число наблюдений;
S - сумма квадратов отклонений рангов.
Величина коэффициента конкордации более 0,5 показывает, что между исследуемыми величинами имеется тесная зависимость.
Если при определении тесноты связи с помощью приведенных ранговых коэффициентов имеются связные ранги, т.е. если двум или более показателям присвоен один и тот же ранг, то расчеты проводятся по формулам:
коэффициент Спирмена: ρx/y = 1 – 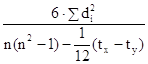 ;
;
коэффициент конкордации: w = ![]() ,
,
где T = ![]() (t3 – t), а t - количество связных рангов по отдельным показателям.
(t3 – t), а t - количество связных рангов по отдельным показателям.
При исследовании социальных явлений и процессов большое значение имеет изучение качественных показателей и признаков, не имеющих количественной оценки:
| a | b | a + b |
| c | d | c + d |
| a + c | b + d | a + b + c + d |
Для определения тесноты связи двух качественных признаков, каждый из которых состоит только из двух групп, применяются коэффициенты ассоциации и контингенции. Для их вычисления строится таблица, которая показывает связь между двумя явлениями, каждое из которых должно быть альтернативным, т.е. состоящим из двух качественно отличных друг от друга значений признака (например, хороший, плохой).
Коэффициенты вычисляются по формулам:
A = ![]() -
ассоциации;
-
ассоциации;
K = ![]() - контингенции.
- контингенции.
Коэффициент контингенции всегда меньше коэффициента ассоциации. Связь считается подтвержденной, если A ³ 0,5, или K ³ 0,3.
Если каждый из качественных признаков состоит более чем из двух групп, то для определения тесноты связи возможно применение коэффициента взаимной сопряженности Пирсона. Этот коэффициент вычисляется по формуле:
C = 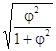 ,
,
где j2 - показатель взаимной сопряженности.
Расчет коэффициента взаимной сопряженности проводится по следующей схеме:
| Группа признака A | Группа признака В | Итого | ||
|
B1 |
B2 |
B3 |
||
|
A1 |
f1 |
f2 |
f3 |
n1 |
|
A2 |
f4 |
f5 |
f6 |
n2 |
|
A3 |
f7 |
f8 |
f9 |
n3 |
|
m1 |
m2 |
m3 |
||
Расчет j2 проводится так:
по первой строке 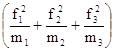 :
n1 = L1;
:
n1 = L1;
по второй строке 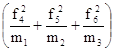 :
n2 = L2;
:
n2 = L2;
по третьей строке 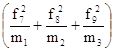 :
n3 = L3;
:
n3 = L3;
Следовательно, j2 = L1 + L2 + L3 – 1.
Интерпретация непараметрических коэффициентов связи в некоторых случаях, особенно когда они имеют отрицательное значение, затруднительна. Их абсолютные значения могут изменяться в пределах от 0 до 1. Чем ближе абсолютные значения к единице, тем теснее связь между исследуемыми признаками.
Корреляция и регрессия. Традиционные методы корреляционно-регрессионного анализа позволяют не только оценить тесноту связи, но и выразить эту связь аналитически. Применению корреляционно-регрессионного анализа должен предшествовать качественный, теоретический анализ исследуемого социально-экономического явления или процесса.
Связь между двумя факторами аналитически выражается уравнениями:
прямой ![]() = a0
+ a1x;
= a0
+ a1x;
гиперболы ![]() = a0
+
= a0
+ ![]() ;
;
параболы ![]() = a0 + a1x + a2x2 (или
другой ее степени);
= a0 + a1x + a2x2 (или
другой ее степени);
степенной функции ![]() .
.
Параметр a0 показывает усредненное влияние на результативный признак неучтенных (не выделенных для исследования) факторов. Параметр a1 - коэффициент регрессии показывает, на сколько изменяется в среднем значение результативного признака при увеличении факторного на единицу. На основе этого параметра вычисляются коэффициенты эластичности, которые показывают изменение результативного признака в процентах в зависимости от изменения факторного признака на 1%:
Э = a1∙![]() .
.
Для определения параметров уравнений используется метод наименьших квадратов, на основании которого строится соответствующая система уравнений.
Теснота связи при линейной зависимости измеряется с помощью линейного коэффициента корреляции:
r = ![]() ,
,
а при криволинейной зависимости с помощью корреляционного отношения:
h = ![]() .
.
Расчет коэффициентов регрессии несколько осложняется, если ряды по исследуемым факторам сгруппированы, а связь криволинейная.
Если зависимость между двумя факторами выражается уравнением гиперболы
![]() =
a0 +
=
a0 + ![]() ,
,
то система уравнений для определения параметров a0 и a1 такова:
na0 + a1∑![]() = ∑y;
= ∑y;
a0∑![]() +
a1∑
+
a1∑![]() = ∑y
= ∑y![]() .
.
Для определения параметров уравнения регрессии,
выраженного степенной функцией ![]() , приводят
функцию к линейному виду: lg
, приводят
функцию к линейному виду: lg![]() =
lga0 + a1lgx,
отсюда система уравнений для определения параметров запишется:
=
lga0 + a1lgx,
отсюда система уравнений для определения параметров запишется:
n∙lga0 + a1∑lgx = ∑lgy;
lga0∑lgx + a1∑(lgx)2 = ∑lgy∙lgx.
Зависимость между тремя и более факторами называется множественной или многофакторной корреляционной зависимостью. Линейная связь между тремя факторами выражается уравнением:
![]() =
a0 + a1x + a2z,
=
a0 + a1x + a2z,
а система нормальных уравнений для определения неизвестных параметров a0, a1, a2 будет следующей:
na0 + a1∑x + a2∑z = ∑y;
a0∑x + a1∑x2 + a2∑zx = ∑yx;
a0∑z + a1∑xz + a2∑z2 = ∑yz.
Теснота связи между тремя факторами измеряется с помощью множественного (совокупного) коэффициента корреляции:
R = 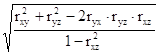 ,
,
где rij - парные коэффициенты корреляции между соответствующими факторами.
Для более углубленного анализа вычисляются частные коэффициенты корреляции.
Дисперсионный анализ связи. При небольшом числе наблюдений исследовать влияние одного или нескольких факторных признаков на результативный можно, используя методы дисперсионного анализа. Дисперсионный анализ проводится расчетом дисперсий: общей, межгрупповой и внутригрупповой. Общую дисперсию называют дисперсией комплекса, межгрупповую - факторной, внутригрупповую - остаточной.
Дисперсионный анализ заключается в сравнении факторной и остаточной дисперсий. Если различие между ними значимо, то факторный признак, т.е. признак, положенный в основание группировки, оказывает существенное влияние на результативный. При исследовании воздействия на результативный признак только одного факторного, т.е. однофакторного комплекса дисперсии вычисляются:
дисперсия комплекса ![]() ;
;
факторная дисперсия ![]() ;
;
остаточная дисперсия ![]() ,
,
где n – 1, r – 1, n – r - соответствующие числа степеней свободы;
r - число уровней (групп).
На основании дисперсий проводится расчет критерия Фишера Fp. Если расчетное значение больше табличного, т.е. Fp > Fa, то существенность влияния факторного признака подтверждается.
Тема 10. Выборочное наблюдение
Главными вопросами теории выборочного наблюдения, требующими практического закрепления на основе решения задач и выполнения упражнений, являются:
- определение предела случайной ошибки репрезентативности для различных типов выборочных характеристик с учетом особенностей отбора;
- определение объема выборки, обеспечивающего необходимую репрезентативность выборочной характеристики, с учетом особенностей отбора.
Ошибка репрезентативности, или разность между выборочной и генеральной характеристикой (средней, долей), возникающая в силу несплошного наблюдения, в основе которого лежит случайный отбор, рассчитывается как предел наивероятной ошибки. В качестве уровня гарантийной вероятности обычно берется 0,954 или 0,997. Тогда предел ошибки определяется величиной удвоенной или утроенной средней ошибки выборки: D = 2m при P = 0,954; D = 3m при P = 0,997, или в общем виде D = tm (t - коэффициент, связанный с вероятностью, гарантирующей результат).
Величина средней ошибки выборки различна для отдельных разновидностей случайного отбора. При наиболее простой системе - собственно-случайном повторном отборе - средняя ошибка определяется следующими формулами:
индивидуальный отбор:
m = ![]() =
=
![]() ,
,
где σ2 - общая дисперсия признака;
n - число отобранных единиц наблюдения;
групповой (гнездовой, серийный) отбор:
m = ![]() =
=
![]() ,
,
где δ2 - межгрупповая дисперсия;
r - число отобранных групп (гнезд, серий) единиц наблюдения.
При практических расчетах ошибок репрезентативности необходимо учитывать следующее:
1. Вместо генеральной дисперсии используется соответствующая выборочная дисперсия. Так, вместо общей дисперсии доли в генеральной совокупности берется общая дисперсия частости:
![]() = w(1 – w) вместо
= w(1 – w) вместо ![]() =
pq.
=
pq.
2. В случае бесповторного способа отбора (а также механического) следует иметь в виду поправки (K) к ошибке повторной выборки на бесповторность отбора:
K = ![]() < 1 или K =
< 1 или K = ![]() < 1.
< 1.
Очевидно, что пользоваться этой поправкой целесообразно лишь тогда, когда относительный объем выборки составляет заметную часть генеральной совокупности (не менее 10%, тогда K £ 0,95).
3. При районированном отборе из типических групп единиц генеральной совокупности используется средняя из частных (групповых) дисперсий. Так, при индивидуальном отборе, пропорциональном размерам типических групп, имеем:
D = 2m = ![]() =
= ![]() при P = 0,954,
при P = 0,954,
где ![]() - частная
дисперсия i-й группы;
- частная
дисперсия i-й группы;
ni - объем выборки в i-й группе.
Определение ошибок выборочных характеристик позволяет установить наивероятные границы нахождения соответствующих генеральных показателей:
для средней: ![]() ,
,
где ![]() -
генеральная средняя;
-
генеральная средняя;
![]() -
выборочная средняя;
-
выборочная средняя;
![]() -
ошибка выборочной средней;
-
ошибка выборочной средней;
для доли: p = w ± Dw,
где p - генеральная доля;
w - выборочная доля (частость);
Dw - ошибка выборочной доли.
Пример. С вероятностью 0,954 нужно определить границы среднего веса пачки чая для всей партии, поступившей в торговую сеть, если контрольная выборочная проверка дала следующие результаты (первые две графы табл. 10.1).
Таблица 10.1
Результаты взвешивания чая
| Вес, г (x) | Количество пачек (m) | Расчетные графы | |||
| x¢ | m¢ | x¢m¢ |
(x¢)2m¢ |
||
| 48 - 49 | 20 | -1 | 2 | -2 | 2 |
| 49 - 50 | 50 | 0 | 5 | 0 | 0 |
| 50 - 51 | 20 | +1 | 2 | 2 | 2 |
| 51 - 52 | 10 | +2 | 1 | 2 | 4 |
| Итого: | 100 | – | 10 | 2 | 8 |
1. Средний вес пачки чая по выборке:
![]() =
=
![]() ´ K + x0 =
´ K + x0 = ![]() ´ 1 + 49,5 =
49,7 г.
´ 1 + 49,5 =
49,7 г.
2. Выборочная дисперсия веса пачки чая:
σ2 = 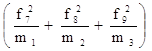 =
=
![]() = 0,76.
= 0,76.
3. Средняя ошибка выборочной средней:
![]() =
=
![]() =
= ![]() =
0,087 г.
=
0,087 г.
4. Предел для ошибки с вероятностью 0,954:
D = 2m = 0,174 г » 0,2 г.
5. Границы генеральной средней:
![]() =
=
![]() ± D = 49,7 ± 0,2 г.
± D = 49,7 ± 0,2 г.
Таким образом, с вероятностью 0,954 можно утверждать, что вес пачки чая в среднем для всей партии не более 49,9 г и не менее 49,5 г.
Определение объема выборки при заданной ее точности является проблемой, обратной рассмотренной нами - определению ошибки выборки при данном ее объеме. Формула объема выборки получается из соответствующей формулы предельной ошибки. Так, получаем для индивидуального бесповторного отбора:
n =![]() ;
;
группового бесповторного отбора:
r =![]() .
.
При решении задач на определение необходимого объема выборки следует иметь в виду, что вместо генеральной дисперсии определенного вида берется ее оценка - примерное значение, полученное из того или иного источника. Рассмотрим следующий общий пример.
Пример. Нужно определить абсолютный и относительный объемы индивидуального отбора для исследования генеральной доли, чтобы ошибка частости с вероятностью 0,954 не превышала 0,02, если выборка производится из генеральной совокупности объема: а) 1000; б) 100000 единиц.
Используя формулу n =![]() , в которой полагаем t = 2 (гарантийная вероятность
равна 0,954), а pq = 0,25, имеем:
, в которой полагаем t = 2 (гарантийная вероятность
равна 0,954), а pq = 0,25, имеем:
а) n = ![]() = 714,
или 71,4%;
= 714,
или 71,4%;
б) n = ![]() = 2439,
или 2,44%.
= 2439,
или 2,44%.
Тема 11. Законы распределения
Конечной целью обработки информации методами математической статистика, если речь идет о больших выборках, является получение закона распределения исследуемой случайной величины. Это связано с тем, что закон распределения является фактически, тем аппаратом, который позволяет определить вероятность появления (или, наоборот, непоявления) случайной величины в тот или иной период времени или вероятность того, что случайная величина попадет в тот или иной интервал ее возможных значении. Этот этап статистической обработки является одним из наиболее важных, так как ошибка при выборе того или иного закона распределения приводит к ошибкам при дальнейшем решении практических задач.
Если проанализировать все этапы статистической обработки, то можно сделать вывод, что влекущими за собой наиболее существенные ошибки, а, следовательно, наиболее ответственными, являются этапы, на которых решаются следующие задачи:
1. Возможно ли объединение нескольких малых или средних выборок в одну.
2. Отбрасывать или учитывать резко отличающиеся результаты.
3. Справедливо ли сделанное предположение о законе распределения случайной величины.
Рассмотрим эти этапы более подробно.
1. Так как для установления закона распределения необходимы большие выборки, то на практике часто встает вопрос об объединении нескольких выборок, каждая из которых мала для решения поставленной задачи и получения одной общей выборки, удовлетворяющей предъявленным к ней требованиям. Поэтому, что вообще свойственно для статистической обработки, любое из неправильных решений (как положительное, так и отрицательное) по поводу объединения выборок приводит к нежелательным результатам, или к невозможности установить закон распределения, если выборки не объединяются, или к неправильному выводу о характере закона распределения.
Для решения этой задачи используют критерии, с помощью которых с разной формулировкой фактически дается ответ на один и тот же вопрос: принадлежат или не принадлежат исследуемые выборки одной генеральной совокупности, то есть автоматически решается задача о возможности или невозможности их объединения. Как правило, все эти критерии основаны на сравнении выборочных характеристик (выборочных дисперсий или средних величин) между собой или с соответствующими генеральными характеристиками. В большинстве случаев использование этих критериев предполагает нормальный или логарифмически-нормальный закон распределения для каждой выборки. При других же законах распределения эти критерии некорректны и их использование может привести к ошибочным результатам.
Наиболее используемыми являются следующие критерии:
а) критерии, основанные на сравнении дисперсий:
критерий ![]() , критерий Фишера (F =
, критерий Фишера (F = ![]() ), критерий Хартлея (Fmax
=
), критерий Хартлея (Fmax
= ![]() ), критерий Кочрена (Gmax
=
), критерий Кочрена (Gmax
= ![]() ), критерий Бартлета (χ2);
), критерий Бартлета (χ2);
б) критерии, основанные на сравнениях средних величин: критерий Стьюдента (t), критерий Z и другие.
Для всех критериев в качестве нулевой гипотезы (H0) выдвигается предположение о принадлежности выборки генеральной совокупности или об однородности выборок между собой.
2. При наличии выборки, удовлетворяющей требованиям относительно ее пригодности для установления закона распределения перед тем, как приступить к определению статистических характеристик, необходимо проверить, принадлежат ли к данной выборке ее члены, резко отличающиеся от большинства данных, если таковые имеются. Такая проверка строго обязательна, так как любое неверное решение в отношении резко отличающихся результатов приводит к искажению вида кривой закона распределения и к последующим ошибкам, о которых уже говорилось выше. Описанная проверка также осуществляется с помощью соответствующих критериев: критерия Груббса (для малых выборок), критерия Ирвина и некоторых других. В качестве нулевой гипотезы во всех случаях принимается предположение о том, что резко выделяющиеся результаты принадлежат данной выборке.
3. Заключительной и самой трудоемкой проверкой является проверка гипотез о виде функции распределения или, что то же, о соответствии предполагаемого закона теоретического распределения эмпирическому. Эта проверка осуществляется с помощью так называемых критериев согласия. Существуют критерии для проверки соответствия как предполагаемому нормальному или логарифмически-нормальному закону распределения, так и любому другому закону распределения.
Наиболее используемыми при практических расчетах являются следующие критерии:
а) критерий Пирсона (χ2); он справедлив при больших объемах выборок и для любых законов распределения;
б) критерий Колмогорова-Смирнова (Du); этот критерий используется для проверки гипотезы о соответствии эмпирического распределения любому теоретическому закону распределения с заранее известными параметрами, что накладывает ограничения на его использование. В то же время Du является более мощным, чем критерий χ2;
в) критерий Крамера-Мизеса (w2); данный критерий используется для объемов выборок 50 £ n £ 200 и является более мощным, чем χ2, однако, при его применении требуется больший объем вычислений. Поэтому при n > 200 этот критерий целесообразно использовать только в тех случаях, когда проверки гипотезы по другим критериям не приводят к безусловным результатам;
г) критерий Шапиро-Уилкса (W); он предназначен для проверки гипотезы о нормальном или логарифмически нормальном законе распределения при ограниченном объеме выборки (n £ 50) и является более мощным, чем другие критерии.
Укрупненно порядок проведения статистической обработки информации можно представить следующим образом: после решения вопроса об объеме выборки и принадлежности к ней резко отличающихся результатов, строится гистограмма, рассчитываются статистические характеристики исследуемой случайной величины, и устанавливается закон ее распределения.
При решении технических и экономических задач существует достаточно широкий круг законов распределения, которым подчиняются те или иные процессы. К ним относятся законы Вейбулла, Релея, экспоненциальный, гамма-распределения, однако, самыми распространенными являются нормальный (Гаусса) и логарифмически-нормальный законы распределения. Получив математическое выражение закона распределения, то есть соотношение, устанавливающее связь между возможными значениями случайной величины и соответствующими им вероятностями, можно утверждать, что с вероятностной точки зрения, случайная величина описана полностью.