
Рефераты по геополитике
Рефераты по государству и праву
Рефераты по гражданскому праву и процессу
Рефераты по делопроизводству
Рефераты по кредитованию
Рефераты по естествознанию
Рефераты по истории техники
Рефераты по журналистике
Рефераты по зоологии
Рефераты по инвестициям
Рефераты по информатике
Исторические личности
Рефераты по кибернетике
Рефераты по коммуникации и связи
Рефераты по косметологии
Рефераты по криминалистике
Рефераты по криминологии
Рефераты по науке и технике
Рефераты по кулинарии
Рефераты по культурологии
Рефераты по зарубежной литературе
Рефераты по логике
Рефераты по логистике
Рефераты по маркетингу
Рефераты по международному публичному праву
Рефераты по международному частному праву
Рефераты по международным отношениям
Рефераты по культуре и искусству
Рефераты по менеджменту
Рефераты по металлургии
Рефераты по муниципальному праву
Рефераты по налогообложению
Рефераты по оккультизму и уфологии
Рефераты по педагогике
Рефераты по политологии
Рефераты по праву
Биографии
Рефераты по предпринимательству
Рефераты по психологии
Рефераты по радиоэлектронике
Рефераты по риторике
Рефераты по социологии
Рефераты по статистике
Рефераты по страхованию
Рефераты по строительству
Рефераты по схемотехнике
Рефераты по таможенной системе
Сочинения по литературе и русскому языку
Рефераты по теории государства и права
Рефераты по теории организации
Рефераты по теплотехнике
Рефераты по технологии
Рефераты по товароведению
Рефераты по транспорту
Рефераты по трудовому праву
Рефераты по туризму
Рефераты по уголовному праву и процессу
Рефераты по управлению
Реферат: Серьёзные лекции по высшей экономической математике
Реферат: Серьёзные лекции по высшей экономической математике
Комбинаторные задачи.
1.Сколькими способами колода в 52 карты может быть роздана 13-ти игрокам так, чтобы каждый игрок получил по одной карте каждой масти? L
2. Сколькими способами можно расставить 10 книг на полке так, чтобы две определённые книги не стояли рядом? Чтобы три, четыре определенные книги не стояли рядом?
3. Сколькими различными способами можно рассадить за круглым столом 10 гостей? Один способ отличается от другого, если у кого-то из гостей меняется хотя бы один сосед.
4. Имеется пять кусков материи разных цветов. Сколько различных флагов можно скроить из этих кусков, если каждый флаг состоит из трёх горизонтальных полос разного цвета?
5. Каждая из n различных коммерческих организаций намеревается принять на работу одного из n выпускников коммерческого отделения факультета МЭО. В каждой из этих организаций выпускнику предлагается на выбор одна из k должностей. Сколько существует вариантов распределения этих n выпускников на работу?
5. Сколько можно составить различных семизначных телефонных номеров? Сколько будет номеров, у которых все цифры разные?
6. Каждый участник лотереи “6 из 49” должен записать в специальной карточке 6 любых чисел от 1 до 49. При розыгрыше лотереи комиссия случайным образом отбирает 6 чисел из чисел 1,2,,49. Участник, правильно угадавший все 6 чисел, получает большой приз. Участник, угадавший лишь 5 чисел, получает малый приз. Участник, угадавший лишь 4 числа, получает поощрительный приз. Сколькими различными способами можно заполнить карточку, чтобы получить малый приз? Чтобы получить поощрительный приз?
7. У одного человека есть 7 книг, а у другого — 9 книг. Сколькими способами они могут обменять три книги одного на три книги другого?
8. Бригада строителей состоит из 16-ти штукатуров и 4-х маляров. Сколькими способами бригаду можно разделить на две бригады, чтобы в одной из них было 10 штукатуров и 2 маляра, а в другой 6 штукатуров и 2 маляра?
9. Из отряда солдат в 50 человек, среди которых есть два рядовых–однофамильца Ивановы, назначают в караул 4-х человек. Сколькими различными способами может быть составлен караул? В скольких случаях в карауле будут два Ивановых? В скольких случаях в карауле будет один Иванов? Хотя бы один Иванов?
10. Сколькими способами можно разложить 10 книг на 5 бандеролей по две книги в каждой (порядок бандеролей не принимается во внимание)?
11. У Деда Мороза в мешке 10 различных подарков. Сколькими способами эти подарки могут быть розданы 7-ми детям? Решить ту же задачу в предположении, что все подарки одинаковы.
12. Сколькими способами можно разложить 6 одинаковых шаров по трём ящикам, если каждый ящик может вместить все шары?
13. В почтовом отделении продаются открытки 10 сортов. Сколькими способами можно купить в нём 12 открыток?
14. Нужно
провести 4 экзамена
по различным
дисциплинам
в течение
20-ти
дней. Сколько
существует
вариантов
расписания
экзаменов, если
временной
промежуток
между экзаменами
должен быть
не меньше 3-х
дней?
(4!![]() )
)
6
Классическое определение вероятности.
1. Колода из 32-х карт тщательно перетасована. Найти вероятность того, что все четыре туза лежат в колоде один за другим, не перемежаясь другими картами.
Решение.
Число всех
возможных
способов расположения
карт в колоде
равно 32! Чтобы
подсчитать
число благоприятных
исходов, сначала
представим
себе, что четыре
туза располагаются
каким-то образом
один за другим
и склеиваются
между собой
так, что они,
как бы составляют
одну карту
(неважно, что
она оказалась
толще, чем все
остальные). В
полученной
колоде стало
32 – 4 + 1 = 29 карт. Карты
в этой колоде
можно расположить
числом способов,
равным 29! Количество
всех благоприятных
исходов получается,
если это число
умножить на
4! – число возможных
способов упорядочения
четырёх тузов.
Отсюда получаем
ответ задачи:
![]() .
.
2. Между двумя игроками проводится n партий, причем каждая партия кончается или выигрышем, или проигрышем, и всевозможные исходы партий равновероятны. Найти вероятность того, что определённый игрок выиграет ровно m партий, 0 m n.
Решение.
Каждая партия
имеет два исхода
– выигрыш одного
или другого
участника. Для
двух партий
имеется 22
= 4 исходов, для
трёх партий
– 23 =8
исходов, для
n
партий – 2n
исходов. Среди
них ровно
![]() исходов соответствуют
выигрышу одного
из игроков m
партий. Таким
образом, искомая
вероятность
равна
исходов соответствуют
выигрышу одного
из игроков m
партий. Таким
образом, искомая
вероятность
равна
![]() .
.
3. Бросается n игральных костей. Найти вероятность того, что на всех костях выпало одинаковое количество очков.
Решение.
Общее число
исходов здесь
равно 6n.
Число благоприятных
исходов – 6. Ответ
задачи:
![]() .
.
4. В урне a белых и b чёрных шаров (a 2; b 2). Из урны без возвращения извлекаются 2 шара. Найти вероятность того, что шары одного цвета.
Решение.
Эта вероятность
равна
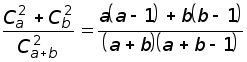
5. В урне находятся a белых и b черных шаров. Шары без возвращения извлекаются из урны. Найти вероятность того, что k-й вынутый шар оказался белым.
Решение. Представим процесс случайного извлечения шаров из урны следующим образом: шары произвольным образом размещены по расположенным в ряд ячейкам, и извлекаются из ячеек один за другим слева направо. Тогда благоприятный исход наступает в том случае, когда в k-й ячейке лежит белый шар.
Всего
возможно (a
+ b)!
различных
способов расположения
шаров по ячейкам.
Займём k-ю
ячейку одним
из белых шаров,
что можно сделать
a
различными
способами.
Тогда остальные
ячейки можно
заполнить (a
+ b
– 1)! способами,
и получается,
что число
благоприятных
исходов равно
(a
+ b
– 1)!a,
а искомая вероятность
–
![]() .
.
6. Найти вероятность того, что при размещении n различимых шаров по N ящикам заданный ящик будет содержать ровно k (0 k n) шаров (все различимые размещения равновероятны).
Решение.
Первый шар
может быть
размещён N
различными
способами,
второй шар –
тоже N
различными
способами, а
два шара могут
быть размещены
по N
ящикам числом
способов, равным
N2.
Всего существует
Nn
вариантов
размещения
n
различимых
шаров по N
ящикам. Выбрав
определенный
ящик, можно
найти
![]() способов заполнить
его набором
k
шаров, выбранных
из множества
n
шаров. Остальные
ящиков можно
заполнить
оставшимися
n – k
шарами числом
способов, равным
(N–1)n–k.
Таким образом
получаем, что
число благоприятных
исходов в задаче
равно
способов заполнить
его набором
k
шаров, выбранных
из множества
n
шаров. Остальные
ящиков можно
заполнить
оставшимися
n – k
шарами числом
способов, равным
(N–1)n–k.
Таким образом
получаем, что
число благоприятных
исходов в задаче
равно
![]() (N–1)n–k,
а интересующая
нас вероятность
равна
(N–1)n–k,
а интересующая
нас вероятность
равна
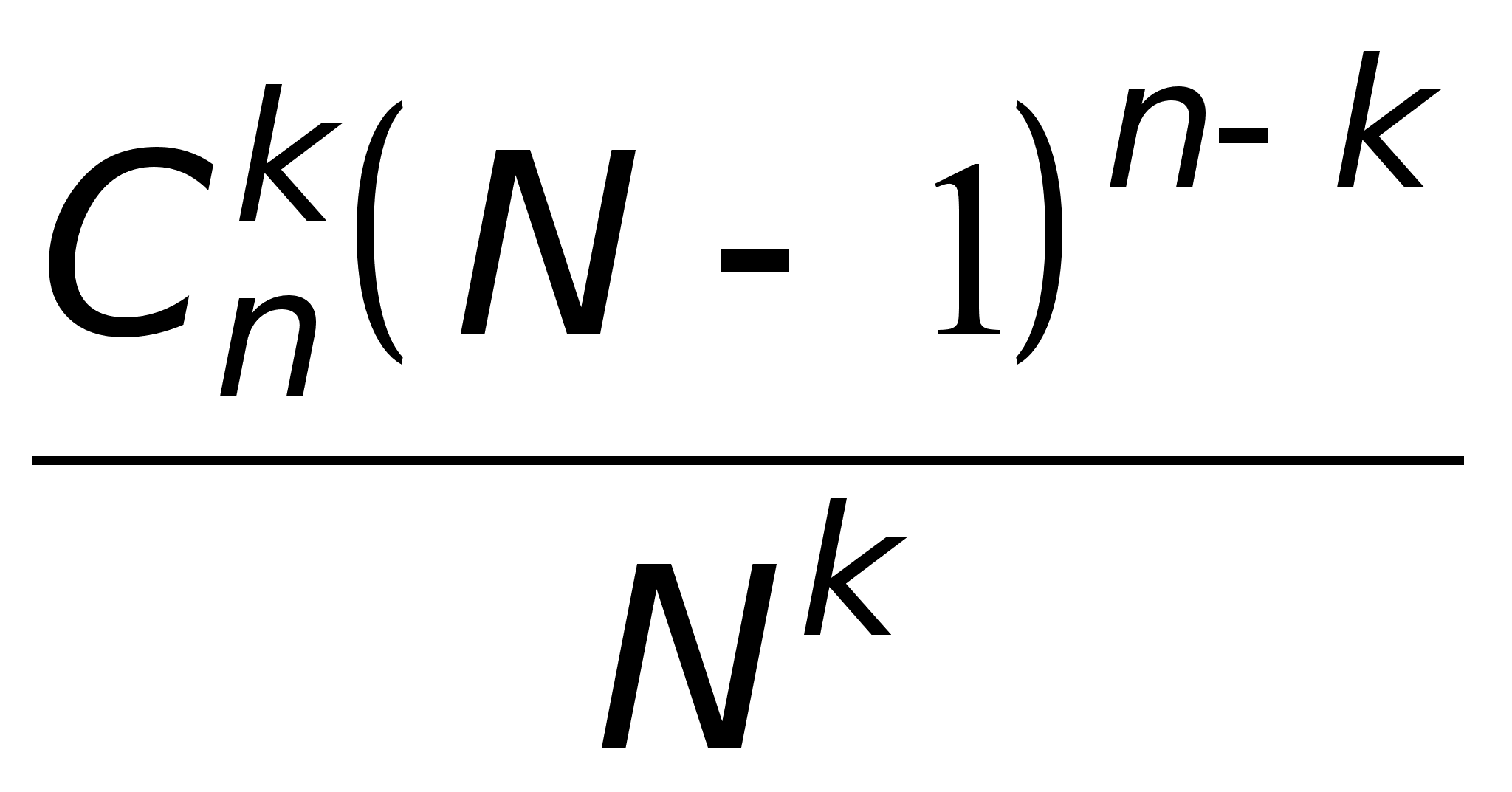 .
.
7. 10 букв разрезной азбуки: А,А,А,Е,И,К,М,М,Т,Т произвольным образом выкладываются в ряд. Какова вероятность того, что получится слово МАТЕМАТИКА?
Решение. 10 букв можно расположить в ряд числом способов, равным 10! Чтобы получить число благоприятных исходов, нужно взять слово МАТЕМАТИКА и убедиться в том, что его можно получить, переставляя местами 3 буквы А, 2 буквы М и 2 буквы Т, что можно сделать 3!2!2! способами Ответ задачи: 3!2!2!/10!.
8. Брошено 10 игральных костей. Предполагается, что все комбинации выпавших очков равновероятны. Найти вероятность того, что выпала хотя бы одна “6”.
Решение.
Общее число
исходов здесь
равно 610.
К благоприятным
исходам следует
отнести выпадение
одной, двух,
трёх и т. д. шестёрок.
Проще подсчитать
число неблагоприятных
исходов, то
есть исходов,
когда не выпало
ни одной шестёрки.
Их, очевидно,
510,
и число благоприятных
исходов равно
610 – 510.
Искомая вероятность
равна 1 – ![]() .
.
9. В мешке находятся 10 различных пар обуви. Из мешка наугад извлекаются 6 единиц обуви. Найти вероятность того, что в выборку не попадёт двух единиц обуви, составляющих одну пару.
Решение.
Общее число
исходов – это
количество
возможных
выборок объёмом
в 6 единиц из
общего числа
в 20 единиц, то
есть
![]() – число сочетаний
из двадцати
по шесть. Подсчитаем
число благоприятных
исходов. Очевидно,
что все возможные
выборки, удовлетворяющие
условию задачи,
можно составить
следующим
образом: выбрать
6 пар обуви, что
осуществляется
числом способов,
равным
– число сочетаний
из двадцати
по шесть. Подсчитаем
число благоприятных
исходов. Очевидно,
что все возможные
выборки, удовлетворяющие
условию задачи,
можно составить
следующим
образом: выбрать
6 пар обуви, что
осуществляется
числом способов,
равным
![]() ,
затем из каждой
пары выбрать
одну единицу.
Из одной пары
это можно сделать
двумя способами,
из двух – четырьмя,
из трёх – восемью
и т. д. Таким образом
можно перебрать
все
,
затем из каждой
пары выбрать
одну единицу.
Из одной пары
это можно сделать
двумя способами,
из двух – четырьмя,
из трёх – восемью
и т. д. Таким образом
можно перебрать
все
![]() шестёрок,
удовлетворяющих
условию задачи.
Искомая вероятность
равна
шестёрок,
удовлетворяющих
условию задачи.
Искомая вероятность
равна
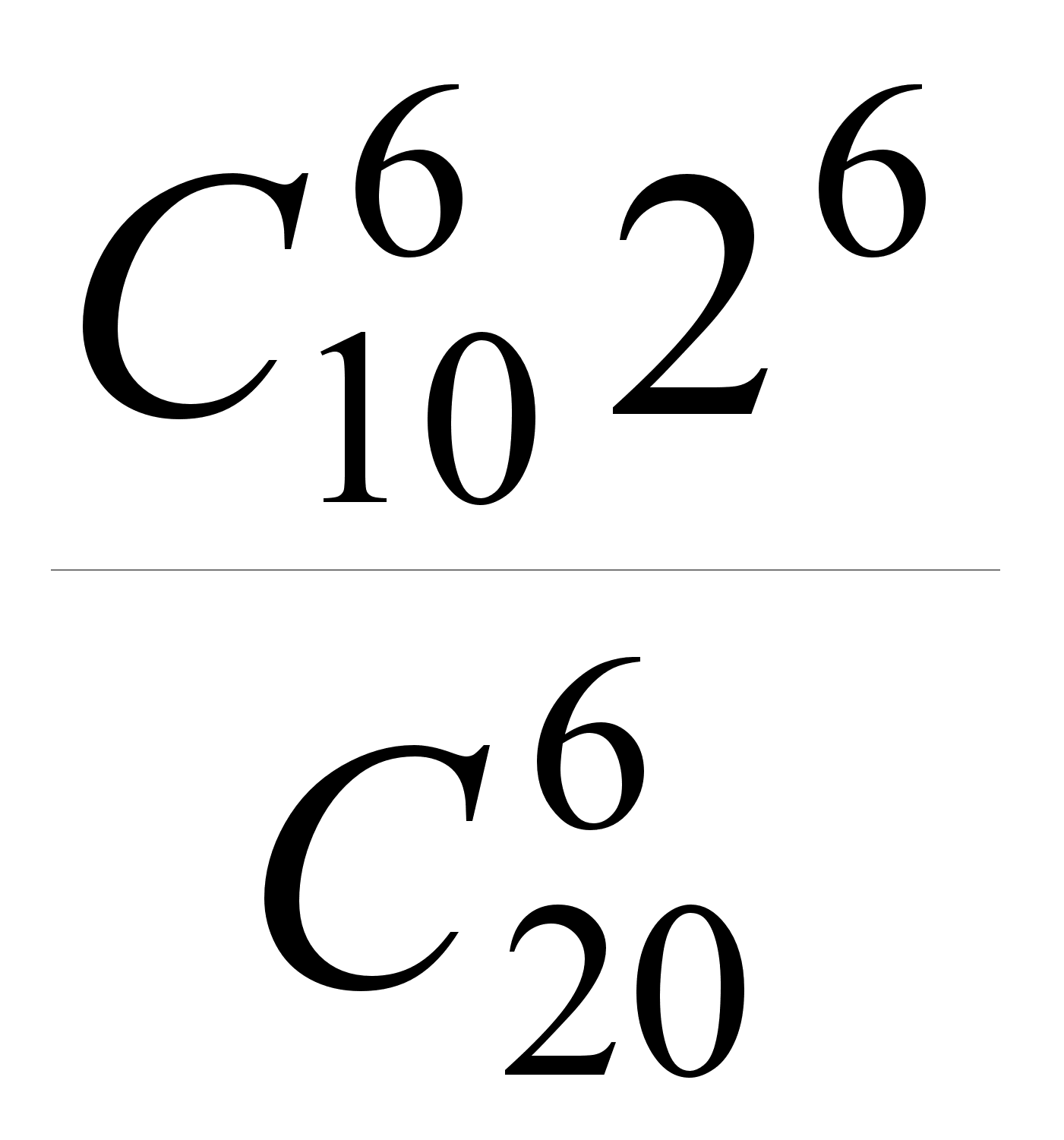 .
.
1.а.
В условиях
задачи 1. подсчитать
вероятность
того, что при
раздаче карт
по одной по
кругу четырём
игрокам каждому
достанется
один туз. (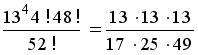 0,1055,
0,1055,
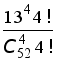 )
)
1.б. В условиях предыдущей задачи подсчитать вероятность того, что все тузы достанутся одному игроку.
1.в. n лиц рассаживаются в ряд в случайном порядке. Какова вероятность, что два определенных лица окажутся рядом? Найти соответствующую вероятность , если те же лица садятся за круглый стол.
2.а. Решите задачу 2. при условии, что каждая партия кончается либо выигрышем одного из участников, либо ничьей, и всевозможные исходы партий равновероятны.
2.б. В лифт 8-этажного дома на первом этаже вошли 5 человек. Предположим, что каждый из них с равной вероятностью может выйти на любом из этажей, начиная со второго. Найти вероятность того, что все пятеро выйдут на разных этажах.
3.а. Брошены шесть игральных костей. Найти вероятность следующих событий:
а) на всех костях выпало разное количество очков;
б) суммарное количество выпавших очков равно 7.
3.б. Найти вероятность того, что среди произвольно выбранных 12-ти человек все имеют дни рождения в разные месяцы.
4.а. В условиях задачи 4. найти вероятность того, что шары разноцветные.
5.а. В кармане лежат 10 ключей, из которых к данному замку подходит лишь один, но неизвестно, какой. Из кармана извлекаются ключи случайным образом один за другим и делается попытка открыть замок. Найти вероятность того, что замок будет открыт с 7-й попытки.
5.б. Студент Иванов при подготовке к экзамену из 30-и билетов выучил лишь 20. Группа сдающих экзамен студентов состоит из 16-и человек, причём каждый по очереди берёт один билет, не возвращая его. В каком случае студент Иванов с большей вероятностью сдаст экзамен: если он будет в этой очереди первым или если он будет последним?
5.в. Партия из 25-и приборов содержит один неисправный прибор. Из этой партии для контроля выбраны случайным образом 6 приборов. Найти вероятность того, что неисправный прибор попал в выборку.
5.г. Ящик содержит 90 годных и 10 дефектных шурупов. Если использовать 10 шурупов, какова вероятность того, что ни один из них не окажется дефектным? Какова вероятность того, что среди них окажется 4 дефектных шурупа?
6.а. В n ящиках размещают n шаров так, что для каждого шара равновозможно попадание в любой ящик. Найти вероятность того, что ни один ящик не пуст.
6.б. Каждая из n палок разламывается на две части – длинную и короткую. Затем 2n обломков объединяются в n пар, каждая из которых образует новую “палку”. Найти вероятность того, что а)части будут соединены в первоначальном порядке; б) все длинные части будут соединены с короткими.
6.в.Для уменьшения общего количества игр 2n команд спортсменов разбиваются на две подгруппы. Определить вероятность того, что две наиболее сильные команды окажутся: а) в разных подгруппах, б) в одной подгруппе. Ответ: а) n/(2n-1); б) (n–1)/(2n-1);
7.а. Из букв разрезной азбуки составлено слово СТАТИСТИКА. Затем из этих букв случайным образом без возвращения отобрано 5 букв. Найти вероятность того, что из отобранных букв можно составить слово ТАКСИ. Ответ 2/21.
8.а. Чему равна вероятность того, что два бросания трёх игральных костей дадут один и тот же результат, если а) кости различимы, б) кости неразличимы. Ответ: 1/216; 83/3888.
8.б. Из 28 костей домино случайным образом выбираются две. Найти вероятность того, что из них можно составить “цепочку” согласно правилам игры. Ответ: 7/18.
8.в. Брошено 10 игральных костей. Найти вероятность событий: а) выпало ровно 3 шестёрки, б) выпало хотя бы две шестёрки.
9.а.
Два игрока
независимым
образом подбрасывают
(каждый свою)
монеты. Найти
вероятность
того, что после
n
подбрасываний
у них будет
одно и то же
число гербов.
Ответ:
![]() .
.
Решение задачи 1.а.
1-й способ. При перетасовке колоды карты в ней можно расположить 32! различными способами. Первый игрок получит туза определённой масти (например, туза пик), если этот туз лежит в колоде на 1-м, 5-м, 9-м и т. д. местах. Иначе говоря, туз пик попадает к первому игроку, если он занимает в колоде одну из восьми возможных позиций. Аналогичным образом другой туз, например масти треф, достаётся второму игроку, если он в колоде лежит вторым, шестым, десятым и т. д., то есть также занимает в колоде одну из восьми возможных позиций. Рассуждая аналогичным образом, получаем, что для выполнения условия задачи карты в колоде должны быть расположены одним из 844!28! возможных способов. Отсюда следует, искомая вероятность равна
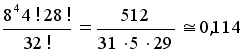
2-й
способ. Разобьём
колоду на 4 части
по 8 карт в каждой.
Это можно сделать
числом способов,
равным
![]() .
Первую из этих
частей при
условии, что
в неё попадает
один и только
один туз, например
туз пик, можно
составить
числом способов,
равным
.
Первую из этих
частей при
условии, что
в неё попадает
один и только
один туз, например
туз пик, можно
составить
числом способов,
равным
![]() .
Вторую часть
при условии
попадания в
неё единственного
туза можно
составить
числом способов,
равным
.
Вторую часть
при условии
попадания в
неё единственного
туза можно
составить
числом способов,
равным
![]() .
Таким образом,
разделить
колоду на 4 части,
удовлетворяющие
условию задачи,
можно числом
способов, равным
.
Таким образом,
разделить
колоду на 4 части,
удовлетворяющие
условию задачи,
можно числом
способов, равным
![]() .
Отсюда следует,
что искомая
вероятность
равна
.
Отсюда следует,
что искомая
вероятность
равна
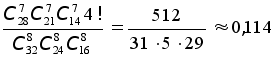
111. При игре в покер из колоды в 52 карты игроку выдаётся 5 карт. Какова вероятность того, что игрок получит комбинацию из одной тройки (три карты одной номинации) и одной двойки (две карты одной номинации). (Такая комбинация называется full house).
112. В условиях предыдущей задачи подсчитать вероятность получения игроком одной двойки, двух двоек.
113. В условиях задачи 111 подсчитать вероятность получения игроком комбинации straight, то есть пяти карт последовательной номинации, но не всех одной масти (например, 5 треф, 6 пик, 7 треф, 8 червей, 9 бубен или валет пик, дама пик, король пик, туз червей, двойка треф)
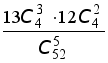 ;
;
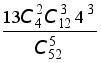 ;
;
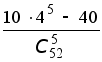 .
.
4
Теоремы сложения и умножения вероятностей. Независимость событий. Условная вероятность.
1. Три стрелка стреляют по одной мишени, и каждый попадает или промахивается независимо от результатов выстрелов других стрелков. Вероятности попадания в мишень для каждого из стрелков, соответственно, равны: 0,8; 0,7; 0,5. Определить вероятности следующих событий:
а) все три стрелка попали в мишень;
б) хотя бы один стрелок попал в мишень;
в) в мишень попали два стрелка.
Решение.
а) Так как здесь рассматриваются независимые события, вероятность попадания в мишень всех трёх стрелков равна произведению вероятностей попадания каждого:
P = 0,80,70,5 = 0,28
б)
Обозначим это
событие А.
Ему благоприятствует
несколько
несовместимых
исходов, например,
такой: {первый
стрелок попал
в мишень, второй
не попал, третий
попал}. Вместо
того, чтобы
рассматривать
все эти исходы,
возьмём событие
![]() – дополнение
события
А
или, иначе, событие,
противоположное
событию А.
Оно состоит
в том, что все
три стрелка
не попали в
мишень.
Его вероятность
равна:
– дополнение
события
А
или, иначе, событие,
противоположное
событию А.
Оно состоит
в том, что все
три стрелка
не попали в
мишень.
Его вероятность
равна:
(1 – 0,8) (1 – 0,7) (1 – 0,5) = 0,5
Теперь можно определить вероятность интересующего нас события:
Р(А)
= 1 – Р(![]() )
= 1 – 0,5 = 0,5
)
= 1 – 0,5 = 0,5
в) Этому событию благоприятствуют три исхода:
* {первый попал, второй попал, третий не попал} – c вероятностью
0,8 0,7 (1 – 0,5) = 0,28
** {первый попал, второй не попал, третий попал} – c вероятностью
0,8 (1 – 0,7) 0,5 = 0,12
*** {первый не попал, второй попал, третий попал} – c вероятностью
(1 – 0,8) 0,7 0,5 = 0,07
Очевидно, что эти исходы несовместимы, и поэтому вероятность их объединения, представляющего собой событие А, равна сумме их вероятностей:
Р(А) = 0,28 + 0,12 + 0,07 = 0,47
2. Брошено три игральных кости. Найти вероятности следующих событий:
а) выпало три шестёрки;
б) выпало три шестёрки, если известно, что на одной из костей выпала шестёрка.
Решение.
а)
Здесь ответ
очевиден:
![]()
б)
Обозначим через
А событие, состоящее
в выпадении
трёх шестёрок,
а через В – в
выпадении
шестёрки хотя
бы на одной
кости. Тогда
Р(А/В) – искомая
вероятность.
Событие АВ
в данном случае
совпадает с
событием А,
откуда следует:
Р(АВ)
=
![]() .
Вероятность
события В
равна разности
единицы и вероятности
события
.
Вероятность
события В
равна разности
единицы и вероятности
события
![]() ,
противоположного
событию В, то
есть выпадения
трёх чисел,
отличных от
шестёрки. Вероятность
,
противоположного
событию В, то
есть выпадения
трёх чисел,
отличных от
шестёрки. Вероятность
![]() равна
равна
![]() .
Отсюда следует:
Р(В) =
.
Отсюда следует:
Р(В) =
![]() .
В результате
получается:
.
В результате
получается:
Р(А/В)
=
![]()
3. Истребитель атакует бомбардировщик, делает один выстрел и сбивает бомбардировщик с вероятностью р1. Если этим выстрелом бомбар–дировщик не сбит, то он стреляет по истребителю и сбивает его с вероятностью р2. Если истребитель этим выстрелом не сбит, то он ещё раз стреляет по бомбардировщику и сбивает его с вероятностью p3. Найти вероятности следующих событий:
а) “сбит бомбардировщик”;
б) “сбит истребитель”;
в) “сбит хотя бы один самолёт”.
Ответ: а) р1 + (1 – p1)(1 – p2)p3; б) (1 – p1)p2; в) p1 + p2 + p3 – p1p2 – p1p2 – p2p3 + p1p2p3.
4. Из 20 студентов, находящихся в аудитории, 8 человек курят, 12 носят очки, а 6 и курят и носят очки. Одного из студентов вызвали к доске. Определим события А и В следующим образом: A = {вызванный студент курит}, B = {вызванный носит очки}.
Установить, зависимы события A и B или нет. Сделать предположение о характере влияния курения на зрение.
Решение.
Так как
![]() , то условие
независимости
не выполняется,
следовательно,
события A и B
зависимы.
, то условие
независимости
не выполняется,
следовательно,
события A и B
зависимы.
Найдем
условную вероятность
того, что студент
носит очки, при
условии, что
он курит:
![]() .
Безусловная
вероятность
того, что студент
носит очки,
равна
.
Безусловная
вероятность
того, что студент
носит очки,
равна
![]() .
Так как
.
Так как
![]() ,
то делаем вывод:
курение способствует
ухудшению
зрения.
,
то делаем вывод:
курение способствует
ухудшению
зрения.
6.Ф. Бросаются три игральных кости. Какова вероятность того, что на одной из них выпадет единица, если на всех трёх костях выпали разные грани? (0.5).
7.Ф. Известно, что при бросании десяти игральных костей выпала хотя бы одна единица. Какова вероятность того, что выпало две или более единиц?
1 – 1059/(610-510).
8. Доказать,
что если события
А и
В независимы,
то независимы
события
![]() и
и
![]() .
.
9. Бросают три монеты. Событие А — выпадение герба на первой и второй монетах. Событие В — выпадение цифры на третьей монете. Найти Р(А∩В) и Р(АUВ).
10. В некоторой корпорации протокол принятия важнейших решений предусматривает следующую процедуру. Предложение направляется в отдел А. В случае одобрения предложение направляется в отделы B и C а также к вице-президенту D. В случае одобрения вице-президентом предложение направляется президенту корпорации P. Сюда предложение попадает и в том случае, если после его одобрения хотя бы одним из отделов B или C его одобрит вице-президент E. Нарисовать схему принятия решения. Считая, что все инстанции принимают решение независимо одна от другой, и что A, D и E одобрят предложение с вероятностью 0,6, а В, C и P — с вероятностью 0,5, определить вероятность принятия предложения администрацией.
11. Студент знает 20 из 25 вопросов программы. Зачёт сдан, если студент ответит не менее чем на 3 из 4-х вопросов в билете. Взглянув на первый вопрос, студент обнаружил, что знает его. Какова вероятность, что студент сдаст зачёт?
Решение.
Пусть А – событие, заключающееся в том, что студент сдал экзамен;
В – событие, заключающееся в том, что студент знает первый вопрос в билете.
Очевидно,
что р(В)
=
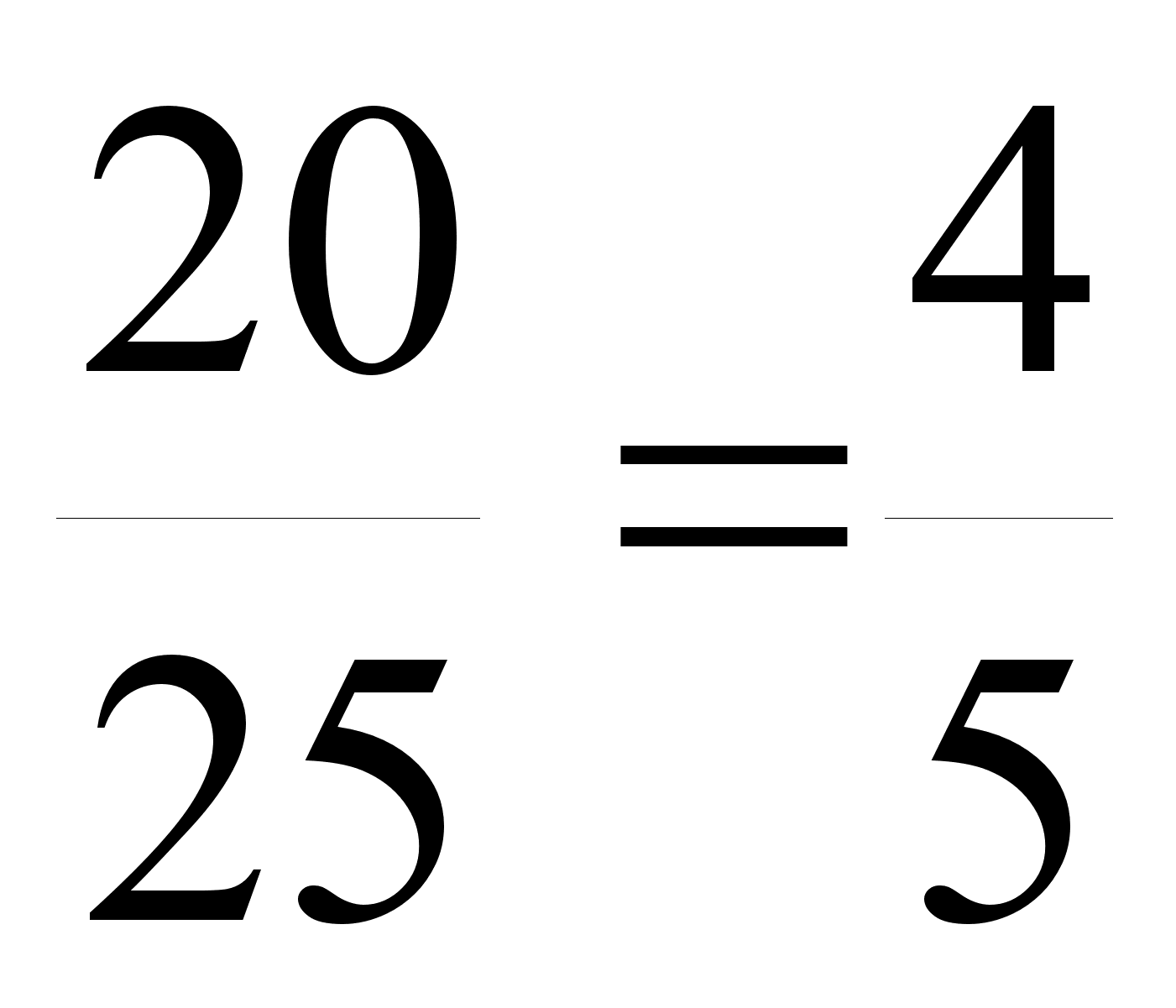 .
Теперь необходимо
определить
вероятность
р(АВ).
Из 25-ти вопросов
всего можно
составить
.
Теперь необходимо
определить
вероятность
р(АВ).
Из 25-ти вопросов
всего можно
составить
![]() различных
билетов, содержащих
4 вопроса. Все
билеты, выбор
которых удовлетворял
бы и событию
А и событию В,
должны быть
составлены
следующим
образом:
либо студент
знает все вопросы
билета (можно
составить всего
различных
билетов, содержащих
4 вопроса. Все
билеты, выбор
которых удовлетворял
бы и событию
А и событию В,
должны быть
составлены
следующим
образом:
либо студент
знает все вопросы
билета (можно
составить всего
![]() таких
билетов), либо
студент знает
первый, второй
и третий вопросы,
но не знает
четвёртого
(можно составить
всего 5
таких
билетов), либо
студент знает
первый, второй
и третий вопросы,
но не знает
четвёртого
(можно составить
всего 5![]() таких
билетов), либо
студент знает
первый, второй
и четвёртый
вопросы, но не
знает третьего
(тоже 5
таких
билетов), либо
студент знает
первый, второй
и четвёртый
вопросы, но не
знает третьего
(тоже 5![]() билетов),
либо студент
знает первый,
третий и четвёртый
вопросы, но не
знает второго
(тоже 5
билетов),
либо студент
знает первый,
третий и четвёртый
вопросы, но не
знает второго
(тоже 5![]() билетов).
Отсюда получаем,
что
билетов).
Отсюда получаем,
что
р(АВ)
=
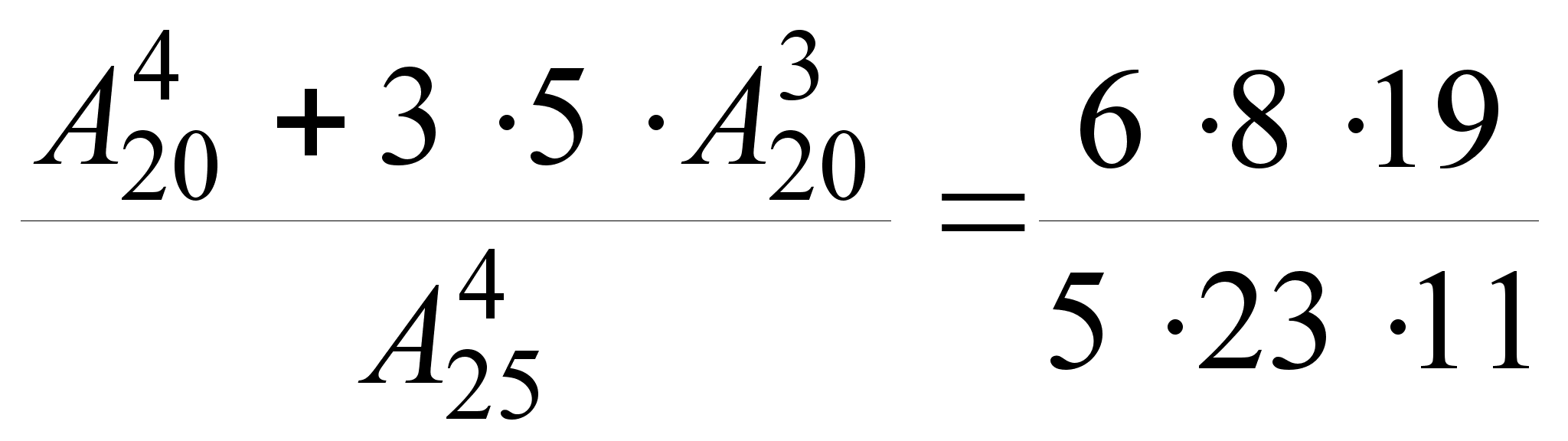
Осталось только найти искомую вероятность р(А/В):
р(А/В)
=
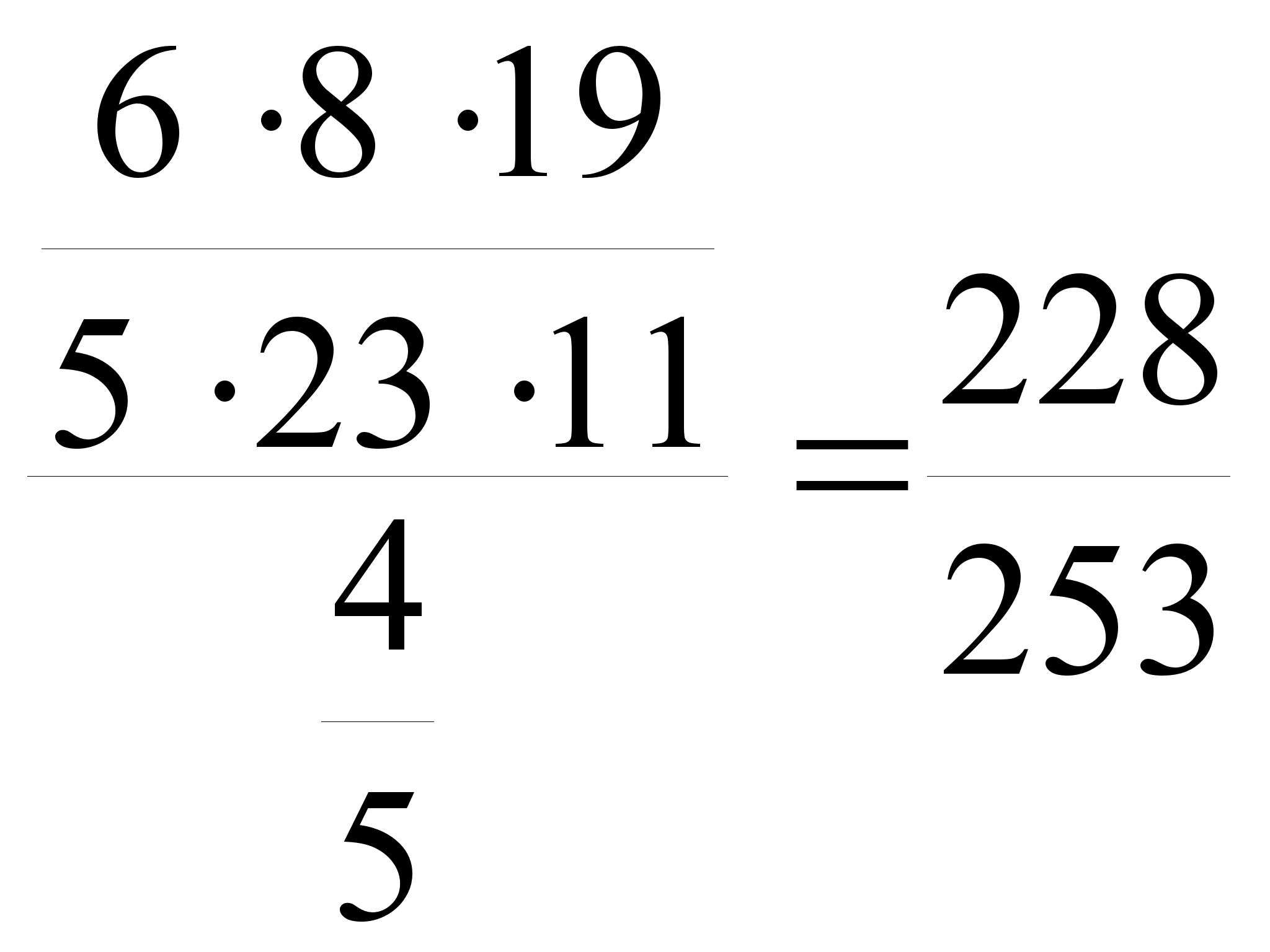
7
Комбинаторные формулы
Пусть имеется множество, состоящее из n элементов. Обозначим его Un. Перестановкой из n элементов называется заданный порядок во множестве Un.
Примеры перестановок:
1)распределение n различных должностей среди n человек;
2)расположение n различных предметов в одном ряду.
Сколько различных перестановок можно образовать во множестве Un? Число перестановок обозначается Pn (читается Р из n).
Чтобы
вывести формулу
числа перестановок,
представим
себе n ячеек,
пронумерованных
числами
![]() 1,2,...n.
Все перестановки
будем образовывать,
располагая
элементы Un
в этих
ячейках. В первую
ячейку можно
занести любой
из n элементов
(иначе: первую
ячейку можно
заполнить n
различными
способами).
Заполнив первую
ячейку, можно
n-1
способом заполнить
вторую ячейку
(иначе: при каждом
способе заполнения
первой ячейки
находится n-1
способов заполнения
второй ячейки).
Таким образом
существует
n(n-1)
способов заполнения
двух первых
ячеек. При заполнении
первых двух
ячеек можно
найти n-2
способов заполнения
третьей ячейки,
откуда получается,
что три ячейки
можно заполнить
n(n-1)(n-2)
способами.
Продолжая этот
процесс, получим,
что число способов
заполнения
n ячеек
равно
1,2,...n.
Все перестановки
будем образовывать,
располагая
элементы Un
в этих
ячейках. В первую
ячейку можно
занести любой
из n элементов
(иначе: первую
ячейку можно
заполнить n
различными
способами).
Заполнив первую
ячейку, можно
n-1
способом заполнить
вторую ячейку
(иначе: при каждом
способе заполнения
первой ячейки
находится n-1
способов заполнения
второй ячейки).
Таким образом
существует
n(n-1)
способов заполнения
двух первых
ячеек. При заполнении
первых двух
ячеек можно
найти n-2
способов заполнения
третьей ячейки,
откуда получается,
что три ячейки
можно заполнить
n(n-1)(n-2)
способами.
Продолжая этот
процесс, получим,
что число способов
заполнения
n ячеек
равно
![]() .
Отсюда
.
Отсюда
Pn = n(n - 1)(n - 2)...321
Число n(n - 1)(n - 2)...321, то есть произведение всех натуральных чисел от 1 до n, называется "n-факториал" и обозначается n!. Отсюда Pn =n!
Пример.
![]() .
.
По определению считается: 1!=1; 0!=1.
Размещениями
из n
элементов по
k
элементов будем
называть
упорядоченные
подмножества,
состоящие из
k
элементов,
множества Un
-
(множества,
состоящего
из n
элементов).
Число размещений
из n
элементов по
k
элементов
обозначается
![]()
![]() (читается "А
из n
по k").
(читается "А
из n
по k").
Примеры задач, приводящих к необходимости подсчета
1) Сколькими способами можно выбрать из 15 человек 5 кандидатов и назначить их на 5 различных должностей?
2) Сколькими способами можно из 20 книг отобрать 12 и расставить их в ряд на полке?
В задачах
о размещениях
полагается
kn.
В случае, если
k=n,
то легко получить
![]()
Для подсчета
![]() используем
тот же метод,
что использовался
для подсчета
Pn
,только здесь
возьмем лишь
k ячеек.
Первую ячейку
можно заполнить
n
способами,
вторую, при
заполненной
первой, можно
заполнить n-1
способами.
Можно продолжать
этот процесс
до заполнения
последней k-й
ячейки. Эту
ячейку при
заполненных
первых k-1
ячейках можно
заполнить
n-(k-1)
способами (или
n-k+1).
Таким образом
все k
ячеек заполняются
числом способов,
равным
используем
тот же метод,
что использовался
для подсчета
Pn
,только здесь
возьмем лишь
k ячеек.
Первую ячейку
можно заполнить
n
способами,
вторую, при
заполненной
первой, можно
заполнить n-1
способами.
Можно продолжать
этот процесс
до заполнения
последней k-й
ячейки. Эту
ячейку при
заполненных
первых k-1
ячейках можно
заполнить
n-(k-1)
способами (или
n-k+1).
Таким образом
все k
ячеек заполняются
числом способов,
равным
![]()
Отсюда
получаем:
![]()
Пример. Сколько существует различных вариантов выбора 4-х кандидатур из 9-ти специалистов для поездки в 4 различных страны?
![]()
Сочетаниями из n элементов по k элементов называются подмножества, состоящие из k элементов множества Un (множества, состоящего из n элементов).
Одно сочетание от другого отличается только составом выбранных элементов (но не порядком их расположения, как у размещений).
Число
сочетаний из
n
элементов по
k
элементов
обозначается
![]() (читается "C
из n
по k").
(читается "C
из n
по k").
Примеры задач, приводящих к необходимости подсчета числа сочетаний:
1) Сколькими способами можно из 15 человек выбрать 6 кандидатов для назначения на работу в одинаковых должностях?
2) Сколькими способами можно из 20 книг отобрать 12 книг?
Выведем формулу для подсчета числа сочетаний. Пусть имеется множество Un и нужно образовать упорядоченное подмножество множества Un, содержащее k элементов (то есть образовать размещение). Делаем это так:
1) выделим
какие-либо k
элементов из
n
элементов
множества
![]() Un
Это, согласно
сказанному
выше, можно
сделать
Un
Это, согласно
сказанному
выше, можно
сделать
![]() способами;
способами;
2) упорядочим
выделенные
k
элементов, что
можно сделать
![]() способами.
Всего можно
получить
способами.
Всего можно
получить
![]() вариантов
(упорядоченных
подмножеств),
откуда следует:
вариантов
(упорядоченных
подмножеств),
откуда следует:
![]() ,то есть
,то есть
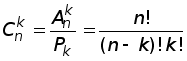
Пример: 6 человек из 15 можно выбрать числом способов, равным
![]()
Задачи на подсчет числа подмножеств конечного множества называются комбинаторными. Рассмотрим некоторые комбинаторные задачи.
1.Из семи заводов организация должна выбрать три для размещения трех различных заказов. Сколькими способами можно разместить заказы?
Так как все заводы различны, и из условия ясно, что каждый завод может либо получить один заказ, либо не получить ни одного, здесь нужно считать число размещений
![]()
![]()
![]() 2.Если
из текста задачи
1 убрать условие
различия трех
заказов, сохранив
все остальные
условия, получим
другую задачу.
Теперь способ
размещения
заказов определяется
только выбором
тройки заводов,
так как все эти
заводы получат
одинаковые
заказы, и число
вариантов
определяется
как число сочетаний.
2.Если
из текста задачи
1 убрать условие
различия трех
заказов, сохранив
все остальные
условия, получим
другую задачу.
Теперь способ
размещения
заказов определяется
только выбором
тройки заводов,
так как все эти
заводы получат
одинаковые
заказы, и число
вариантов
определяется
как число сочетаний.
![]()
![]()
3.Имеются 7 заводов. Сколькими способами организация может разместить на них три различных производственных заказа? (Заказ нельзя дробить, то есть распределять его на несколько заводов).
В отличие от условия первой задачи, здесь организация может отдать все три заказа первому заводу или, например, отдать два заказа второму заводу, а один - седьмому.
Задача решается так. Первый заказ может быть размещен семью различными способами (на первом заводе, на втором и т.д.). Разместив первый заказ, имеем семь вариантов размещения второго (иначе, каждый способ размещения первого заказа может сопровождаться семью способами размещения второго). Таким образом, существует 77=49 способов размещения первых двух заказов. Разместив их каким-либо образом, можем найти 7 вариантов размещения третьего (иначе, каждый способ размещения первых двух заказов может сопровождаться семью различными способами распределения третьего заказа). Следовательно, существуют 497=73 способов размещения трех заказов. (Если бы заказов было n, то получилось бы 7n способов размещения).
4.Как решать задачу 3, если в ее тексте вместо слов "различных производственных заказа" поставить "одинаковых производственных заказа"?
5.Добавим к условию задачи 1 одну фразу: организация также должна распределить три различных заказа на изготовление деревянных перекрытий среди 4-х лесопилок. Сколькими способами могут быть распределены все заказы?
Каждый
из
![]() способов
распределения
заказов на
заводах может
сопровождаться
способов
распределения
заказов на
заводах может
сопровождаться
![]() способами
размещения
заказов на
лесопилках.
Общее число
возможных
способов размещения
всех заказов
будет равно
способами
размещения
заказов на
лесопилках.
Общее число
возможных
способов размещения
всех заказов
будет равно
![]()
Случайный эксперимент, элементарные исходы, события.
Случайным (стохастическим) экспериментом или испытанием называется осуществление какого-либо комплекса условий, который можно практически или мысленно воспроизвести сколь угодно большое число раз.
Примеры случайного эксперимента: подбрасывание монеты, извлечение одной карты из перетасованной колоды, подсчет числа автомобилей в очереди на бензоколонке в данный момент.
Явления, происходящие при реализации этого комплекса условий, то есть в результате случайного эксперимента, называются элементарными исходами. Считается, что при проведении случайного эксперимента реализуется только один из возможных элементарных исходов.
Если монету подбросить один раз, то элементарными исходами можно считать выпадение герба (Г) или цифры (Ц).
Если случайным экспериментом считать троекратное подбрасывание монеты, то элементарными исходами можно считать следующие:
ГГГ, ГГЦ, ГЦГ, ЦГГ, ГЦЦ, ЦГЦ, ЦЦГ, ЦЦЦ.
Множество всех элементарных исходов случайного эксперимента называется пространством элементарных исходов . Будем обозначать пространство элементарных исходов буквой (омега большая) i-й элементарный исход будем обозначатьi (-омега малая).
Если пространство элементарных исходов содержит n элементарных исходов, то
=(1, 2 ,..., n ).
Для троекратного подбрасывания монеты,
=(ГГГ, ГГЦ,...ЦЦЦ).
Если случайный эксперимент - подбрасывание игральной кости, то =(1,2,3,4,5,6).
Если конечно или счетно, то случайным событием или просто событием называется любое подмножество .
Множество называется счетным, если между ним и множеством N натуральных чисел можно установить взаимно-однозначное соответствие.
Пример счетного множества: множество возможных значений времени прилета инопланетян на Землю, если время отсчитывать с настоящего момента и исчислять с точностью до секунды.
Примеры несчетных множеств: множество точек на заданном отрезке, множество чисел x, удовлетворяющих неравенству 1 x 2.
В случае несчетного множества будем называть событиями только подмножества, удовлетворяющие некоторому условию (об этом будет сказано позже).
Приведем примеры событий. Пусть бросается игральная кость, и элементарным исходом считается выпавшее число очков: =(1,2,3,4,5,6). A — событие, заключающееся в том, что выпало четное число очков: А=(2,4,6); B — событие, заключающееся в том, что выпало число очков, не меньшее 3-х: B=(3,4,5,6).
Говорят, что те исходы, из которых состоит событие А, благоприятствуют событию А.
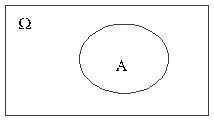
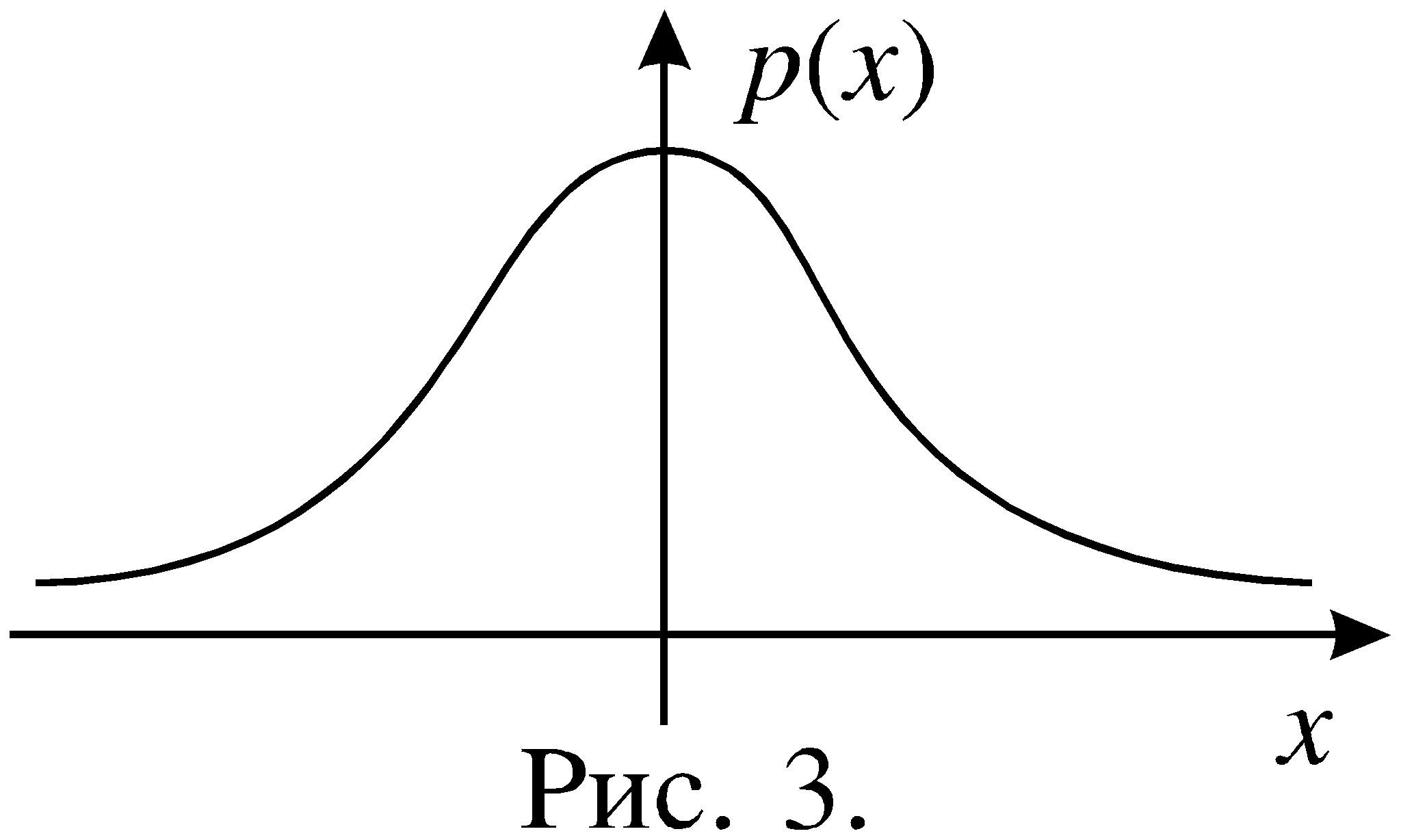
Рис.1
События удобно изображать в виде рисунка, который называется диаграммой Венна. На рисунке 1 пространство элементарных исходов изображено в виде прямоугольника, а множество элементарных исходов, благоприятствующих событию A, заключено в эллипс. Сами исходы на диаграмме Венна не изображаются, а информация о соотношении между их множествами содержится в расположении границ соответствующих областей.
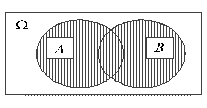
Рис.2
Приведем пример объединения событий. Пусть два стрелка стреляют в мишень одновременно, и событие А состоит в том, что в мишень попадает 1-й стрелок, а событие B - в том, что в мишень попадает 2-й. Событие AUB

Рис.3
Произведением (пересечением) A∩B событий А и B называется событие, состоящее из всех тех элементарных исходов, которые принадлежат и А и B. На рисунке 3 пересечение событий А и B изображено в виде заштрихованной области. В условиях приведенного выше примера событие A∩B заключается в том, что в мишень попали оба стрелка.
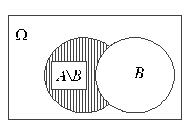
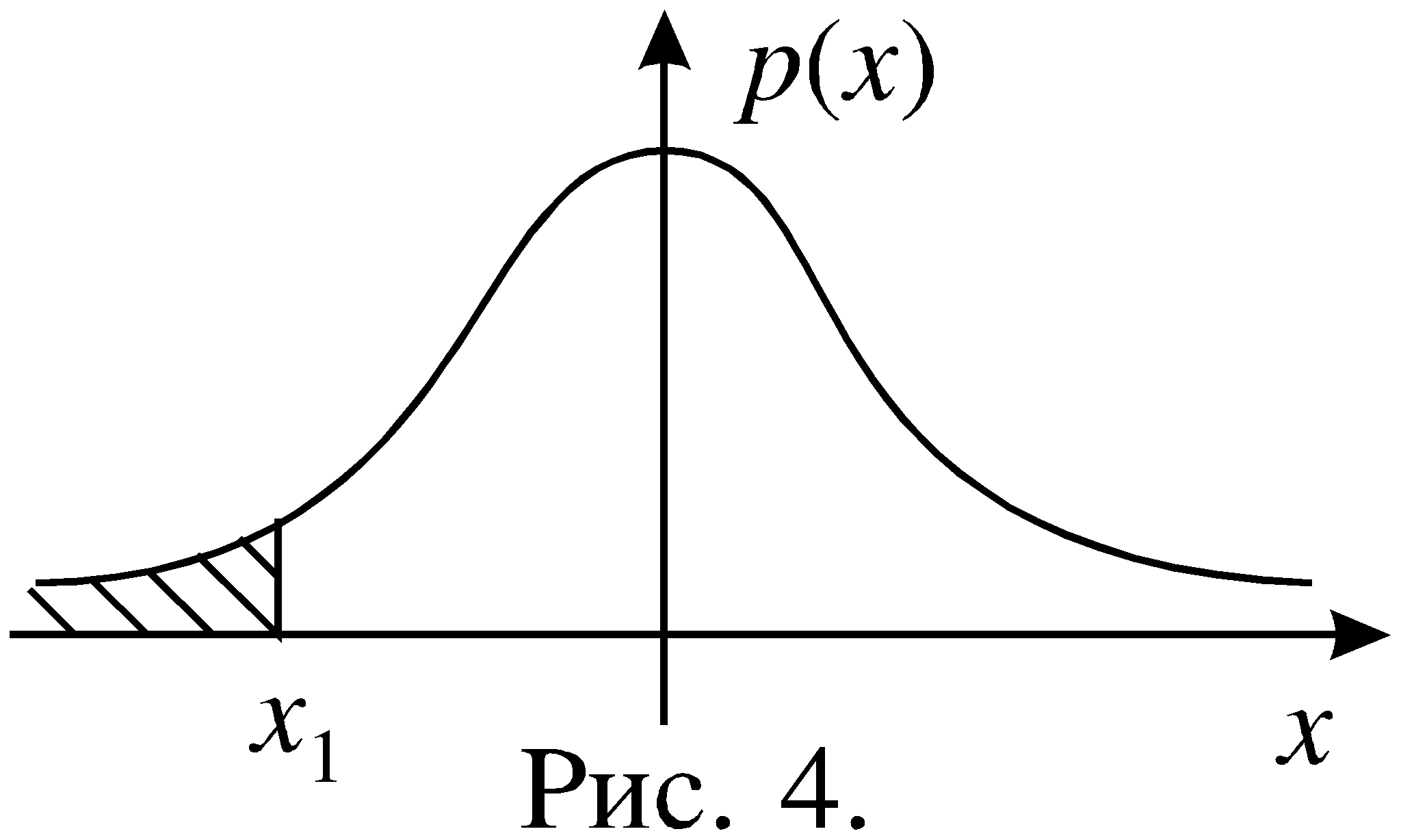
Рис.4
В условиях рассмотренного выше примера событие А\B заключается в том, что первый стрелок попал в мишень, а второй промахнулся.Событие называется достоверным (оно обязательно происходит в результате случайного эксперимента).
Пустое
множество
называется
невозможным
событием. Событие
![]() =\A
называется
противоположным
событию
А
или дополнением
события
А.
=\A
называется
противоположным
событию
А
или дополнением
события
А.
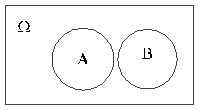
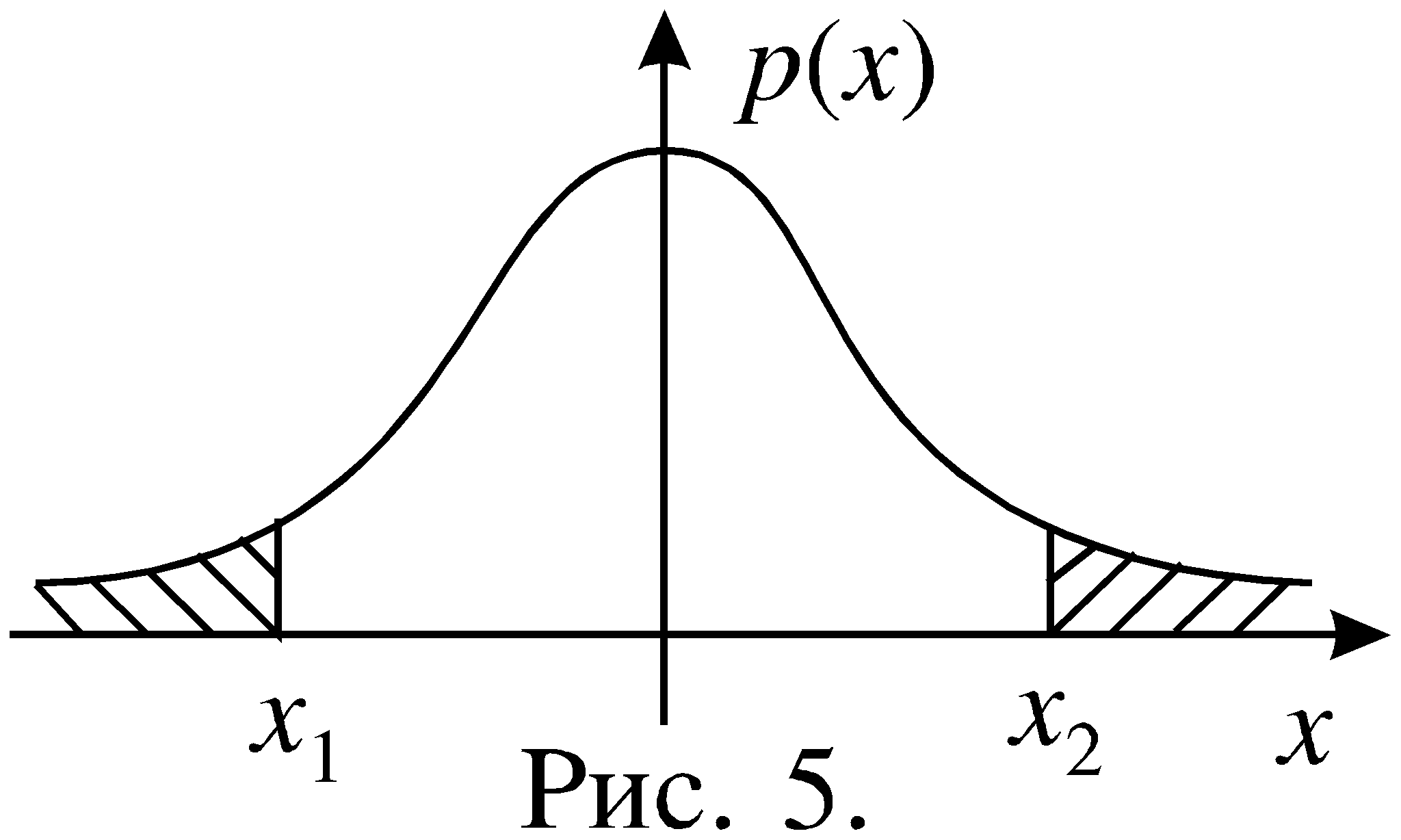
Рис.5
Непосредственно из введенных определений следуют равенства: AUВероятностное пространство Случай конечного или счетного числа исходов.
Для построения полной и законченной теории случайного эксперимента или теории вероятностей, помимо введенных исходных понятий случайного эксперимента, элементарного исхода, пространства элементарных исходов, события, введем аксиому (пока для случая конечного или счетного пространства элементарных исходов).
Каждому элементарному исходу i пространства соответствует некоторая неотрицательная числовая характеристика Pi шансов его появления, называемая вероятностью исхода i , причем
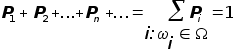
(здесь суммирование ведется по всем i, для которых выполняется условие: i).
Отсюда следует, что 0 Pi 1для всех i.
Вероятность любого события А определяется как сумма вероятностей всех элементарных исходов, благоприятствующих событию А. Обозначим ее Р(А).
![]() (*)
(*)
Отсюда следует, что
1) 0 P(A) 1;
2) P()=1;
3) P()=0.
Будем говорить, что задано вероятностное пространство, если задано пространство элементарных исходов и определено соответствие
i P(i ) =Pi.
Возникает вопрос: как определить из конкретных условий решаемой задачи вероятность P(i ) отдельных элементарных исходов?
Классическое определение вероятности.
Вычислять вероятности P(i ) можно, используя априорный подход, который заключается в анализе специфических условий данного эксперимента (до проведения самого эксперимента).
Возможна
ситуация, когда
пространство
элементарных
исходов состоит
из конечного
числа N
элементарных
исходов, причем
случайный
эксперимент
таков, что
вероятности
осуществления
каждого из этих
N
элементарных
исходов представляются
равными.
Примеры таких
случайных
экспериментов:
подбрасывание
симметричной
монеты, бросание
правильной
игральной
кости, случайное
извлечение
игральной карты
из перетасованной
колоды. В силу
введенной
аксиомы вероятности
каждого элементарного
исхода в этом
случае равны
![]() .
Из этого следует,
что если событие
А
содержит NA
элементарных
исходов, то в
соответствии
с определением
(*)
.
Из этого следует,
что если событие
А
содержит NA
элементарных
исходов, то в
соответствии
с определением
(*)
![]()
В данном классе ситуаций вероятность события определяется как отношение числа благоприятных исходов к общему числу всех возможных исходов.
Пример. Из набора, содержащего 10 одинаковых на вид электроламп, среди которых 4 бракованных, случайным образом выбирается 5 ламп. Какова вероятность, что среди выбранных ламп будут 2 бракованные?
Прежде
всего отметим,
что выбор любой
пятерки ламп
имеет одну и
ту же вероятность.
Всего существует
![]() способов составить
такую пятерку,
то есть случайный
эксперимент
в данном случае
имеет
способов составить
такую пятерку,
то есть случайный
эксперимент
в данном случае
имеет
![]() равновероятных
исходов.
равновероятных
исходов.
Сколько из этих исходов удовлетворяют условию "в пятерке две бракованные лампы", то есть сколько исходов принадлежат интересующему нас событию?
Каждую
интересующую
нас пятерку
можно составить
так: выбрать
две бракованные
лампы, что можно
сделать числом
способов, равным
![]() .
Каждая пара
бракованных
ламп может
встретиться
столько раз,
сколькими
способами ее
можно дополнить
тремя не бракованными
лампами, то
есть
.
Каждая пара
бракованных
ламп может
встретиться
столько раз,
сколькими
способами ее
можно дополнить
тремя не бракованными
лампами, то
есть
![]() раз. Получается,
что число пятерок,
содержащих
две бракованные
лампы, равно
раз. Получается,
что число пятерок,
содержащих
две бракованные
лампы, равно
![]()
![]() .
.
Отсюда, обозначив искомую вероятность через P, получаем:
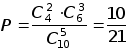
7
Лекция 10.
Распределение
 2.
2.
Пусть
имеется n
независимых
случайных
величин 1, 2, ..., n,
распределенных
по нормальному
закону с математическим
ожиданием,
равным нулю,
и дисперсией,
равной единице.
Тогда случайная
величина
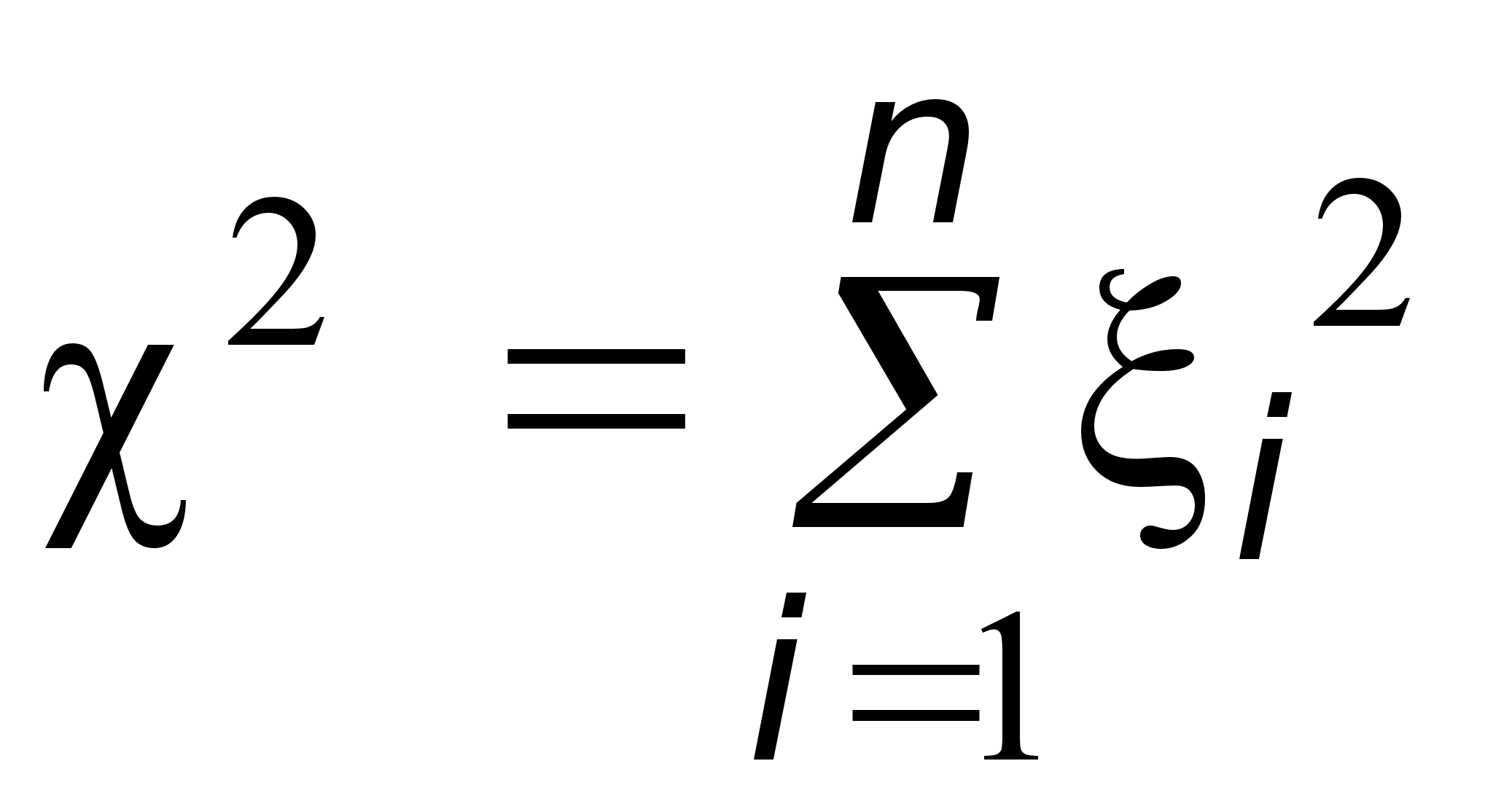 распределена
по закону, который
называется
“распределение
2”
или “распределение
Пирсона”. Очевидно,
что она может
принимать лишь
неотрицательные
значения. Число
n
называется
числом
степеней свободы.
распределена
по закону, который
называется
“распределение
2”
или “распределение
Пирсона”. Очевидно,
что она может
принимать лишь
неотрицательные
значения. Число
n
называется
числом
степеней свободы.
Для того,
чтобы определить
вероятность
попадания
случайной
величины 2
в какой-либо
промежуток
из множества
положительных
чисел, пользуются
таблицей
распределения
2.
Обычно такая
таблица позволяет
|
q n |
0,99 | 0,975 | 0,95 | ... | 0,1 | 0,05 | 0,01 |
| 1 |
0,0315 |
0,0398 |
0,0239 |
... | 2,71 | 3,84 | 6,63 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 10 | 2,56 | 3,25 | 3,94 | ... | 16,0 | 18,3 | 23,2 |
| ... | ... | ... | ... | ... | ... | ... | ... |
Таблица 1.
по вероятности q и по числу степеней свободы n определить так называемый квантиль q2, если q и q2 связаны соотношением
P(2 > q2) = q.
Эта формула означает: вероятность того, что случайная величина 2 примет значение, большее чем определенное значение q2, равна q.
Таблица 1 представляет собой фрагмент таблицы распределения 2. Из него видно, что случайная величина 2 с 10-ю степенями свободы с вероятностью q = 0,95 принимает значение, большее 3,94, а та же величина с одной степенью свободы с вероятностью q = 0,975 превышает 0,00098.
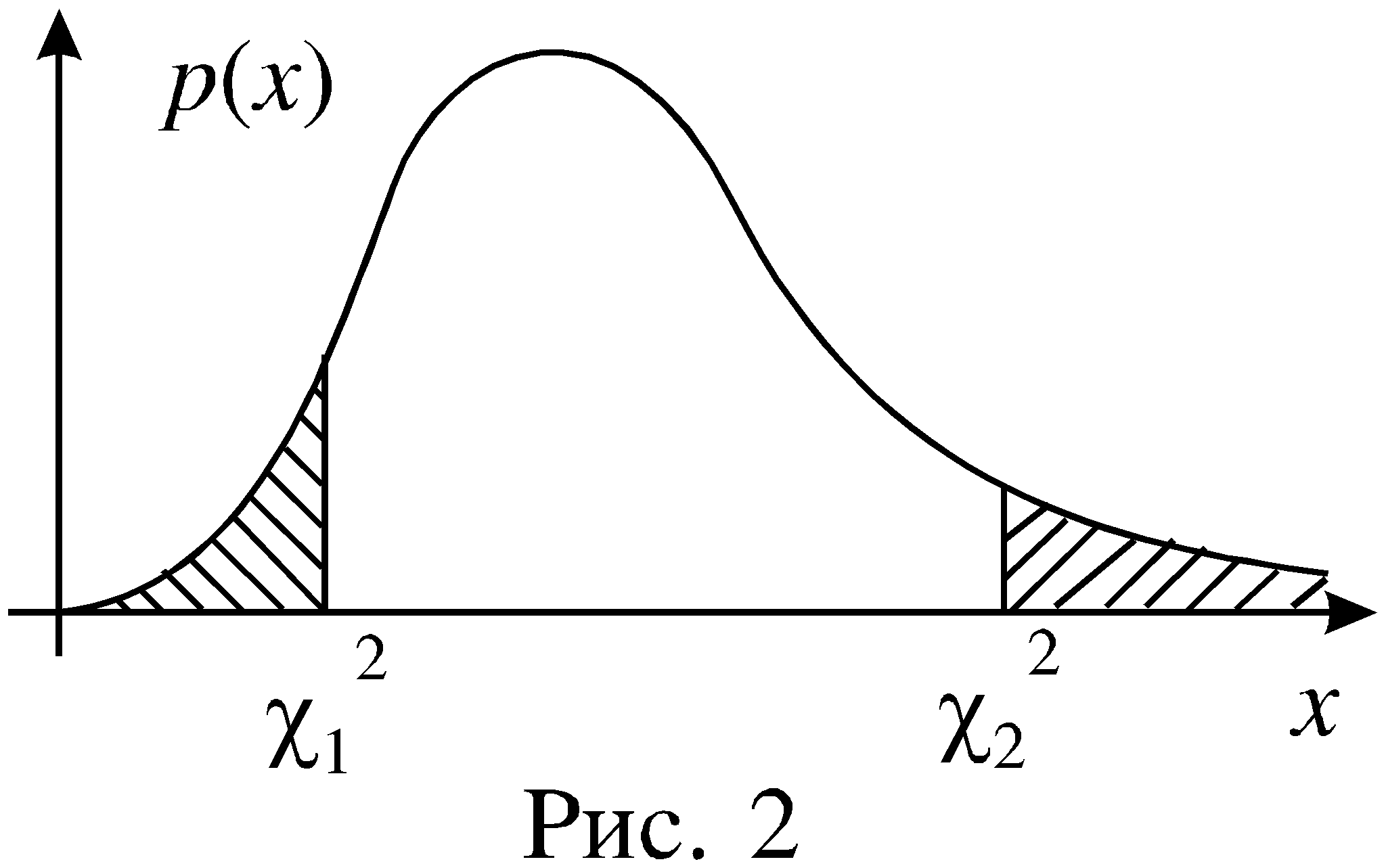
Решение. График плотности распределения 2 с 10-ю степенями свободы схематично изображен на рисунке 2. Будем считать, что площади заштрихованных областей (правая область не ограничена справа) равны между собой. Примем условия:
P(2 < 12) = P(2 > 22) = (1 - 0,9)/2 = 0,05, (1)
тогда P(12 < 2 < 22) = 0,9.
Равенства (1) сразу позволяют по таблице определить: 22 = 18,3. Для определения левой границы интересующего нас интервала придется воспользоваться очевидным равенством P(2 > 12) = 0,95. Из таблицы 1. определяем: 12 = 3,94 , и теперь можно сформулировать ответ задачи: значение случайной величины 2 с вероятностью 0,9 принадлежит интервалу (3,94; 18,3).
Распределение Стьюдента.
Многие задачи статистики приводят к случайной величине вида
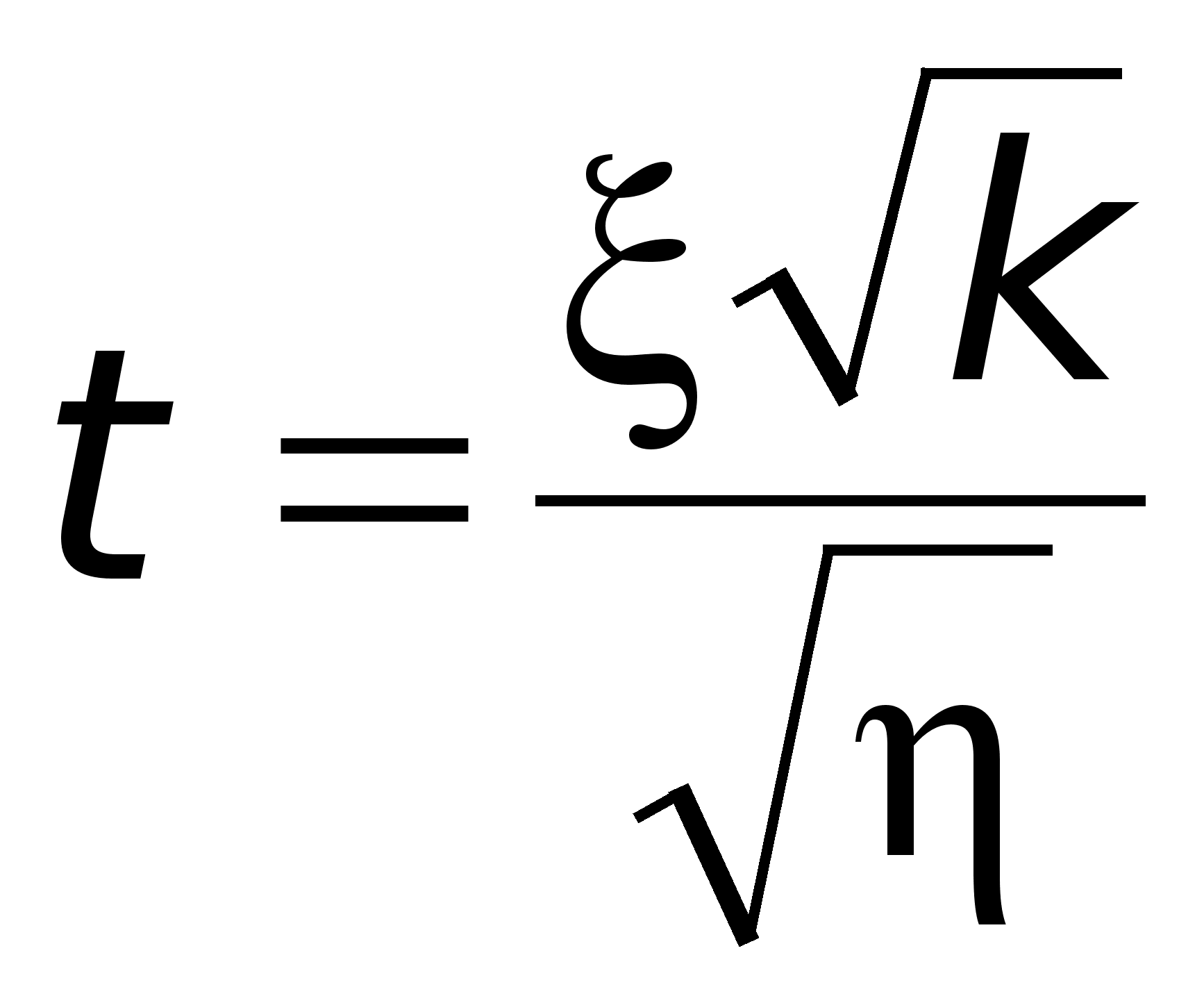 ,
,
где и – независимые случайные величины, причем – нормально распределенная случайная величина с параметрами M = 0 и D = 1, а распределена по закону 2 c k степенями свободы.
Закон распределения случайной величины t называется закономраспределения Стьюдента с k степенями свободы.
Таблицы распределения Стьюдента позволяют при данном числе степеней свободы k по вероятности q определить значение tq, для которого выполняется соотношение P(t > tq) = q. Фрагмент такой таблицы представляет собой таблица 2.
|
q k |
0,1 | 0,05 | ... | 0,01 | 0,005 | ... |
| 1 | 6,314 | 12,71 | ... | 63,57 | 318 | ... |
| ... | ... | ... | ... | ... | ... | ... |
| 12 | 1,782 | 2,179 |
... |
3,055 | 3,428 | ... |
| ... | ... | ... | ... | ... | ... | ... |
| Таблица 2 | ||||||
Задача. Найти симметричный интервал, в который случайная величина, распределенная по закону Стьюдента с 12-ю степенями свободы, попадает вероятностью 0,9.
Решение. Очевидны соотношения:
P(–x < t < x) = P(t < x) = 1 – P(t x) = 0,9.
Из последнего равенства следует:
P(t x) = 0,1 , (n = 12).
Определяем из таблицы: x = 1,782. Нестрогое неравенство в скобках в левой части последней формулы нас не должно смущать, так как мы имеем дело с непрерывной случайной величиной, и вероятность того, что она примет конкретное значение, равна нулю.
Задача. Найти значение x из условия P(t > x) = 0,995 , где t – случайная величина, распределенная по закону Стьюдента с 12-ю степенями свободы.
x2 = x, причем x определяется из условия
P(t > x) = 0,01. Из таблицы 2 находим: x = 3,055. Теперь можно выписать ответ задачи:
P(t > –3,055) = 0,995.
Распределение Фишера.
Важные приложения имеет в статистике случайная величина
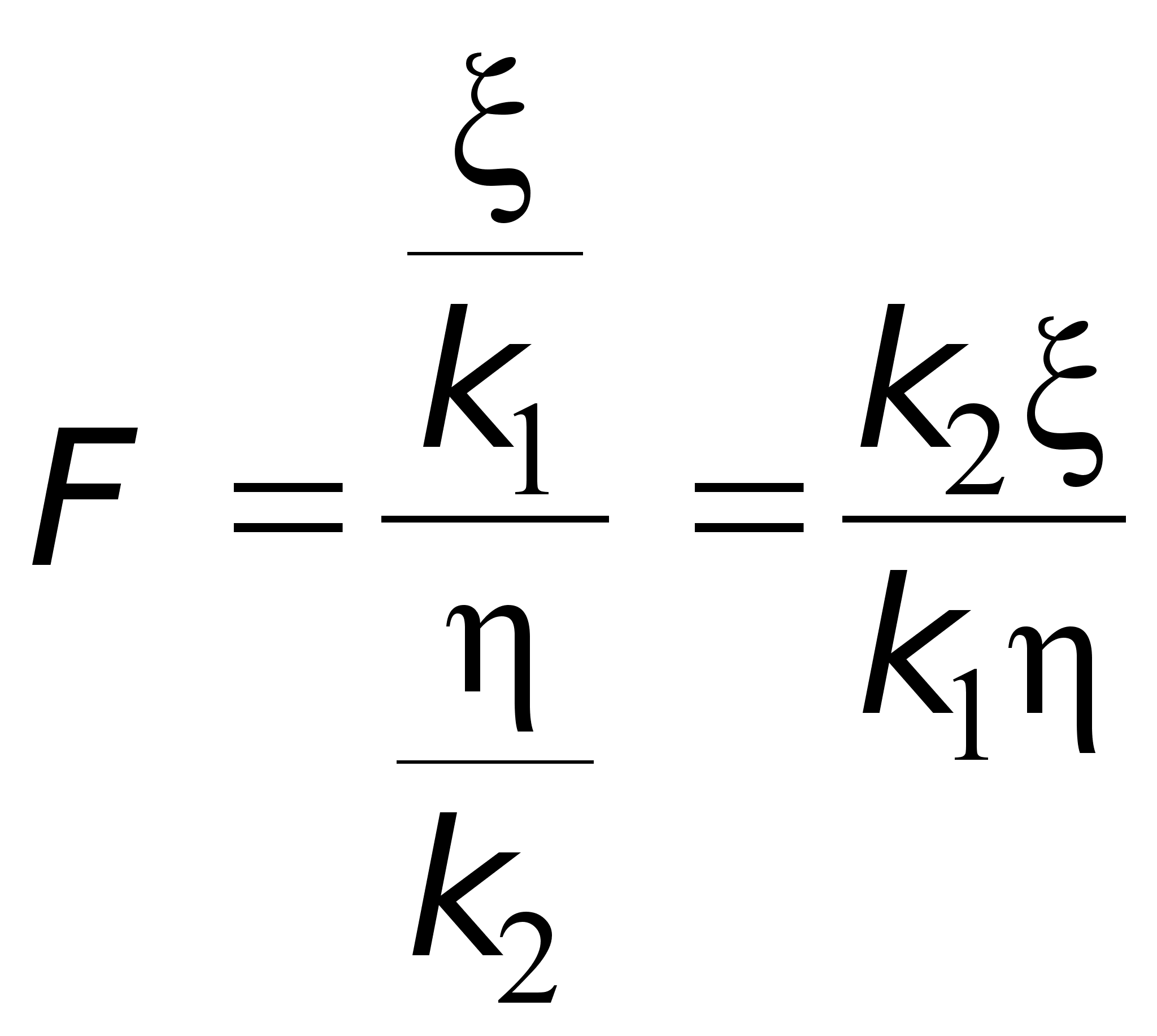 ,
,
где – случайная величина, распределенная по закону 2 с k1 степенями свободы, а – случайная величина, распределенная по закону 2 с k2 степенями свободы.
Случайная величина F распределена по закону, называемому законом распределения Фишера с k1 и k2 степенями свободы. При заданных числах k1 и k2 и по вероятности q по таблице определяется значение Fq такое, что
P(F > Fq) = q.
Обычно таблицы составляются для значений q, равных 0,05 или 0,01, а иногда для обоих этих значений. Фрагмент такой таблицы представляет собой таблица 3.
|
k1 k2 |
1 | ... | 10 | ... | 20 | ... |
| 1 |
161,4 647,8 |
... |
241,9 6056 |
... |
248 6209 |
... |
| ... | ... | ... | ... | ... | ... | ... |
| 10 |
4,96 10,04 |
... |
2,97 4,85 |
... |
2,77 4,41 |
... |
| ... | ... | ... | ... | ... | ... | ... |
| Таблица 3. | ||||||
В этой таблице в верхней части каждой клетки дается значение Fq при q = 0,05 , а в нижней части — при q = 0,01.
6
Лекция 11.
Математическая статистика.
Основной задачей математической статистики является разработка методов получения научно обоснованных выводов о массовых явлениях и процессах из данных наблюдений и экспериментов. Эти выводы и заключения относятся не к отдельным испытаниям, из повторения которых складывается данное массовое явление, а представляют собой утверждения об общих вероятностных характеристиках данного процесса, то есть о вероятностях, законах распределения, математических ожиданиях, дисперсиях и т. д. Такое использование фактических данных как раз и является отличительной чертой статистического метода.
Пусть мы располагаем сведениями (обычно довольно ограниченными), например, о числе дефектных изделий в изготовленной в определенных условиях продукции или о результатах испытаний материалов на разрушение и т. п. Собранные нами данные могут представлять непосредственный интерес в смысле информации о качестве той или иной партии продукции. Статистические же проблемы возникают тогда, когда мы на основе той же информации начинаем делать выводы относительно более широкого круга явлений. Так например нас может интересовать качество технологического процесса, для чего мы оцениваем вероятность получения в нем дефектного изделия или среднюю долговечность изделия. В этом случае мы рассматриваем собранный материал не ради его самого, а лишь как некую пробную группу или выборку, представляющую только серии из возможных результатов, которые мы могли бы встретить при продолжении наблюдений массового процесса в данной обстановке. Выводы и оценки, основанные на материале наблюдений, отражают случайный состав пробной группы и поэтому считаются приблизительными оценками вероятностного характера. Во многих случаях теория указывает, как наилучшим способом использовать имеющуюся информацию для получения по возможности более точных и надежных характеристик, указывая при этом степень надежности выводов, объясняющуюся ограниченностью запаса сведений.
В математической статистике рассматриваются две основные категории задач: оценивание и статистическая проверка гипотез. Первая задача разделяется на точечное оценивание и интервальное оценивание параметров распределения. Например может возникнуть необходимость по наблюдениям получить точечные оценки параметров Mx и Dx. Если мы хотим получить некоторый интервал, с той или иной степенью достоверности содержащий истинное значение параметра, то это задача интервального оценивания.
Вторая задача – проверка гипотез – заключается в том, что мы делаем предположение о распределении вероятностей случайной величины (например, о значении одного или нескольких параметров функции распределения) и решаем, согласуются ли в некотором смысле эти значения параметров с полученными результатами наблюдений.
Выборочный метод.
Пусть нам нужно обследовать количественный признак в партии экземпляров некоторого товара. Проверку партии можно проводить двумя способами:
1) провести сплошной контроль всей партии;
2) провести контроль только части партии.
Первый способ не всегда осуществим, например, из–за большого числа экземпляров в партии, из–за дороговизны проведения операции контроля, из–за того, что контроль связан с разрушением экземпляра (проверка электролампы на долговечность ее работы).
При втором способе множество случайным образом отобранных объектов называется выборочной совокупностью или выборкой. Все множество объектов, из которого производится выборка, называется генеральной совокупностью. Число объектов в выборке называется объемом выборки. Обычно будем считать, что объем генеральной совокупности бесконечен.
Выборки разделяются на повторные (с возвращением) и бесповторные (без возвращения).
Обычно осуществляются бесповторные выборки, но благодаря большому (бесконечному) объему генеральной совокупности ведутся расчеты и делаются выводы, справедливые лишь для повторных выборок.
Выборка должна достаточно полно отражать особенности всех объектов генеральной совокупности, иначе говоря, выборка должна быть репрезентативной (представительной).
Выборки различаются по способу отбора.
1. Простой случайный отбор.
Все элементы генеральной совокупности нумеруются и из таблицы случайных чисел берут, например, последовательность любых 30-ти идущих подряд чисел. Элементы с выпавшими номерами и входят в выборку.
2. Типический отбор.
Такой отбор производится в том случае, если генеральную совокупность можно представить в виде объединения подмножеств, объекты которых однородны по какому–то признаку, хотя вся совокупность такой однородности не имеет (партия товара состоит из нескольких групп, произведенных на разных предприятиях). Тогда по каждому подмножеству проводят простой случайный отбор, и в выборку объединяются все полученные объекты.
3. Механический отбор.
Отбирают каждый двадцатый (сотый) экземпляр.
4. Серийный отбор.
В выборку подбираются экземпляры, произведенные на каком–то производстве в определенный промежуток времени.
В дальнейшем под генеральной совокупностью мы будем подразумевать не само множество объектов, а множество значений случайной величины, принимающей числовое значение на каждом из объектов. В действительности генеральной совокупности как множества объектов может и не существовать. Например имеет смысл говорить о множестве деталей, которые можно произвести, используя данный технологический процесс. Используя какие–то известные нам характеристики данного процесса, мы можем оценивать параметры этого несуществующего множества деталей. Размер детали – это случайная величина, значение которой определяется воздействием множества факторов, составляющих технологический процесс. Нас, например, может интересовать вероятность, с которой эта случайная величина принимает значение, принадлежащее некоторому интервалу. На этот вопрос можно ответить, зная закон распределения этой случайной величины, а также ее параметры, такие как Mx и Dx.
Итак, отвлекаясь от понятия генеральной совокупности как множества объектов, обладающих некоторым признаком, будем рассматривать генеральную совокупность как случайную величину x, закон распределения и параметры которой определяются с помощью выборочного метода.
Рассмотрим выборку объема n, представляющую данную генеральную совокупность. Первое выборочное значение x1 будем рассматривать как реализацию, как одно из возможных значений случайной величины x1, имеющей тот же закон распределения с теми же параметрами, что и случайная величина x. Второе выборочное значение x2 – одно из возможных значений случайной величины x2 с тем же законом распределения, что и случайна величина x. То же самое можно сказать о значениях x3, x4,..., xn .
Таким образом на выборку будем смотреть как на совокупность независимых случайных величин x1, x2, ..., xn, распределенных так же, как и случайная величина x, представляющая генеральную совокупность. Выборочные значения x1, x2, ..., xn – это значения, которые приняли эти случайные величины в результате 1-го, 2-го, ..., n-го эксперимента.
Вариационный ряд.
Пусть для объектов генеральной совокупности определен некоторый признак или числовая характеристика, которую можно замерить (размер детали, удельное количество нитратов в дыне, шум работы двигателя). Эта характеристика – случайная величина x, принимающая на каждом объекте определенное числовое значение. Из выборки объема n получаем значения этой случайной величины в виде ряда из n чисел:
x1, x2,..., xn. (*)
Эти числа называются значениями признака.
Среди чисел ряда (*) могут быть одинаковые числа. Если значения признака упорядочить, то есть расположить в порядке возрастания или убывания, написав каждое значение лишь один раз, а затем под каждым значением xi признака написать число mi, показывающее сколько раз данное значение встречается в ряду (*):
|
x1 |
x2 |
x3 |
... |
xk |
|
m1 |
m2 |
m3 |
... |
mk |
то получится таблица, называемая дискретным вариационным рядом. Число mi называется частотой i-го значения признака.
Очевидно, что xi в ряду (*) может не совпадать с xi в вариационном ряду. Очевидна также справедливость равенства
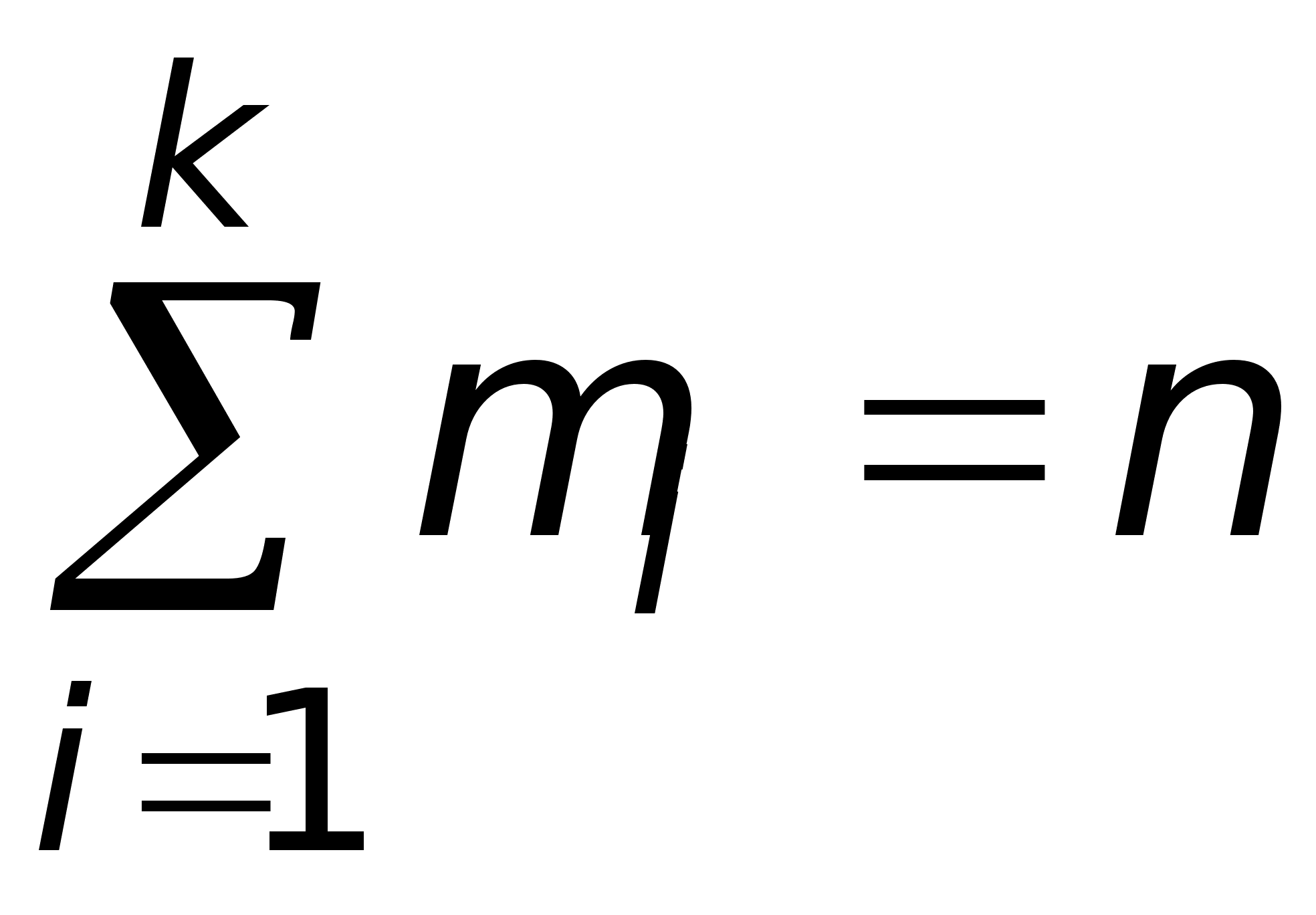 .
.
Если промежуток между наименьшим и наибольшим значениями признака в выборке разбить на несколько интервалов одинаковой длины, каждому интервалу поставить в соответствие число выборочных значений признака, попавших в этот интервал, то получим интервальный вариационный ряд. Если признак может принимать любые значения из некоторого промежутка, то есть является непрерывной случайной величиной, приходится выборку представлять именно таким рядом. Если в вариационном интервальном ряду каждый интервал [ai; ai+1) заменить лежащим в его середине числом (ai+ai+1)/2, то получим дискретный вариационный ряд. Такая замена вполне естественна, так как, например, при измерении размера детали с точностью до одного миллиметра всем размерам из промежутка [49,5; 50,5), будет соответствовать одно число, равное 50.
Точечные оценки параметров генеральной совокупности.
Во многих случаях мы располагаем информацией о виде закона распределения случайной величины (нормальный, бернуллиевский, равномерный и т. п.), но не знаем параметров этого распределения, таких как Mx, Dx. Для определения этих параметров применяется выборочный метод.
Пусть выборка объема n представлена в виде вариационного ряда. Назовем выборочной средней величину
![]()
Величина
![]() называется
относительной
частотой
значения признака
xi.
Если значения
признака, полученные
из выборки не
группировать
и не представлять
в виде вариационного
ряда, то для
вычисления
выборочной
средней нужно
пользоваться
формулой
называется
относительной
частотой
значения признака
xi.
Если значения
признака, полученные
из выборки не
группировать
и не представлять
в виде вариационного
ряда, то для
вычисления
выборочной
средней нужно
пользоваться
формулой
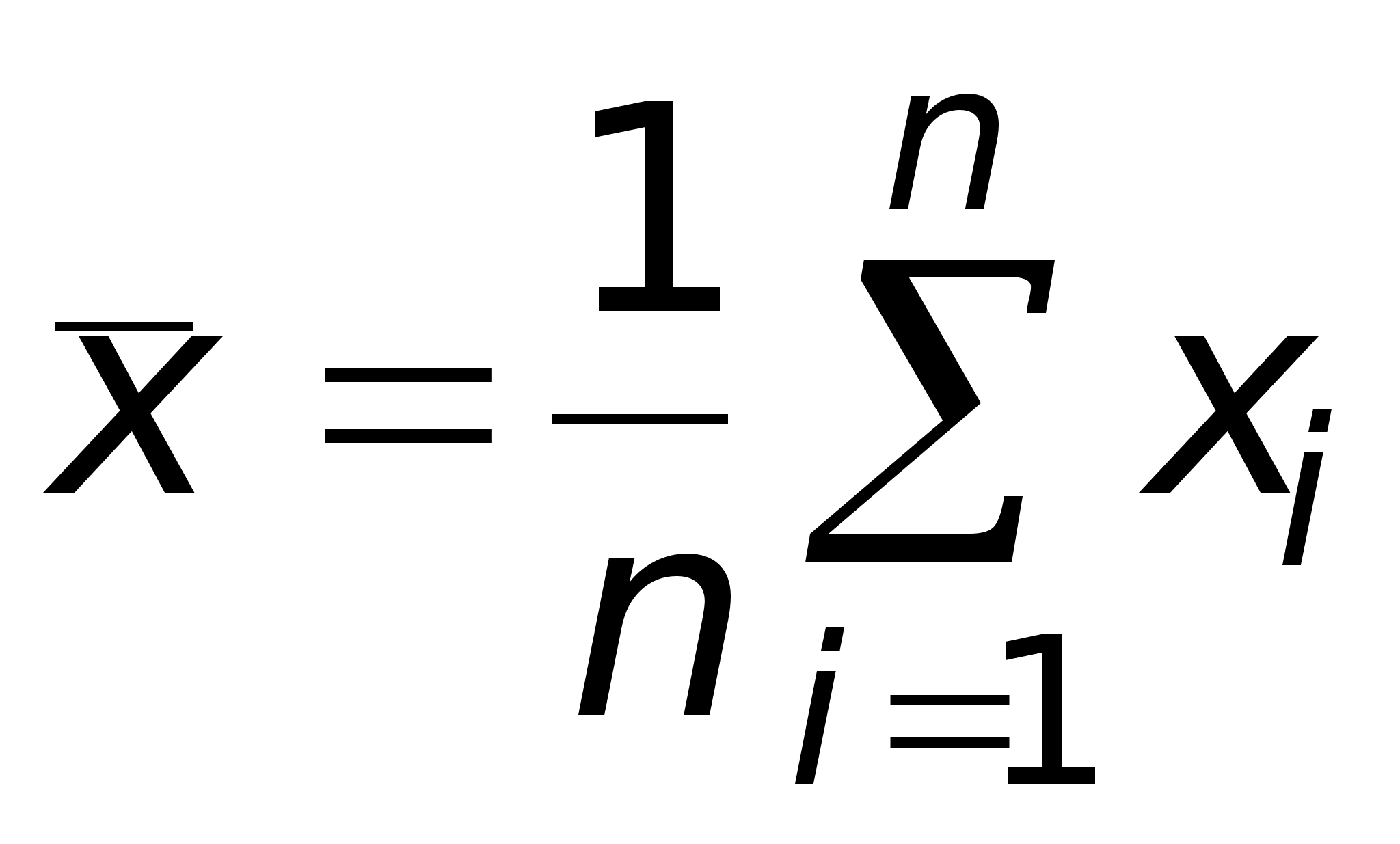 .
.
Естественно
считать величину
![]() выборочной
оценкой параметра
Mx.
Выборочная
оценка параметра,
представляющая
собой число,
называется
точечной оценкой.
выборочной
оценкой параметра
Mx.
Выборочная
оценка параметра,
представляющая
собой число,
называется
точечной оценкой.
Выборочную дисперсию
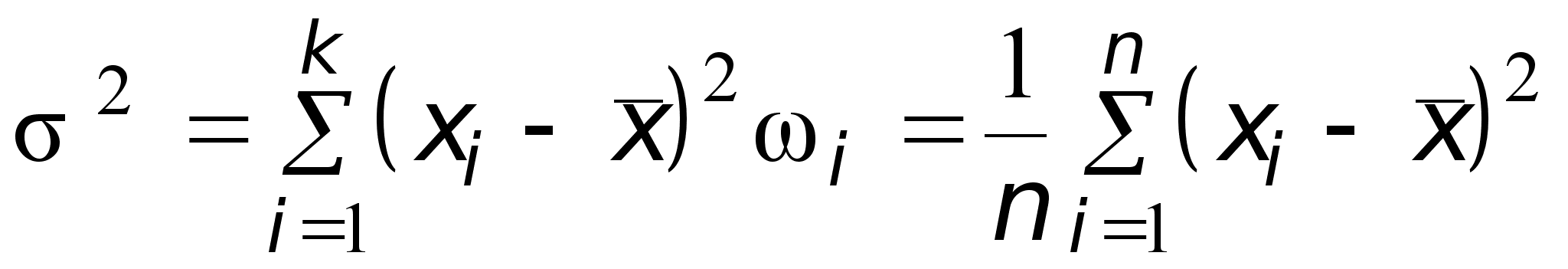
можно считать точечной оценкой дисперсии Dx генеральной совокупности.
Приведем еще один пример точечной оценки. Пусть каждый объект генеральной совокупности характеризуется двумя количественными признаками x и y. Например деталь может иметь два размера – длину и ширину. Можно в различных районах измерять концентрацию вредных веществ в воздухе и фиксировать количество легочных заболеваний населения в месяц. Можно через равные промежутки времени сопоставлять доходность акций данной корпорации с каким-либо индексом, характеризующим среднюю доходность всего рынка акций. В этом случае генеральная совокупность представляет собой двумерную случайную величину x, h. Эта случайная величина принимает значения x, y на множестве объектов генеральной совокупности. Не зная закона совместного распределения случайных величин x и h, мы не можем говорить о наличии или глубине корреляционной связи между ними, однако некоторые выводы можно сделать, используя выборочный метод.
Выборку
объема n
в этом случае
представим
в виде таблицы,
где
i-тый
отобранный
объект (i=
1,2,...n)
представлен
парой чисел
xi,
yi
:
|
x1 |
x2 |
... |
xn |
|
y1 |
y2 |
... |
yn |
Выборочный коэффициент корреляции рассчитывается по формуле
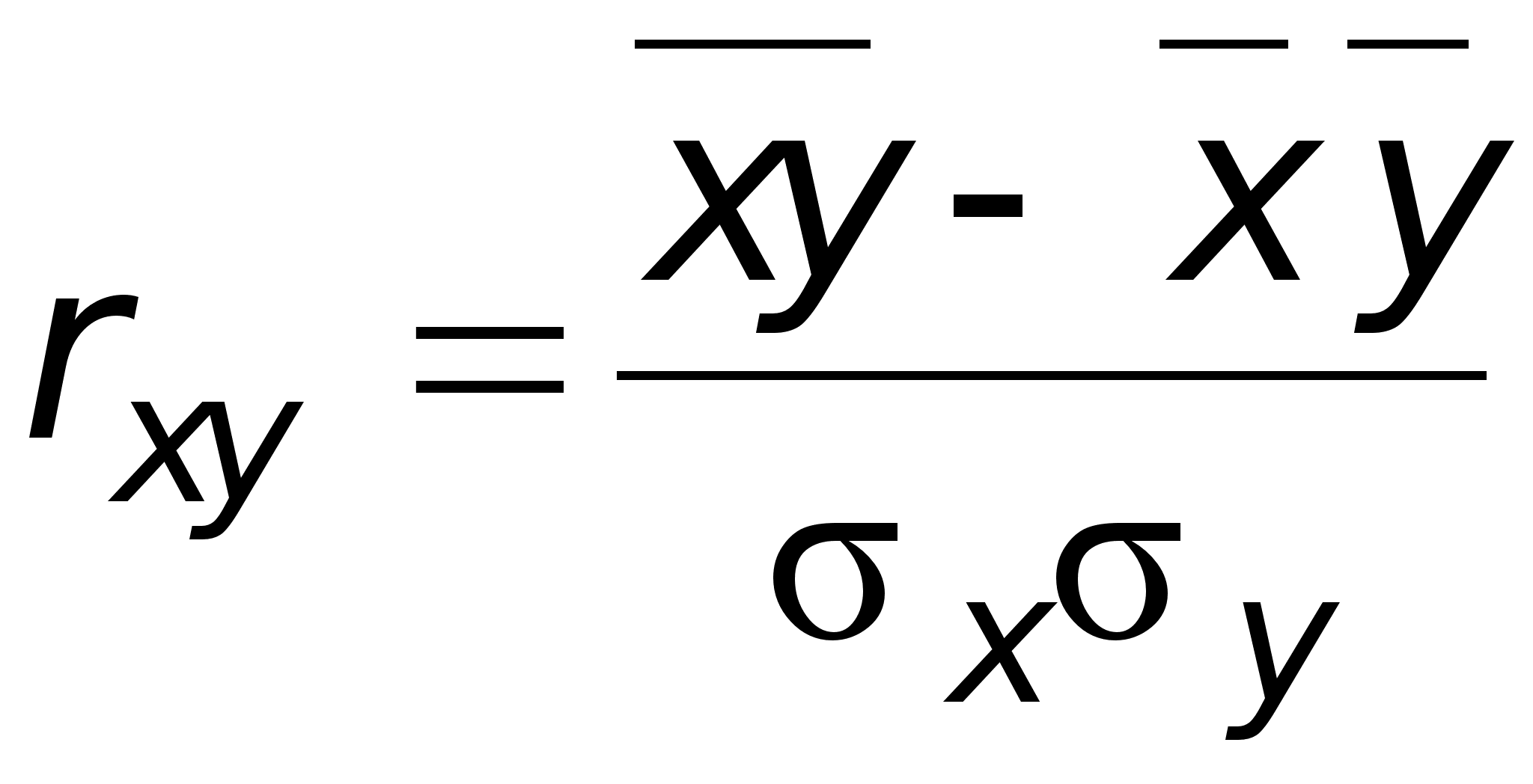
Здесь
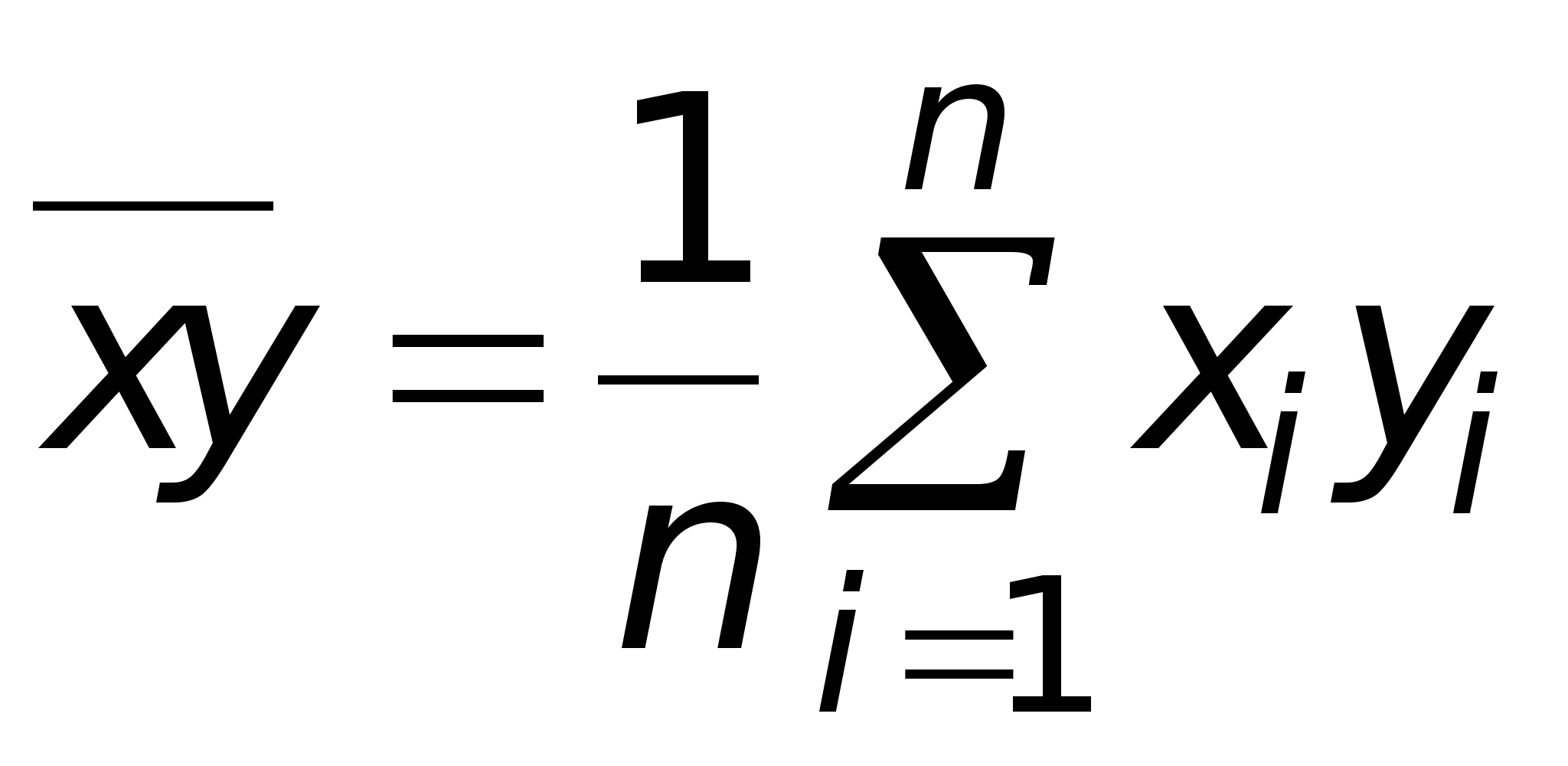 ,
,
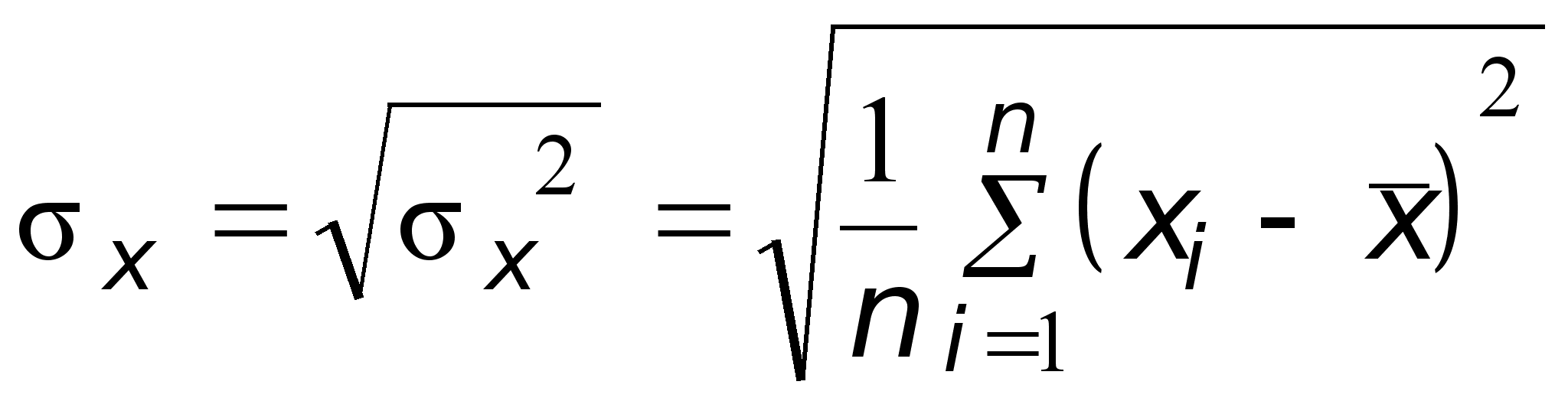 ,
,
 .
.
Выборочный коэффициент корреляции можно рассматривать как точечную оценку коэффициента корреляции rxh, характеризующего генеральную совокупность.
Выборочные
параметры
![]() или любые другие
зависят от
того, какие
объекты генеральной
совокупности
попали в выборку
и различаются
от выборки к
выборке. Поэтому
они сами являются
случайными
величинами.
или любые другие
зависят от
того, какие
объекты генеральной
совокупности
попали в выборку
и различаются
от выборки к
выборке. Поэтому
они сами являются
случайными
величинами.
Пусть выборочный параметр d рассматривается как выборочная оценка параметра D генеральной совокупности и при этом выполняется равенство
Md =D.
Такая выборочная оценка называется несмещенной.
Для
доказательства
несмещённости
некоторых
точечных оценок
будем рассматривать
выборку объема
n как
систему n
независимых
случайных
величин x1,
x2,...
xn
, каждая из которых
имеет тот же
закон распределения
с теми же параметрами,
что и случайная
величина x,
представляющая
генеральную
совокупность.
При таком подходе
становятся
очевидными
равенства:
Mxi = Mxi =Mx;
Dxi
= Dxi
=Dx
для всех k
= 1,2,...n.
Теперь
можно показать,
что выборочная
средняя
![]() есть несмещенная
оценка средней
генеральной
совокупности
или , что то же
самое, математического
ожидания интересующей
нас случайной
величины x
:
есть несмещенная
оценка средней
генеральной
совокупности
или , что то же
самое, математического
ожидания интересующей
нас случайной
величины x
:
![]() .
.
Выведем формулу для дисперсии выборочной средней:
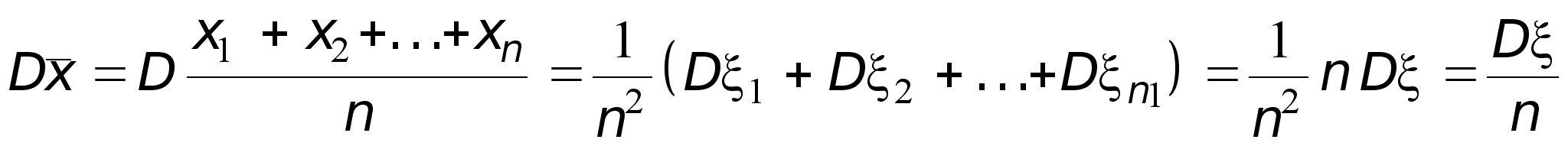 .
.
Найдем теперь, чему равно математическое ожидание выборочной дисперсии s 2. Сначала преобразуем s 2 следующим образом:
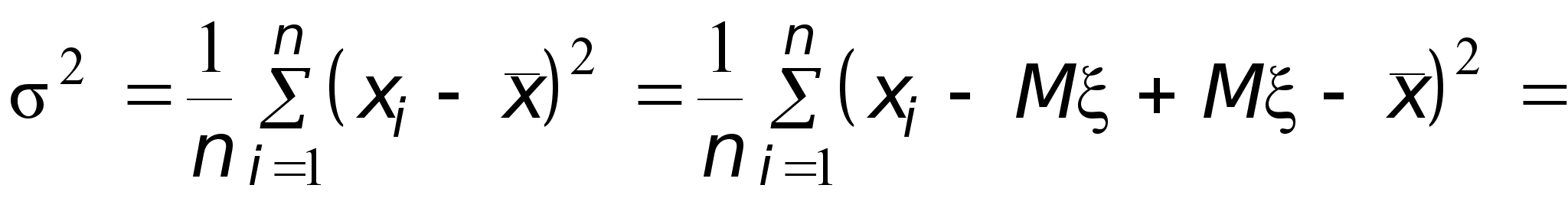
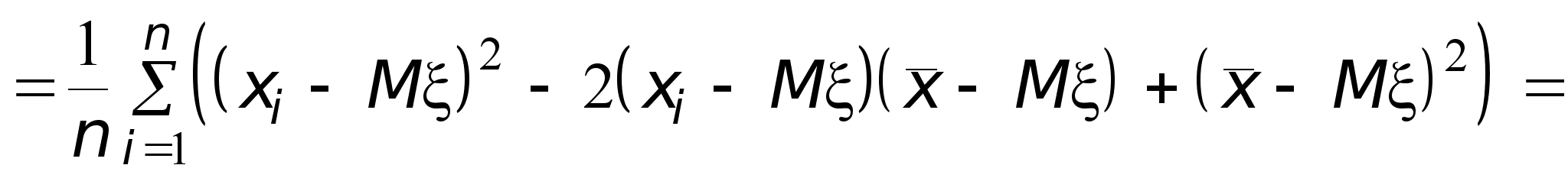
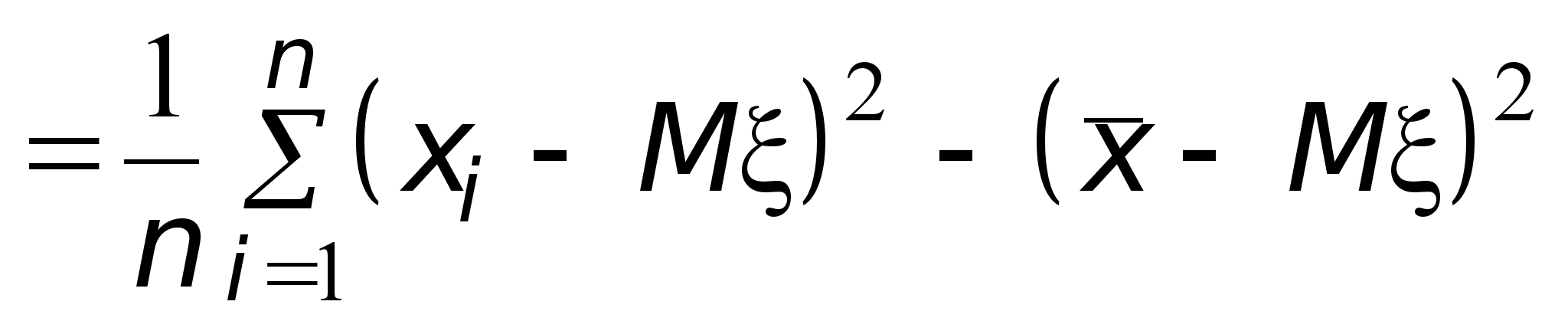
Здесь использовано преобразование:
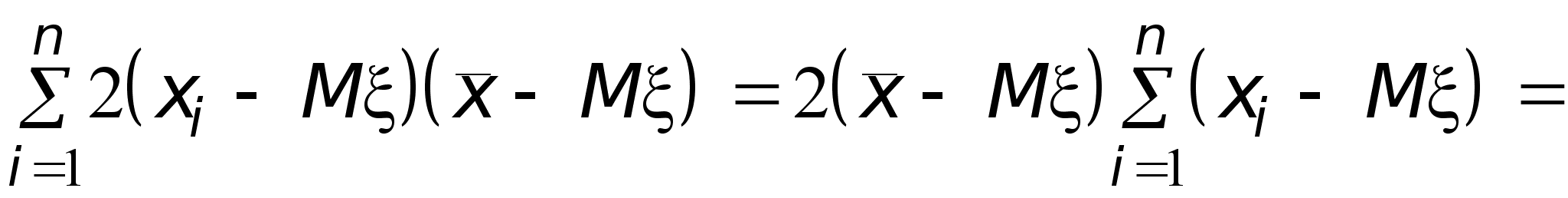

Теперь, используя полученное выше выражение для величины s 2, найдем ее математическое ожидание.
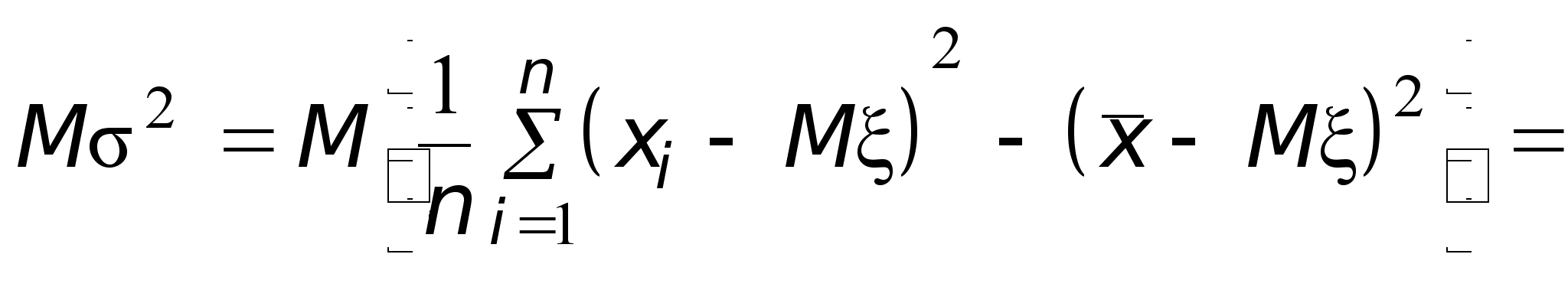

![]() .
.
Так как Ms 2 № Dx, выборочная дисперсия не является несмещенной оценкой дисперсии генеральной совокупности.
Чтобы
получить несмещенную
оценку дисперсии
генеральной
совокупности,
нужно умножить
выборочную
дисперсию на
![]() .
Тогда получится
величина
.
Тогда получится
величина
![]() ,
называемая
исправленнойвыборочнойдисперсией.
,
называемая
исправленнойвыборочнойдисперсией.
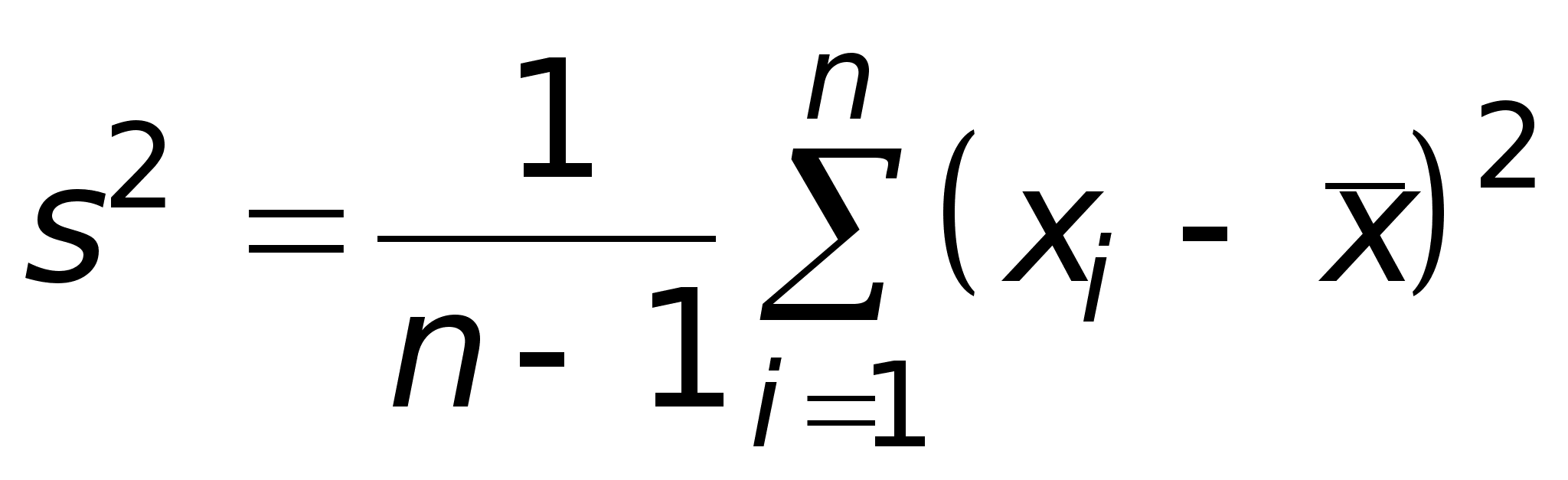
Пусть имеется ряд несмещенных точечных оценок одного и того же параметра генеральной совокупности. Та оценка, которая имеет наименьшую дисперсию называется эффективной.
Полученная
из выборки
объема n
точечная оценка
dn
параметра D
генеральной
совокупности
называется
состоятельной,
если она сходится
по вероятности
к D.
Это означает,
что для любых
положительных
чисел e
и g
найдется такое
число neg
, что для всех
чисел n,
удовлетворяющих
неравенству
n > neg
выполняется
условие![]() .
.
![]() и
и
![]() являются
несмещёнными,
состоятельными
и эффективными
оценками величин
Mx
и Dx.
являются
несмещёнными,
состоятельными
и эффективными
оценками величин
Mx
и Dx.
11
Лекция 12.
Интервальные оценки.
Точечные оценки параметров генеральной совокупности могут быть приняты в качестве ориентировочных, первоначальных результатов обработки выборочных данных. Их недостаток заключается в том, что неизвестно, с какой точностью оценивается параметр. Если для выборок большого объема точность обычно бывает достаточной (при условии несмещенности, эффективности и состоятельности оценок), то для выборок небольшого объема вопрос точности оценок становится очень важным.
Введем понятие интервальной оценки неизвестного параметра генеральной совокупности (или случайной величины , определенной на множестве объектов этой генеральной совокупности). Обозначим этот параметр через . По сделанной выборке по определенным правилам найдем числа 1 и 2, так чтобы выполнялось условие:
P(1< < 2) =P ((1; 2)) =
Числа 1 и 2 называются доверительными границами, интервал (1, 2) — доверительным интервалом для параметра . Число называется доверительной вероятностью или надежностью сделанной оценки.
Сначала задается надежность. Обычно ее выбирают равной 0.95, 0.99 или 0.999. Тогда вероятность того, что интересующий нас параметр попал в интервал (1, 2) достаточно высока. Число (1 + 2) / 2 – середина доверительного интервала – будет давать значение параметра с точностью (2 – 1) / 2, которая представляет собой половину длины доверительного интервала.
Границы 1 и 2 определяются из выборочных данных и являются функциями от случайных величин x1, x2,..., xn , а следовательно – сами случайные величины. Отсюда – доверительный интервал (1, 2) тоже случаен. Он может покрывать параметр или нет. Именно в таком смысле нужно понимать случайное событие, заключающееся в том, что доверительный интервал покрывает число .
Доверительный интервал для математического ожидания нормального распределения при известной дисперсии.
Пусть случайная величина (можно говорить о генеральной совокупности) распределена по нормальному закону, для которого известна дисперсия D = 2 ( > 0). Из генеральной совокупности (на множестве объектов которой определена случайная величина) делается выборка объема n. Выборка x1, x2,..., xn рассматривается как совокупность n независимых случайных величин, распределенных так же как (подход, которому дано объяснение выше по тексту).
Ранее также обсуждались и доказаны следующие равенства:
Mx1 = Mx2 = ... = Mxn = M;
Dx1 = Dx2 = ... = Dxn = D;
![]() M;
M;
![]() D
/n;
D
/n;
Достаточно
просто доказать
(мы доказательство
опускаем), что
случайная
величина
![]() в данном случае
также распределена
по нормальному
закону.
в данном случае
также распределена
по нормальному
закону.
Обозначим неизвестную величину M через a и подберем по заданной надежности число d > 0 так, чтобы выполнялось условие:
P(![]() –
a
< d) =
(1)
–
a
< d) =
(1)
Так
как случайная
величина
![]() распределена
по нормальному
закону с математическим
ожиданием M
распределена
по нормальному
закону с математическим
ожиданием M![]() = M
= a и
дисперсией
D
= M
= a и
дисперсией
D![]() = D
/n =
2/n,
получаем:
= D
/n =
2/n,
получаем:
P(![]() –
a
< d)
=P(a
– d <
–
a
< d)
=P(a
– d <
![]() < a +
d) =
< a +
d) =
=
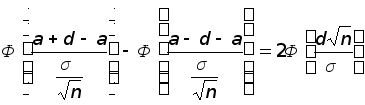
Осталось
подобрать d
таким, чтобы
выполнялось
равенство
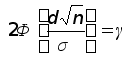 или
или
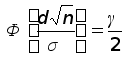 .
.
Для
любого
[0;1]
можно по таблице
найти такое
число t,
что
(
t )=
/ 2. Это число
t иногда
называют квантилем.
Теперь из равенства
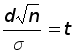
определим
значение d:
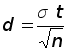 .
.
Окончательный результат получим, представив формулу (1) в виде:
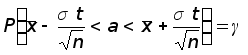 .
.
Смысл последней формулы состоит в следующем: с надежностью доверительный интервал
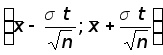
покрывает
неизвестный
параметр a
= M
генеральной
совокупности.
Можно сказать
иначе: точечная
оценка
![]() определяет
значение параметра
M
с точностью
d=
t /
определяет
значение параметра
M
с точностью
d=
t /![]() и надежностью
.
и надежностью
.
Задача.
Пусть имеется
генеральная
совокупность
с некоторой
характеристикой,
распределенной
по нормальному
закону с дисперсией,
равной 6,25. Произведена
выборка объема
n = 27 и
получено
средневыборочное
значение
характеристики
![]() =
12. Найти доверительный
интервал, покрывающий
неизвестное
математическое
ожидание исследуемой
характеристики
генеральной
совокупности
с надежностью
=
12. Найти доверительный
интервал, покрывающий
неизвестное
математическое
ожидание исследуемой
характеристики
генеральной
совокупности
с надежностью
=0,99.
Решение.
Сначала по
таблице для
функции Лапласа
найдем значение
t из
равенства
(t) =
/ 2 = 0,495.
По полученному
значению
t
= 2,58 определим
точность оценки
(или половину
длины доверительного
интервала) d:
d =
2,52,58 / ![]()
1,24. Отсюда получаем
искомый доверительный
интервал: (10,76;
13,24).
1,24. Отсюда получаем
искомый доверительный
интервал: (10,76;
13,24).
Доверительный интервал для математического ожидания нормального распределения при неизвестной дисперсии.
Пусть
– случайная
величина,
распределенная
по нормальному
закону с неизвестным
математическим
ожиданием M,
которое обозначим
буквой a
. Произведем
выборку объема
n. Определим
среднюю выборочную
![]() и исправленную
выборочную
дисперсию s2
по известным
формулам.
и исправленную
выборочную
дисперсию s2
по известным
формулам.
Случайная величина
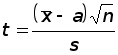
распределена по закону Стьюдента с n – 1 степенями свободы.
Задача заключается в том, чтобы по заданной надежности и по числу степеней свободы n – 1 найти такое число t , чтобы выполнялось равенство
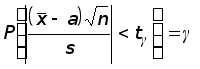 (2)
(2)
или эквивалентное равенство
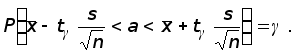 (3)
(3)
Здесь в
скобках написано
условие того,
что значение
неизвестного
параметра a
принадлежит
некоторому
промежутку,
который и является
доверительным
интервалом.
Его границы
зависят от
надежности
, а также от
параметров
выборки
![]() и s.
и s.
Чтобы определить значение t по величине , равенство (2) преобразуем к виду:

Теперь по таблице для случайной величины t, распределенной по закону Стьюдента, по вероятности 1 – и числу степеней свободы n – 1 находим t . Формула (3) дает ответ поставленной задачи.
Задача. На контрольных испытаниях 20-ти электроламп средняя продолжительность их работы оказалась равной 2000 часов при среднем квадратическом отклонении (рассчитанном как корень квадратный из исправленной выборочной дисперсии), равном 11-ти часам. Известно, что продолжительность работы лампы является нормально распределенной случайной величиной. Определить с надежностью 0,95 доверительный интервал для математического ожидания этой случайной величины.
Решение.
Величина 1 –
в данном
случае равна
0,05. По таблице
распределения
Стьюдента, при
числе степеней
свободы, равном
19, находим: t
= 2,093. Вычислим
теперь точность
оценки: 2,093121/![]() = 56,6. Отсюда получаем
искомый доверительный
интервал:
= 56,6. Отсюда получаем
искомый доверительный
интервал:
(1943,4; 2056,6).
Доверительный интервал для дисперсии нормального распределения.
Пусть случайная величина распределена по нормальному закону, для которого дисперсия D неизвестна. Делается выборка объема n . Из нее определяется исправленная выборочная дисперсия s2. Случайная величина
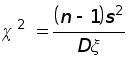
распределена по закону 2 c n –1 степенями свободы. По заданной надежности можно найти сколько угодно границ 12 и 22 интервалов, таких, что
![]() (*)
(*)
Найдем 12 и 22 из следующих условий:
P(2 12) = (1 – )/ 2 (**)
P(2 22) = (1 – )/ 2 (***)
Очевидно, что при выполнении двух последних условий справедливо равенство (*).
В таблицах для случайной величины 2 обычно дается решение уравнения P(2 q2) = q . Из такой таблицы по заданной величине q и по числу степеней свободы n – 1 можно определить значение q2. Таким образом, сразу находится значение 22 в формуле (***).
Для определения 12 преобразуем (**):
P(2 12) = 1 – (1 – )/ 2 = (1 + )/ 2
Полученное равенство позволяет определить по таблице значение 12.
Теперь, когда найдены значения 12 и 22, представим равенство (*) в виде
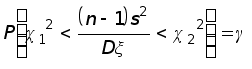 .
.
Последнее
равенство
перепишем в
такой форме,
чтобы были
определены
границы доверительного
интервала для
неизвестной
величины
D:
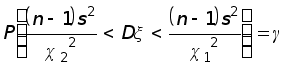 .
.
Отсюда легко получить формулу, по которой находится доверительный интервал для стандартного отклонения:
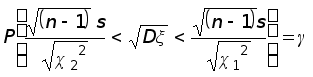 (****)
(****)
Задача. Будем считать, что шум в кабинах вертолетов одного и того же типа при работающих в определенном режиме двигателях — случайная величина, распределенная по нормальному закону. Было случайным образом выбрано 20 вертолетов, и произведены замеры уровня шума (в децибелах) в каждом из них. Исправленная выборочная дисперсия измерений оказалась равной 22,5. Найти доверительный интервал, накрывающий неизвестное стандартное отклонение величины шума в кабинах вертолетов данного типа с надежностью 98%.
Решение.
По числу степеней
свободы, равному
19, и по вероятности
(1 – 0,98)/2 = 0,01 находим
из таблицы
распределения
2
величину
22 = 36,2.
Аналогичным
образом при
вероятности
(1 + 0,98)/2 = 0,99 получаем
12 = 7,63.
Используя
формулу (****), получаем
искомый доверительный
интервал: (3,44;
7,49).
8
Лекция 13.
Задачи статистической проверки гипотез.
Статистическая проверка гипотез является вторым после статистического оценивания параметров распределения и в то же время важнейшим разделом математической статистики.
Методы математической статистики позволяют проверить предположения о законе распределения некоторой случайной величины (генеральной совокупности), о значениях параметров этого закона (например M, D ), о наличии корреляционной зависимости между случайными величинами, определенными на множестве объектов одной и той же генеральной совокупности.
Пусть по некоторым данным имеются основания выдвинуть предположения о законе распределения или о параметре закона распределения случайной величины (или генеральной совокупности, на множестве объектов которой определена эта случайная величина). Задача заключается в том, чтобы подтвердить или опровергнуть это предположение, используя выборочные (экспериментальные) данные.
Гипотезы о значениях параметров распределения или о сравнительной величине параметров двух распределений называются параметрическими гипотезами.
Гипотезы о виде распределения называются непараметрическими гипотезами.
Проверить статистическую гипотезу – это значит проверить, согласуются ли данные, полученные из выборки с этой гипотезой. Проверка осуществляется с помощью статистического критерия. Статистический критерий – это случайная величина, закон распределения которой (вместе со значениями параметров) известен в случае, если принятая гипотеза справедлива. Этот критерий называют еще критерием согласия (имеется в виду согласие принятой гипотезы с результатами, полученными из выборки).
Гипотезу, выдвинутую для проверки ее согласия с выборочными данными, называют нулевой гипотезой и обозначают H0. Вместе с гипотезой H0 выдвигается альтернативная или конкурирующая гипотеза, которая обозначается H1. Например:
| 1) |
H0: M= 0 |
2) |
H0: M= 0 |
3) |
H0: M= 0 |
|
H1: M 0 |
H1: M> 0 |
H1: M= 2 |
Пусть случайная величина K – статистический критерий проверки некоторой гипотезы H0. При справедливости гипотезы H0 закон распределения случайной величины K характеризуется некоторой известной нам плотностью распределения pK(x).
Выберем некоторую малую вероятность , равную 0,05 , 0,01 или еще меньшую. Определим критическое значение критерия Kкр как решение одного из трех уравнений, в зависимости от вида нулевой и конкурирующей гипотез:
P(K> Kкр) = (1)
P(K< Kкр) = (2)
P((K< Kкр1)(K> Kкр2)) = (3)
Возможны и другие уравнения, но они встречаются значительно реже, чем приведенные.
Решение уравнения (1) (то же самое для уравнений (2) и (3)) заключается в следующем: по вероятности , зная функцию pK(x), заданную как правило таблицей, нужно определить Kкр.
Что означает условие (1)?
Если гипотеза H0 справедлива, то вероятность того, что критерий K превзойдет некоторое значение Kкр очень мала – 0,05 , 0,01 или еще меньше, в зависимости от нашего выбора. Если Kв – значение критерия K, рассчитанное по выборочным данным, превзошло значение Kкр, это означает, что выборочные данные не дают основания для принятия нулевой гипотезы H0 ( например, если =0,01 , то можно сказать, что произошло событие, которое при справедливости гипотезы H0 встречается в среднем не чаще, чем в одной из ста выборок). В этом случае говорят, что гипотеза H0 несогласуется с выборочными данными и должна быть отвергнута. Если Kв не превосходит Kкр, то говорят, что выборочные данные непротиворечат гипотезе H0, и нет оснований отвергать эту гипотезу.
Для уравнения (1) область K> Kкр называется критической областью. Если значение Kв попадает в критическую область, то гипотеза H0 отвергается.
Для уравнения (1) область K < Kкр называется областьюпринятия гипотезы. Если значение Kв попадает в область принятия гипотезы, то гипотеза H0 принимается.
Пусть выбрано некоторое малое значение вероятности , по нему определено значение Kкр и по выборочным данным определено значение Kв, которое попало в критическую область. В этом случае гипотеза H0 отвергается, но она может оказаться справедливой, просто случайно произошло событие, которое имеет очень малую вероятность . В этом смысле есть вероятность отвержения правильной гипотезы H0.
Отвержение правильной гипотезы называется ошибкой первогорода. Вероятность называется уровнем значимости. Таким образом уровень значимости – это вероятность совершения ошибки первого рода.
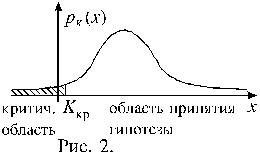
Уравнение (2) определяет левосторонюю критическую область. Ее изображение приводится на рисунке 2.
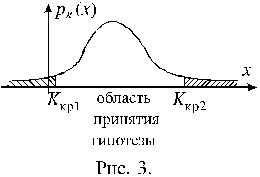
Уравнение (3) определяет двусторонюю критическую область. Такая область изображена на рисунке 3. Здесь критическая область состоит из двух частей. В случае двусторонней критической области границы ее частей Kкр1 и Kкр2 определяются таким образом, чтобы выполнялось условие:
P(K Kкр) = P(K Kкр) = / 2.
На рисунке 3. площадь каждой из заштрихованных фигур равна / 2.
Вид критической области зависит от того, какая гипотеза выдвинута в качестве конкурирующей.
Чем меньше уровень значимости, тем меньше вероятность отвергнуть проверяемую гипотезу H0, когда она верна, то есть совершить ошибку первого рода. Но с уменьшением уровня значимости расширяется область принятия гипотезы H0 и увеличивается вероятность принятия проверяемой гипотезы, когда она неверна, то есть когда предпочтение должно быть отдано конкурирующей гипотезе.
Пусть при справедливости гипотезы H0 статистический критерий K имеет плотность распределения p0(x), а при справедливости конкурирующей гипотезы H1 – плотность распределения p1(x). Графики этих функций приведены на рисунке 4. При некотором уровне значимости находится критическое значение Kкр и правостороняя критическая область. Если значение Kв, определенное по выборочным данным, оказывается меньше, чем Kкр, то гипотеза H0 принимается. Предположим, что справедлива на самом деле конкурирующая гипотеза H1. Тогда вероятность попадания критерия в область принятия гипотезы H0 есть некоторое число , равное площади фигуры, образованной графиком функции p1(x) и полубесконечной частью горизонтальной координатной оси, лежащей слева от точки Kкр. Очевидно, что – это вероятность того, что будет принята неверная гипотеза H0.
Принятие неверной гипотезы называется ошибкой второго рода. В рассмотренном случае число – это вероятность ошибки второго рода. Число 1 – , равное вероятности того, что не совершается ошибка второгорода, называется мощностью критерия. На рисунке 4 мощность критерия равна площади фигуры, образованной графиком функции p1(x).и полубесконечной частью горизонтальной координатной оси, лежащей справа от точки Kкр.
Выбор статистического критерия и вида критической области осуществляется таким образом, чтобы мощность критерия была максимальной.
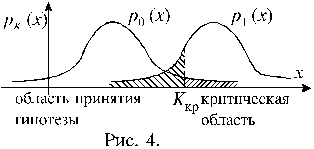
6
Лекция 14.
Проверка статистической гипотезы о математическом ожидании нормального распределения при известной дисперсии.
Пусть имеется нормально распределенная случайная величина ,, определенная на множестве объектов некоторой генеральной совокупности. Известно, что D = 2. Математическое ожидание M неизвестно. Допустим, что имеются основания предполагать, что M = a, где a – некоторое число (такими основаниями могут быть ограниченные сведения об объектах генеральной совокупности, опыт исследования подобных совокупностей и т. д.). Будем считать также, что имеется другая информация, указывающая на то, что M = a1, где a1 > a.
I. Выдвигаем нулевую гипотезу H0: M = a;
при конкурирующей гипотезе H1: M = a1.
Делаем
выборку объема
n: x1,
x2,...,
xn .
В основе проверки
лежит тот факт,
что случайная
величина
![]() (выборочная
средняя) распределена
по нормальному
закону с дисперсией
2/n
и математическим
ожиданием,
равным a
в случае справедливости
H0,
и равным a1
в случае справедливости
H1.
(выборочная
средняя) распределена
по нормальному
закону с дисперсией
2/n
и математическим
ожиданием,
равным a
в случае справедливости
H0,
и равным a1
в случае справедливости
H1.
Очевидно,
что если величина
![]() оказывается
достаточно
малой, то это
дает основание
предпочесть
гипотезу H0
гипотезе H1.
При достаточно
большом значении
оказывается
достаточно
малой, то это
дает основание
предпочесть
гипотезу H0
гипотезе H1.
При достаточно
большом значении
![]() более вероятна
справедливость
гипотезы H1.
Задачу можно
было бы поставить
так: требуется
найти некоторое
критическое
число, которое
разбивало бы
все возможные
значения выборочной
средней ( в условиях
данной задачи
это все действительные
числа ) на два
полубесконечных
промежутка.
При попадании
более вероятна
справедливость
гипотезы H1.
Задачу можно
было бы поставить
так: требуется
найти некоторое
критическое
число, которое
разбивало бы
все возможные
значения выборочной
средней ( в условиях
данной задачи
это все действительные
числа ) на два
полубесконечных
промежутка.
При попадании
![]() в левый промежуток
следовало бы
принимать
гипотезу H0,
а при попадании
в левый промежуток
следовало бы
принимать
гипотезу H0,
а при попадании
![]() в правый промежуток
предпочтение
следовало бы
оказать гипотезе
H1.
Однако на самом
деле поступают
несколько
иначе.
в правый промежуток
предпочтение
следовало бы
оказать гипотезе
H1.
Однако на самом
деле поступают
несколько
иначе.
В качестве статистического критерия выбирается случайная величина
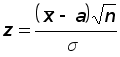 ,
,
распределенная
по нормальному
закону , причем
Mz = 0 и
Dz = 1 (
это следует
из свойств
математического
ожидания и
дисперсии ) в
случае справедливости
гипотезы H0.
Если справедлива
гипотеза H1,
то
Mz
= a* = (
a1
– a
)![]() /,
Dz = 1.
/,
Dz = 1.
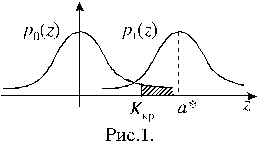
Если
величина
![]() ,
полученная
из выборочных
данных, относительно
велика, то и
величина z
велика, что
является
свидетельством
в пользу гипотезы
H1.
Относительно
малые значения
,
полученная
из выборочных
данных, относительно
велика, то и
величина z
велика, что
является
свидетельством
в пользу гипотезы
H1.
Относительно
малые значения
![]() приводят к
малым значениям
z, что
свидетельствует
в пользу гипотезы
H0.
Отсюда следует,
что должна быть
выбрана правосторонняя
критическая
область. По
принятому
уровню значимости
(например
= 0,05), используя
то, что случайная
величина z
распределена
по нормальному
закону, определим
значение Kкр
из формулы
приводят к
малым значениям
z, что
свидетельствует
в пользу гипотезы
H0.
Отсюда следует,
что должна быть
выбрана правосторонняя
критическая
область. По
принятому
уровню значимости
(например
= 0,05), используя
то, что случайная
величина z
распределена
по нормальному
закону, определим
значение Kкр
из формулы
= P(Kкр < z ) = () – (Kкр) = 0,5 – (Kкр).
Отсюда
![]() ,
и осталось
воспользоваться
таблицей функции
Лапласа для
нахождения
числа Kкр.
,
и осталось
воспользоваться
таблицей функции
Лапласа для
нахождения
числа Kкр.
Если
величина z,
полученная
при выборочном
значении
![]() ,
попадает в
область принятия
гипотезы (z < Kкр),
то гипотеза
H0
принимается
(делается вывод,
что выборочные
данные не
противоречат
гипотезе H0).
Если величина
z попадает
в критическую
область, то
гипотеза H0
отвергается.
,
попадает в
область принятия
гипотезы (z < Kкр),
то гипотеза
H0
принимается
(делается вывод,
что выборочные
данные не
противоречат
гипотезе H0).
Если величина
z попадает
в критическую
область, то
гипотеза H0
отвергается.
В данной задаче может быть подсчитана мощность критерия:
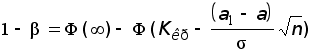
Мощность критерия тем больше, чем больше разность a1– a.
II. Если в предыдущей задаче поставить другое условие:
H0: M = a;
H1: M = a1 , a1 < a,
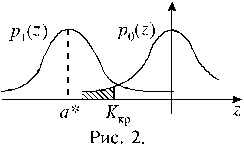
= P(–
< z <
Kкр)
= (
Kкр)
– (–)
= (
Kкр)
+
![]() .
.
Используя формулу –( Kкр) = ( –Kкр), получаем:
(
–Kкр)
=
![]() .
.
Отметим, что по смыслу задачи здесь Kкр – отрицательное число.
Значения z, вычисленные по выборочным данным, превышающие Kкр, согласуются с гипотезой H0. Если величина z попадает в критическую область (z < Kкр), то гипотезу H0 следует отвергнуть, считая предпочтительной гипотезу H1.
III. Рассмотрим теперь такую задачу:
H0: M = a;
H1: M a.
Критическое значение Kкр определяется с помощью соотношения
P(–Kкр < z < Kкр) = 1 – = ( Kкр) – ( – Kкр) = 2( Kкр) .
Из этого соотношения следует:
(
Kкр)
=
![]()
Проверка гипотезы о равенстве дисперсий.
Гипотезы о дисперсии играют очень важную роль в экономико–математическом моделировании, так как величина рассеяния экспериментальных выборочных данных относительно рассчитанных теоретических значений соответствующих параметров, характеризующаяся дисперсией, дает возможность судить о пригодности (адекватности) теории или модели, на основании которой строится теория.
Пусть нормально распределенная случайная величина определена на некотором множестве, образующем генеральную совокупность, а нормально распределенная случайная величина определена на другом множестве, которое тоже составляет генеральную совокупность. Из обеих совокупностей делаются выборки: из первой – объема n1, а из второй – объема n2 (отметим, что объем выборки не всегда можно определить заранее, как например в случае, если он равен количеству рыб, попавших в сеть). По каждой выборке рассчитывается исправленная выборочная дисперсия: s12 для выборки из первой совокупности и s22 для выборки из второй совокупности.
Поставим задачу: с помощью выборочных данных проверить статистическую гипотезу H0: D = D. В качестве конкурирующей гипотезы будем рассматривать идею, заключающуюся в том, что дисперсия той совокупности, для которой исправленная выборочная дисперсия оказалась наибольшей, больше дисперсии другой совокупности. Критерий берется в следующем виде:
![]() .
.
Здесь S**– наибольшая из двух оценок s12 и s22, а S*– наименьшая из тех же двух оценок.
Критерий F распределен по закону Фишера с k1 и k2 степенями свободы. Здесь
k1 = n1–1, k2 = n2–1, если S**= s12;
k1 = n2–1, k2 = n1–1, если S**= s22.
В этой задаче естественно рассматривать правостороннюю критическую область, так как достаточно большие выборочные значения критерия F свидетельствуют в пользу конкурирующей гипотезы.
При заданном уровне значимости q (обычно q =0,05 или q =0,01) критическое значение Fкр определяется из таблицы распределения Фишера. В случае F > Fкр гипотеза H0 отвергается, а в случае F < Fкр – принимается.
Пусть два множества некоторых объектов, обладающих количественным признаком, подвергнуты выборочному контролю. Значения количественного признака есть распределенные по нормальному закону случайные величины, которые мы обозначим 1 и 2, соответственно, для первого и для второго множеств. Из первого множества сделана выборка объема n1=21 и подсчитана исправленная выборочная дисперсия, оказавшаяся равной 0,75. Из второго множества сделана выборка объема n2=11. Эта выборка дала значение исправленной выборочной дисперсии, равное 0,25. Выдвигаем гипотезу H0: D1=D2. Конкурирующая гипотеза H1 заключается в том, что D1>D2. В данном случае выборочное значение Fв критерия Фишера равно 3. При выбранном уровне значимости q = 0,05 по числам степеней свободы k1=20, k2=10 находим по таблице распределения Фишера Fкр=2,77. Так как Fв > Fкр, гипотеза о равенстве дисперсий должна быть отвергнута.
Проверка статистической значимости выборочного коэффициента корреляции.
Проверкой
статистической
значимости
выборочной
оценки
параметра
генеральной
совокупности
называется
проверкастатистической
гипотезы
H0:
= 0, при конкурирующей
гипотезе
H1:
0. Если гипотеза
H0
отвергается,
то оценка
считается
статистически
значимой.
Пусть имеются две случайные величины и , определенные на множестве объектов одной и той же генеральной совокупности, причем обе имеют нормальное распределение. Задача заключается в проверке статистической гипотезы об отсутствии корреляционной зависимости между случайными величинами и .
H0: = 0;
H1: 0.
Здесь – коэффициент линейной корреляции.
Производится выборка объема n и вычисляется выборочный коэффициент корреляции r. За статистический критерий принимается случайная величина
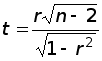 ,
,
которая распределена по закону Стьюдента с n – 2 степенями свободы.
Отметим сначала, что все возможные значения выборочного коэффициента корреляции r лежат в промежутке [–1;1]. Очевидно, что относительно большие отклонения в любую сторону значений t от нуля получаются при относительно больших, то есть близких к 1, значениях модуля r. Близкие к 1 значения модуля r противоречат гипотезе H0, поэтому здесь естественно рассматривать двустороннюю критическую область для критерия t.
По уровню значимости и по числу степеней свободы n – 2 находим из таблицы распределения Стьюдента значение tкр. Если модуль выборочного значения критерия tв превосходит tкр, то гипотеза H0 отвергается и выборочный коэффициент корреляции считается статистически значимым. В противном случае, то есть если tв < tкр и принимается гипотеза H0, выборочный коэффициент корреляции считается статистически незначимым.
7
4
Статистическое определение вероятности.
Рассмотрим случайный эксперимент, заключающийся в том, что подбрасывается игральная кость, сделанная из неоднородного материала. Ее центр тяжести не находится в геометрическом центре. В этом случае мы не можем считать исходы (выпадение единицы, двойки и т.д.) равновероятными. Из физики известно, что кость более часто будет падать на ту грань, которая ближе к центру тяжести. Как определить вероятность выпадения, например, трех очков? Единственное, что можно сделать, это подбросить эту кость n раз (где n-достаточно большое число, скажем n=1000 или n=5000), подсчитать число выпадений трех очков n3 и считать вероятность исхода, заключающегося в выпадении трех очков, равной n3/n - относительной частоте выпадения трех очков. Аналогичным образом можно определить вероятности остальных элементарных исходов — единицы, двойки, четверки и т.д. Теоретически такой образ действий можно оправдать, если ввести статистическое определение вероятности.
Вероятность P(i) определяется как предел относительной частоты появления исхода i в процессе неограниченного увеличения числа случайных экспериментов n, то есть
![]() ,
,
где mn(i) – число случайных экспериментов (из общего числа n произведенных случайных экспериментов), в которых зарегистрировано появление элементарного исхода i.
Так как здесь не приводится никаких доказательств, мы можем только надеяться, что предел в последней формуле существует, обосновывая надежду жизненным опытом и интуицией.
Геометрическая вероятность
В одном специальном случае дадим определение вероятности события для случайного эксперимента с несчетным множеством исходов.
Если между множеством элементарных исходов случайного эксперимента и множеством точек некоторой плоской фигуры (сигма большая) можно установить взаимно-однозначное соответствие, а также можо установить взаимно-однозначное соответствие между множеством элементарных исходов, благоприятствующих событию А, и множеством точек плоской фигуры (сигма малая), являющейся частью фигуры , то
![]() ,
,
где s — площадь фигуры , S — площадь фигуры .
Пример. Два человека обедают в столовой, которая открыта с 12 до 13 часов. Каждый из них приходит в произвольный момент времени и обедает в течение 10 минут. Какова вероятность их встречи?
Пусть
x
— время прихода
первого в столовую,
а
y
— время прихода
второго
![]() .
.
Рис.6
Можно установить взаимно-однозначное соответствие между всеми парами чисел (x;y) (или множеством исходов) и множеством точек квадрата со стороной, равной 1, на координатной плоскости, где начало координат соответствует числу 12 по оси X и по оси Y, как изображено на рисунке 6. Здесь, например, точка А соответствует исходу, заключающемуся в том, что первый пришел в 12.30, а второй - в 13.00. В этом случае, очевидно, встреча не состоялась.Если первый пришел не позже второго (y x), то встреча произойдет при условии 0 y - x 1/6 (10 мин.- это 1/6 часа).
Между множеством исходов, благоприятствующих встрече, и множеством точек области , изображенной на рисунке 7 в заштрихованном виде, можно установить взаимно-однозначное cоответствие.
Рис. 7
Искомая вероятность p равна отношению площади области к площади всего квадрата.. Площадь квадрата равна единице, а площадь области можно определить как разность единицы и суммарной площади двух треугольников, изображенных на рисунке 7. Отсюда следует:
![]()
Непрерывное вероятностное пространство.
Как уже говорилось ранее, множество элементарных исходов может быть более, чем счетным (то есть несчетным). В этом случае нельзя считать любое подмножество множества W событием.
Чтобы
ввести определение
случайного
события, рассмотрим
систему (конечную
или счетную)
подмножеств
![]() пространства
элементарных
исходов W.
пространства
элементарных
исходов W.
В случае выполнения трех условий:
1) W принадлежит этой системе;
2)
из принадлежности
А
этой системе
следует принадлежность
![]() этой системе;
этой системе;
3)
из принадлежности![]() и
и
![]() этой системе
следует принадлежность
Ai
U
Aj
этой
системе
этой системе
следует принадлежность
Ai
U
Aj
этой
системе
такая система подмножеств называется алгеброй.
Пусть W — некоторое пространство элементарных исходов. Убедитесь в том, что две системы подмножеств:
1)
W,
Ж;
2) W,
А,
![]() ,
Ж
(здесь А—
подмножество )
являются алгебрами.
,
Ж
(здесь А—
подмножество )
являются алгебрами.
Пусть A1 и A2 принадлежат некоторой алгебре. Докажите, что A1 \ A2 и A1∩ A2 принадлежат этой алгебре.
Подмножество А несчетного множества элементарных исходов W является событием, если оно принадлежит некоторой алгебре.
Сформулируем аксиому, называемую аксиомой А.Н. Колмогорова.
Каждому событию соответствует неотрицательное и не превосходящее единицы число P(А), называемое вероятностью события А, причем функция P(А) обладает следующими свойствами:
1) Р(W)=1
2) если события A1, A2,..., An несовместны, то
P(A1UA2U...UAn) = P (A1) + P (A2) +...+ P(An)
Если задано пространство элементарных исходов W, алгебра событий и определенная на ней функция Р, удовлетворяющая условиям приведенной аксиомы, то говорят, что задано вероятностное пространство.
Это определение вероятностного пространства можно перенести на случай конечного пространства элементарных исходов W. Тогда в качестве алгебры можно взять систему всех подмножеств множества W.
Формулы сложения вероятностей.
Из пункта 2 приведенной аксиомы следует, что если A1 и A2 несовместные события, то
P(A1UA2) = P(A1) + P(A2)
Если A1 и A2 — совместные события, то A1UA2 =(A1\ A2)UA2, причем очевидно, что A1\A2 и A2 — несовместные события. Отсюда следует:
P(A1UA2) = P(A1\ A2) + P(A2) (*)
Далее очевидно: A1 = (A1\ A2)U(A1∩A2), причем A1\ A2 и A1∩A2 - несовместные события, откуда следует: P(A1) = P(A1\ A2) + P(A1∩A2) Найдем из этой формулы выражение для P(A1\ A2) и подставим его в правую часть формулы (*). В результате получим формулу сложения вероятностей:
P(A1UA2) = P(A1) + P(A2) – P(A1∩A2)
Из последней формулы легко получить формулу сложения вероятностей для несовместных событий, положив A1∩A2 = .
Пример. Найти вероятность вытащить туза или червовую масть при случайном отборе одной карты из колоды в 32 листа.
Р( ТУЗ ) = 4/32 = 1/8; Р( ЧЕРВОВАЯ МАСТЬ ) = 8/32 = 1/4;
Р( ТУЗ ЧЕРВЕЙ ) = 1/32;
Р(( ТУЗ ) U (ЧЕРВОВАЯ МАСТЬ )) = 1/8 + 1/4 - 1/32 =11/32
Того же результата можно было достичь с помощью классического определения вероятности, пересчитав число благоприятных исходов.
Условные вероятности.
Рассмотрим задачу. Студент перед экзаменом выучил из 30 билетов билеты с номерами с 1 по 5 и с 26 по 30. Известно, что студент на экзамене вытащил билет с номером, не превышающим 20. Какова вероятность, что студент вытащил выученный билет?
Определим пространство элементарных исходов: =(1,2,3,...,28,29,30). Пусть событие А заключается в том, что студент вытащил выученный билет: А = (1,...,5,25,...,30,), а событие В — в том, что студент вытащил билет из первых двадцати: В = (1,2,3,...,20)
Событие А∩В состоит из пяти исходов: (1,2,3,4,5), и его вероятность равна 5/30. Это число можно представить как произведение дробей 5/20 и 20/30. Число 20/30 - это вероятность события B. Число 5/20 можно рассматривать как вероятность события А при условии, что событие В произошло (обозначим её Р(А/В)). Таким образом решение задачи определяется формулой
P(А∩В) = Р(А/В) Р(B)
Эта формула называется формулой умножения вероятностей , а вероятность Р(А/В) — условной вероятностью события A.
Пример..Из урны, содержащей 7 белых и 3 черных шаров, наудачу один за другим извлекают (без возвращения) два шара. Какова вероятность того, что первый шар будет белым, а второй черным?
Пусть X — событие, состоящее в извлечении первым белого шара, а Y — событие, состоящее в извлечении вторым черного шара. Тогда X∩Y - событие, заключающееся в том, что первый шар будет белым, а второй — черным. P(Y/X) =3/9 =1/3 — условная вероятность извлечения вторым черного шара, если первым был извлечен белый. Учитывая, что P(X) = 7/10, по формуле умножения вероятностей получаем: P(X∩Y) = 7/30
Событие А называется независимым от события В (иначе: события А и В называются независимыми), если Р(А/В)=Р(А). За определение независимых событий можно принять следствие последней формулы и формулы умножения
P(А∩В) = Р(А) Р(B)
Докажите
самостоятельно,
что если А
и В
— независимые
события, то
![]() и
и
![]() тоже являются
независимыми
события.
тоже являются
независимыми
события.
Пример.Рассмотрим задачу, аналогичную предыдущей, но с одним дополнительным условием: вытащив первый шар, запоминаем его цвет и возвращаем шар в урну, после чего все шары перемешиваем. В данном случае результат второго извлечения никак не зависит от того, какой шар - черный или белый появился при первом извлечении. Вероятность появления первым белого шара (событие А) равна 7/10. Вероятность события В - появления вторым черного шара - равна 3/10. Теперь формула умножения вероятностей дает: P(А∩В) = 21/100.
Извлечение шаров способом, описанным в этом примере, называется выборкой с возвращением или возвратной выборкой.
Следует отметить, что если в двух последних примерах положить изначальные количества белых и черных шаров равными соответственно 7000 и 3000, то результаты расчетов тех же вероятностей будут отличаться пренебрежимо мало для возвратной и безвозвратной выборок.
Лекция 3
Формула полной вероятности.
Пусть имеется группа событий H1, H2,..., Hn , обладающая следующими свойствами:
1) Все события попарно несовместны: Hi ∩ Hj =Ж; i, j=1,2,...,n; i№j
2) Их объединение образует пространство элементарных исходов :
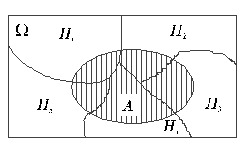
Рис.8
В этом случае будем говорить, что H1, H2,...,Hn образуют полную группу событий. Такие события иногда называют гипотезами.Пусть А - некоторое событие: А (диаграмма Венна представлена на рисунке 8). Тогда имеет место формула полной вероятности:
P(A)
= P(A/
H1)P(H1)
+ P(A/
H2)P(H2)
+ ...+ P(A/
Hn)P(Hn)
=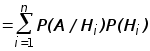
Доказательство. Очевидно: A = (A∩H1) U (A∩H2) U...U (A∩Hn), причем все события A∩Hi (i = 1,2,...,n) попарно несовместны. Отсюда по теореме сложения вероятностей получаем
P(A) = P(A∩H1) + P(A∩H1) +...+P(A∩Hn )
Если учесть, что по теореме умножения P(A∩Hi) = P(A/Hi) P(Hi) (i = 1,2,...,n), то из последней формулы легко получить приведенную выше формулу полной вероятности.
Пример. В магазине продаются электролампы производства трех заводов, причем доля первого завода - 30%, второго - 50%, третьего - 20%. Брак в их продукции составляет соответственно 5%, 3% и 2%. Какова вероятность того, что случайно выбранная в магазине лампа оказалась бракованной.
Пусть событие H1 состоит в том, что выбранная лампа произведена на первом заводе, H2 на втором, H3 - на третьем заводе. Очевидно:
P(H1) = 3/10, P(H2) = 5/10, P(H3) = 2/10.
Пусть событие А состоит в том, что выбранная лампа оказалась бракованной; A/Hi означает событие, состоящее в том, что выбранна бракованная лампа из ламп, произведенных на i-ом заводе. Из условия задачи следует:
P (A/H1) = 5/10; P(A/H2) = 3/10; P(A/H3) = 2/10
По формуле полной вероятности получаем
![]()
Формула Байеса
Пусть H1,H2,...,Hn - полная группа событий и А - некоторое событие. Тогда по формуле для условной вероятности
![]() (*)
(*)
Здесь P(Hk /A) - условная вероятность события (гипотезы) Hk или вероятность того, что Hk реализуется при условии, что событие А произошло.
По теореме умножения вероятностей числитель формулы (*) можно представить в виде
P(Hk∩A) = P(A∩Hk) = P(A /Hk) P(Hk)
Для представления знаменателя формулы (*) можно использовать формулу полной вероятности
P(A)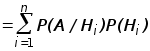
Теперь из (*) можно получить формулу, называемую формулой Байеса:
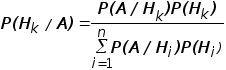
По формуле Байеса исчисляется вероятность реализации гипотезы Hk при условии, что событие А произошло. Формулу Байеса еще называют формулой вероятности гипотез.
Пример.Рассмотрим приведенную выше задачу об электролампах, только изменим вопрос задачи. Пусть покупатель купил электролампу в этом магазине, и она оказалась бракованной. Найти вероятность того, что эта лампа изготовлена на втором заводе.
Выпишем формулу Байеса для этого случая
![]()
Из этой формулы получаем: P(H2 / A) = 15/34
Предлагаем читателю решить самостотельно две задачи.
.№1.В первой урне 7 белых и 3 черных шара, во второй - 8 белых и 2 черных. Из первой урны случайным образом извлекается шар и перекладывается во вторую урну. После перемешивания шаров во второй урне из нее извлекается один шар. Найти вероятность того, что извлеченный из второй урны шар — белый.
№2.В условие задачи №1 внесем изменение. Пусть после перекладывания шара из первой урны во вторую из второй урны извлечен белый шар. Найти вероятность того, что из первой урны во вторую был переложен черный шар.
Повторные независимые испытания. Формула Бернулли.
Рассмотрим случай многократного повторения одного и того же испытания или случайного эксперимента. Результат каждого испытания будем считать не зависящим от того, какой результат наступил в предыдущих испытаниях. В качестве результатов или элементарных исходов каждого отдельного испытания будем различать лишь две возможности:
1) появление некоторого события А;
2)
появление
события
![]() ,
(события, являющегося
дополнением
А)
,
(события, являющегося
дополнением
А)
Пусть вероятность
P(A)
появления
события А
постоянна и
равна p
(0.p1).
Вероятность
P(![]() )
события
)
события
![]() обозначим через
q: P(
обозначим через
q: P(![]() )
= 1- p=q.
)
= 1- p=q.
Примерами таких испытаний могут быть:
1)
подбрасывание
монеты: А
- выпадение
герба;
![]() - выпадение
цифры.
- выпадение
цифры.
P(A)
= P(![]() )
= 0,5.
)
= 0,5.
2)
бросание игральной
кости: А - выпадение
количества
очков, равного
пяти,
![]() выпадение
любого количества
очков кроме
пяти.
выпадение
любого количества
очков кроме
пяти.
P(A)
=1/6, P(![]() )
=5/6.
)
=5/6.
3)
извлечение
наудачу из
урны, содержащей
7 белых и 3 черных
шара, одного
шара (с возвращением):
А -
извлечение
белого шара,
![]() - извлечение
черного шара
- извлечение
черного шара
P(A)
= 0,7; P(![]() )
= 0,3
)
= 0,3
Пусть произведено
n
испытаний,
которые мы
будем рассматривать
как один сложный
случайный
эксперимент.
Составим таблицу
из n
клеток, расположенных
в ряд, пронумеруем
клетки, и результат
каждого испытания
будем отмечать
так: если в i-м
испытании
событие А
произошло, то
в i-ю
клетку ставим
цифру 1, если
событие А
не произошло
(произошло
событие![]() ),
в i-ю
клетку ставим
0.
),
в i-ю
клетку ставим
0.
Если, например, проведено 5 испытаний, и событие А произошло лишь во 2 -м и 5-м испытаниях, то результат можно записать такой последовательностью нулей и единиц: 0; 1; 0; 0; 1.
Каждому
возможному
результату
n
испытаний будет
соответствовать
последовательность
n цифр
1 или 0, чередующихся
в том порядке,
в котором появляются
события A
и
![]() в n
испытаниях,
например:
в n
испытаниях,
например:
1; 1; 0; 1; 0; 1; 0; 0; ... 0; 1; 1; 0
n цифр
Всего таких
последовательностей
можно составить
![]() (это читатель
может доказать
сам).
(это читатель
может доказать
сам).
Так как
испытания
независимы,
то вероятность
P каждого
такого результата
определяется
путем перемножения
вероятностей
событий A
и
![]() в соответствующих
испытаниях.
Так, например,
для написанного
выше результата
найдем
в соответствующих
испытаниях.
Так, например,
для написанного
выше результата
найдем
P = ppqpqpqq...qppq
Если в написанной нами последовательности единица встречается х раз (это значит, что нуль встречается n-x раз), то вероятность соответствующего результата будет pnqn-x независимо от того, в каком порядке чередуются эти x единиц и n-x нулей.
Все события,
заключающиеся
в том, что в n
испытаниях
событие A
произошло x
раз, а событие
![]() произошло n-x
раз, являются
несовместными.
Поэтому для
вычисления
вероятности
объединения
этих событий
(или суммы этих
событий), нужно
сложить вероятности
всех этих событий,
каждая из которых
равна pnqn-x
произошло n-x
раз, являются
несовместными.
Поэтому для
вычисления
вероятности
объединения
этих событий
(или суммы этих
событий), нужно
сложить вероятности
всех этих событий,
каждая из которых
равна pnqn-x
![]() .
Всего таких
событий можно
насчитать
столько, сколько
можно образовать
различных
последовательностей
длины n,
содержащих
x цифр
"1" и n-x
цифр "0". Таких
последовательностей
получается
столько, сколькими
способами можно
разместить
x цифр
"1" (или n-x
цифр "0") на n
местах, то есть
число этих
последовательностей
равно
.
Всего таких
событий можно
насчитать
столько, сколько
можно образовать
различных
последовательностей
длины n,
содержащих
x цифр
"1" и n-x
цифр "0". Таких
последовательностей
получается
столько, сколькими
способами можно
разместить
x цифр
"1" (или n-x
цифр "0") на n
местах, то есть
число этих
последовательностей
равно
![]()
Отсюда получается формула Бернулли:
Pn(x)
=
![]()
По
формуле Бернулли
рассчитывается
вероятность
появления
события A
"x"раз
в n
повторных
независимых
испытаниях,
где p
- вероятность
появления
события A
в одном испытании,
q -
вероятность
появления
события
![]() в одном испытании.
в одном испытании.
Сформулированные условия проведения испытаний иногда называются "схемой повторных независимых испытаний" или "схемой Бернулли"
Число x появления события A в n повторных независимых испытаниях называется частотой.
Пример. Из урны, содержащей 2 белых и 6 черных шаров наудачу выбирается с возвращением 5 раз подряд один шар. Подсчитать вероятность того, что 4 раза появится белый шар.
В приведенных выше обозначениях n=8; p=1/4; q=3/4; x=5. Искомую вероятность вычисляем по формуле Бернулли:
![]()
По формуле Бернулли можно подсчитать вероятности всех возможных частот: x=0,1,2,3,4,5.
Заметим, что если в этой задаче считать, что белых шаров было 20000, а черных 60000, то очевидно p и q останутся неизменными. Однако в этой ситуации можно пренебречь возвращением извлеченного шара после каждой выборки (при не слишком больших значениях x) и считать вероятности всех частот: x=0,1,2,... по формуле Бернулли.
Формула Бернулли при заданных числах p и n позволяет рассчитывать вероятность любой частоты x (0 x n). Возникает естественный вопрос: какой частоте будет соответствовать наибольшая вероятность?
Предположим, что такая частота существует, и попытаемся ее определить из условия, что вероятность этой частоты не меньше вероятности "предыдущей" и "последующей" частот:
Pn(x) Pn (x-1); Pn(x) Pn (x+1) (1)
Первое неравенство (*) представляется в виде:
![]() ,
,
что
эквивалентно
![]() или
или
![]() .
Отсюда следует:
.
Отсюда следует:
![]()
Решая второе неравенство (1), получим
![]()
Таким образом, частота, имеющая наибольшую вероятность (чем вероятнейшая частота), определяется двойным неравенством
![]()
Если np + p
– целое число
(тогда и np – q
– целое число),
то две частоты:
x=np – q
и x=np + p
обладают наибольшей
вероятностью.
Например, при
![]() ,
наивероятнейшие
частоты: x = 3;
x = 4.
,
наивероятнейшие
частоты: x = 3;
x = 4.
Случайная величина, распределенная по закону Бернулли.
При двух заданных числах:
1) n - количестве повторных независимых испытаний,
2) p - вероятности события A в одном испытании
можно
по формуле
Бернулли подсчитать
значение вероятности
каждого целого
числа x
![]() ,
где x
– число появлений
события A в n
испытаниях
(частота появления
события A).
,
где x
– число появлений
события A в n
испытаниях
(частота появления
события A).
Таким образом, каждому исходу случайного эксперимента, заключающегося в серии из n испытаний по схеме Бернулли, соответствует определенное число x, рассматриваемое как случайная величина, принимающая значения 0, 1, 2,...n. Соответствие между значениями x и их вероятностями (рассчитанными по формуле Бернулли) называется законом распределения Бернулли. Строгое определение случайной величины и закона распределения будет дано позже.
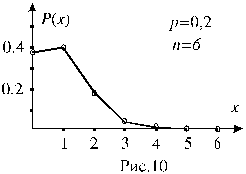
При
![]() ,
как показано
на рисунке 9,
полигон симметричен
относительно
прямой x=np
(если p
близко к 0,5, то
полигон близок
к симметричному)
,
как показано
на рисунке 9,
полигон симметричен
относительно
прямой x=np
(если p
близко к 0,5, то
полигон близок
к симметричному)
При малых p полигон существенно асимметричен, и наивероятнейшими являются частоты, бизкие к нулю. На рисунке 10 изображен полигон распределения для p=0,2 при числе испытаний n,равном 6-ти.
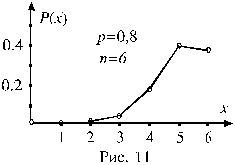
При больших p, близких к 1, наиболее вероятны максимальные значения. На рисунке 11 показан полигон распределения, для p=0,8 и n=6.
О других свойствах бернуллиевского распределения будет говориться позже.
6
Лекция 4
Асимптотические формулы для формулы Бернулли.
В
практических
задачах часто
приходится
вычислять
вероятности
различных
событий, связанных
с числом успехов
в n
испытаниях
при больших
значениях n.
В этих случаях
вычисления
по формуле по
формуле Бернулли
становятся
затруднительными.
Трудности
возрастают,
когда приходится
суммировать
вероятности
![]() .
К суммированию
сводится вычисление
вероятностей
событий вида
k Ј
xЈ
l,
как, например,
в такой задаче:
.
К суммированию
сводится вычисление
вероятностей
событий вида
k Ј
xЈ
l,
как, например,
в такой задаче:
Проводится 70 испытаний по схеме Бернулли с вероятностью появления события А в одном испытании, равной 0,4. Найти вероятность того, что событие А произойдет от 25 до 35 раз, то есть найти Pn(25Ј x Ј 35).
В
отдельных
случаях при
больших n удается
заменить формулу
Бернулли
приближенными
формулами.
Такие формулы,
которые получаются
при условии
![]() называются
асимптотическими.
называются
асимптотическими.
Если n достаточно велико, а p - величина очень малая, для формулы Бернулли имеет место приближенная (асимптотическая) формула
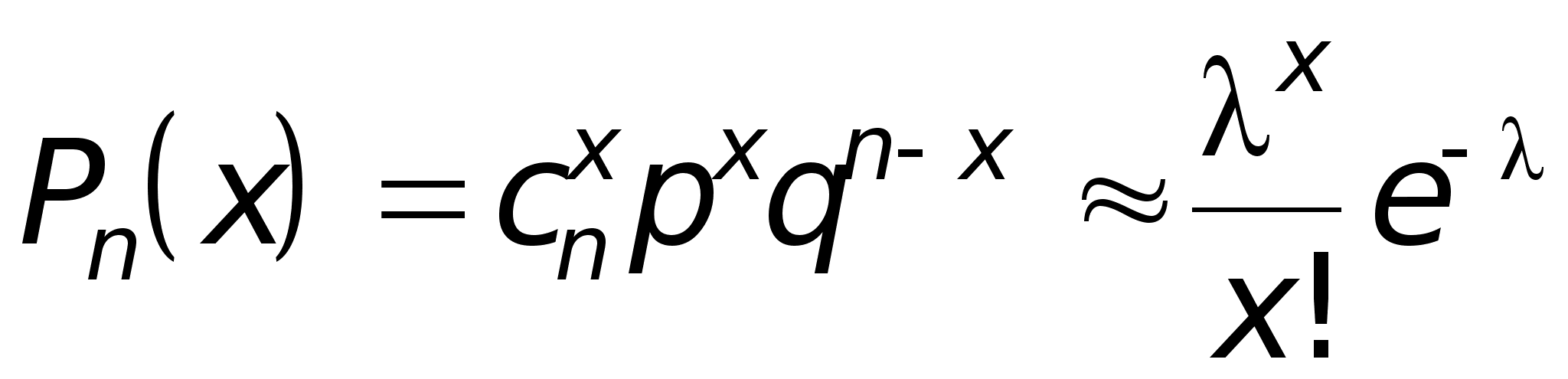
Здесь
![]() (
(![]() - греческая
буква "лямбда").
Эта формула
называется
формулой
Пуассона.
По формуле
Пуассона вычисляются
вероятности
числа появлений
очень редких
событий в массовых
испытаниях.
- греческая
буква "лямбда").
Эта формула
называется
формулой
Пуассона.
По формуле
Пуассона вычисляются
вероятности
числа появлений
очень редких
событий в массовых
испытаниях.
Задача. Телефонная станция обслуживает 1000 абонентов. В течение часа любой абонент независимо от остальных может сделать вызов с вероятностью 0,05. Требуется найти вероятность того, что в течение часа было не более 7 вызовов.
Здесь
![]() .
Пусть x
- число вызовов.
Нас интересуют
значения x,
равные
.
Пусть x
- число вызовов.
Нас интересуют
значения x,
равные![]()
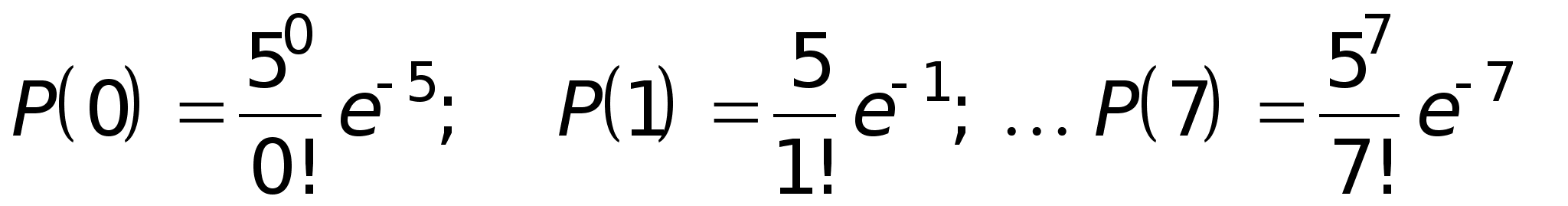
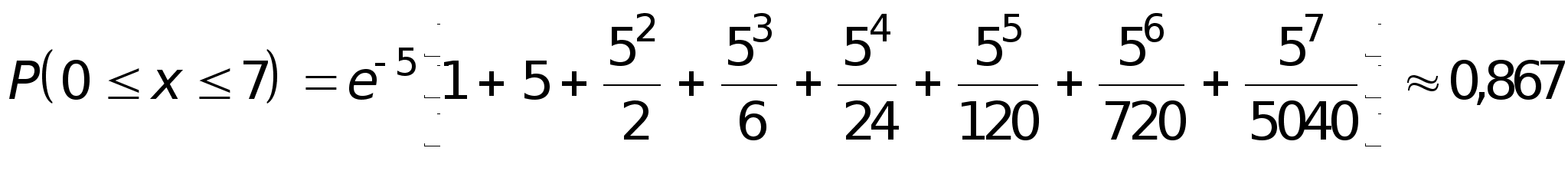
Если n достаточно велико, p не сильно отличается от 0,5, имеет место формула Муавра-Лапласа, иногда называемая локальной формулой Лапласа.
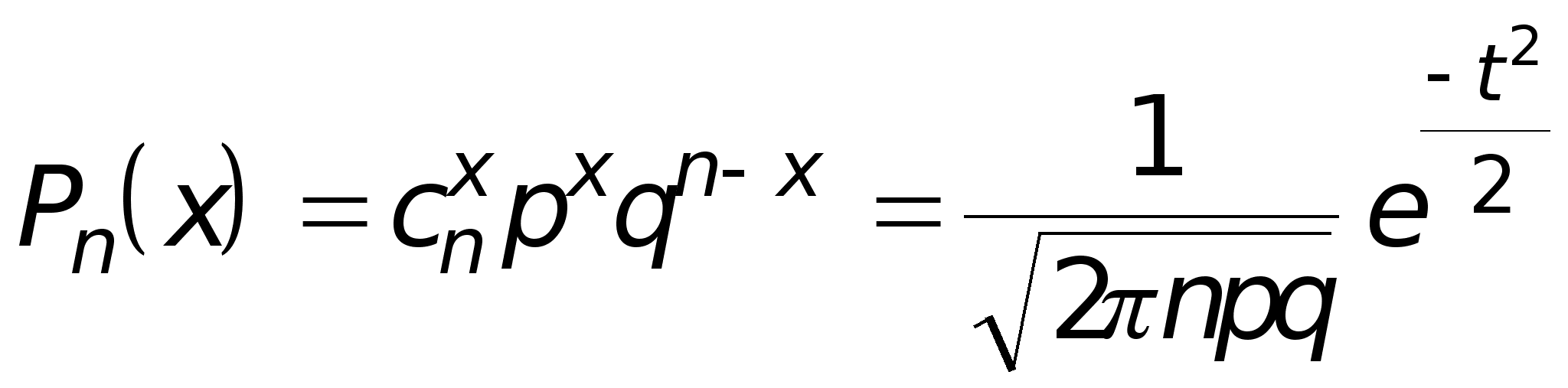 , где
, где

Из формулы видно, что одинаковые отклонения от величины np вправо и влево здесь имеют одинаковые вероятности. В формуле Бернулли это имеет место лишь при p=0.5.
Чтобы
определить
вероятность
того, что в 50
испытаниях
по схеме Бернулли
при p=0.45
событие А
наступило
30 раз, нужно
воспользоваться
таблицей значений
функции
![]() .
Часто встречаются
таблицы значений
так называемой
"локальной"
функции Лапласа.
.
Часто встречаются
таблицы значений
так называемой
"локальной"
функции Лапласа.
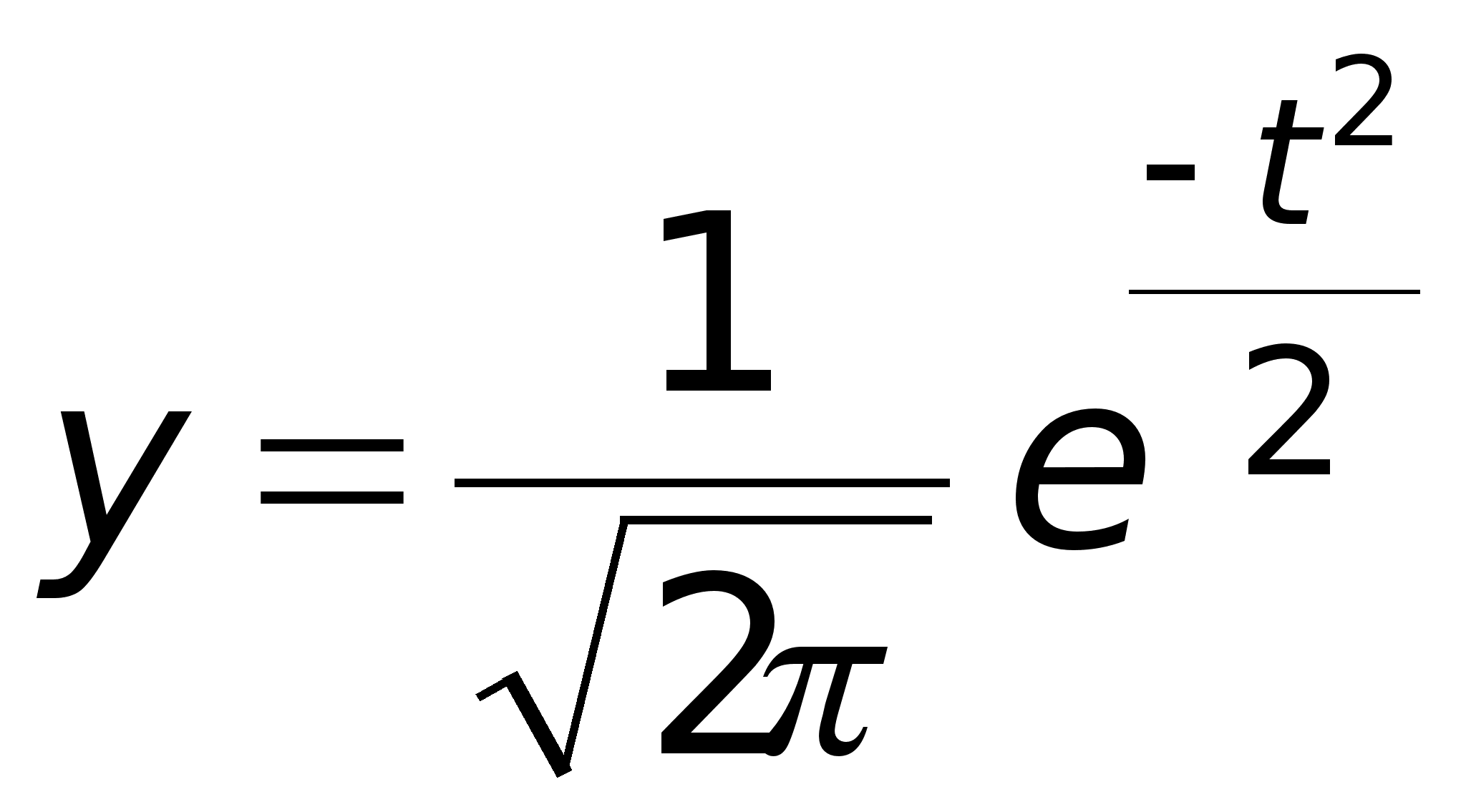
Если n достаточно велико, а p не сильно отличается от 0,5, имеет место интегральная формула Лапласа:
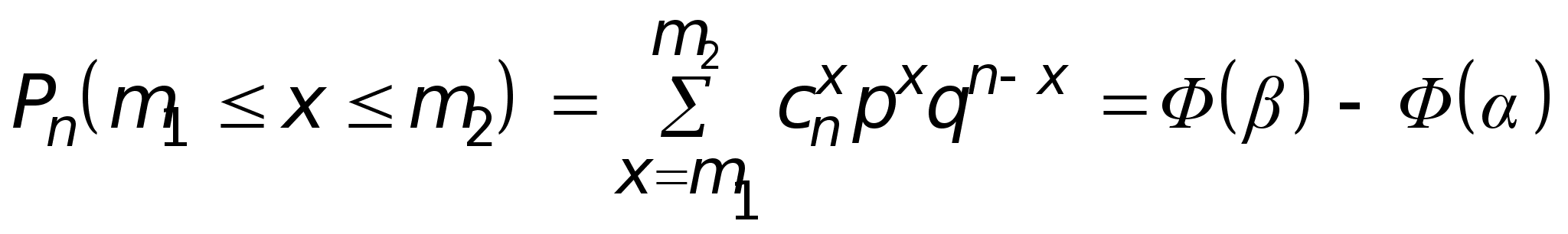
Здесь
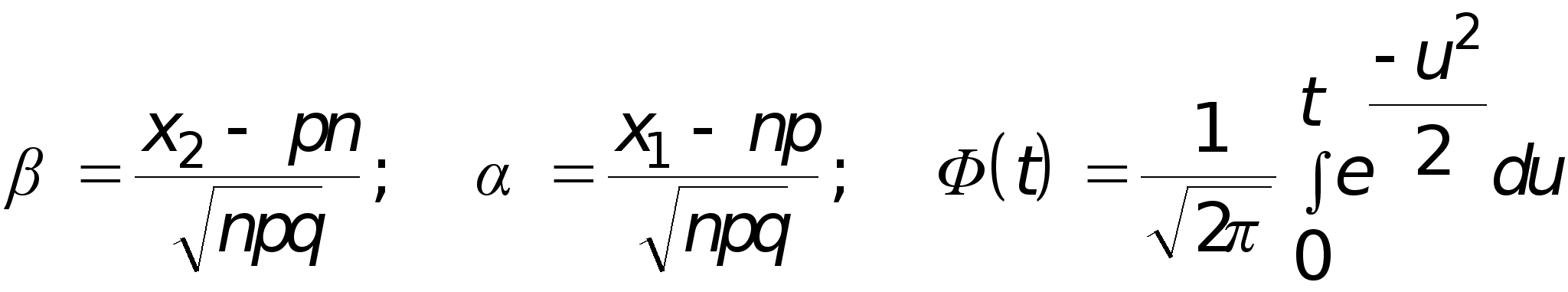 — функция Лапласа,
значения которой
определяются
из таблиц.
— функция Лапласа,
значения которой
определяются
из таблиц.
Для вычислений используются свойства функции Лапласа
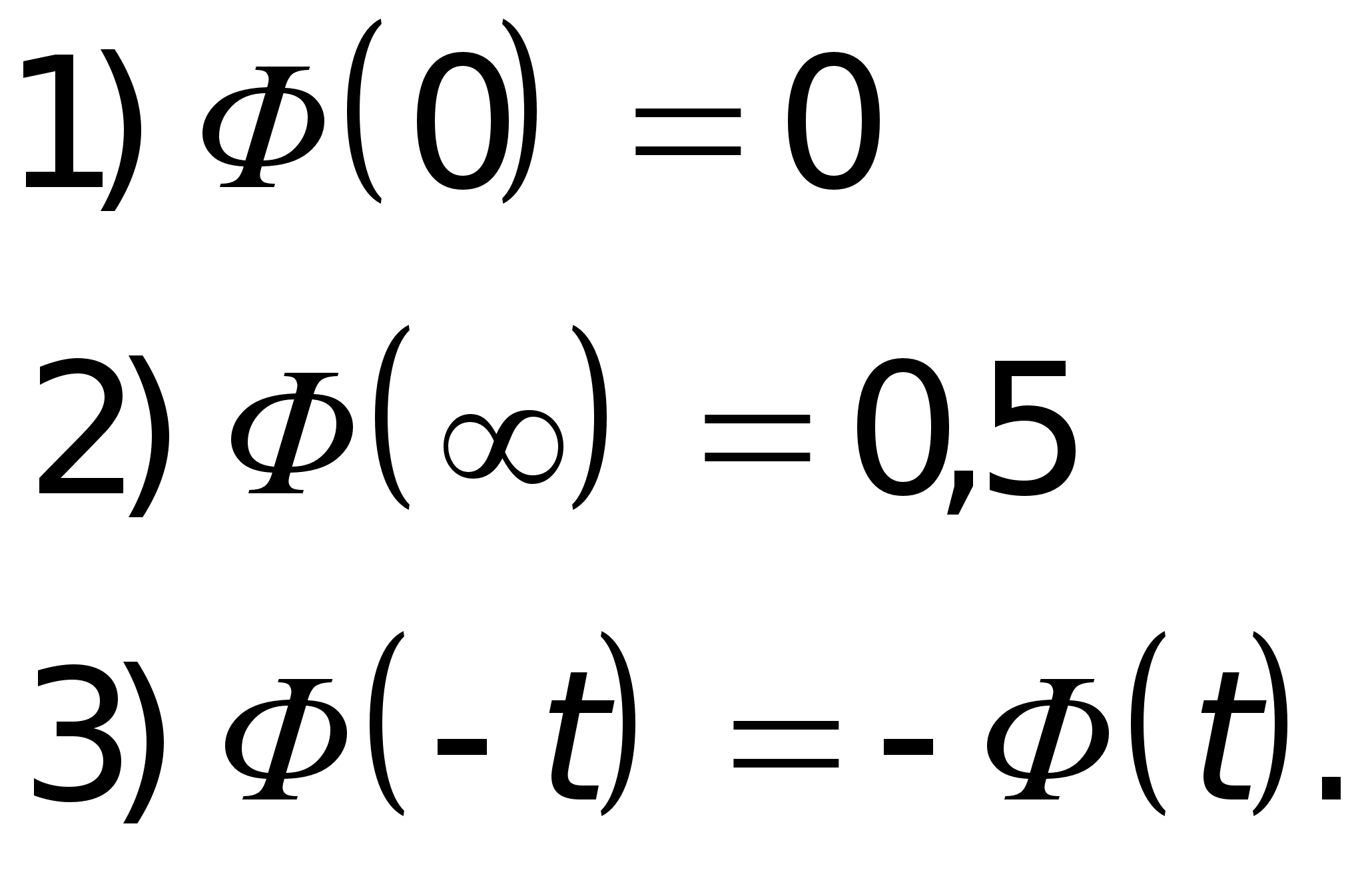
При
t=3,5
![]() ,
и так как
,
и так как
![]() - монотонно
возрастающая
функция, в
практических
расчетах при
- монотонно
возрастающая
функция, в
практических
расчетах при
![]() можно принимать
можно принимать
![]() .
.
Задача. Игральную кость бросают 800 раз. Какова вероятность того, что число очков, кратное 3, выпадает не менее 280 и не более 294 раз?
Здесь
![]()
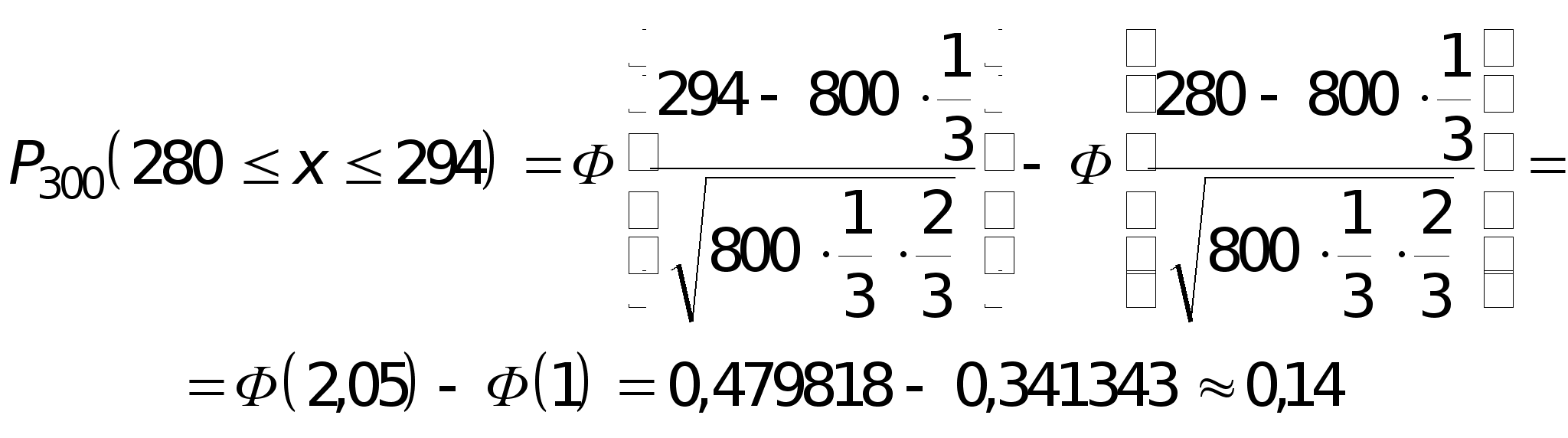
3
10
Дискретные случайные величины.
Часто результатом случайного эксперимента является число. Например, можно подбросить игральную кость и получить одно из чисел: 1,2,3,4,5,6. Можно подъехать к бензоколонке и обнаружить определённое число автомашин в очереди. Можно выстрелить из пушки и измерить расстояние от места выстрела до места падения снаряда. В таких случаях будем говорить, что имеем дело со случайной величиной.
Каждому исходу случайного эксперимента поставим в соответствие единственное число xk — значение случайной величины. Тогда естественно рассматриватьслучайную величину как функцию, заданную на множестве исходов случайного эксперимента.
Случайная величина, которая может принимать лишь конечное или счётное число значений, называется дискретной.
Случайные величины будем обозначать буквами греческого алфавита: (кси), (эта), Значения случайной величины будем записывать в виде конечной или бесконечной последовательности x1, x2,, xn,
Если говорится, что задана случайная величина , это значит, что каждому исходу k случайного эксперимента поставлено в соответствие единственное число xk, что записывается в виде равенства xk = (k).
Некоторые из значений xk могут совпадать, то есть различным исходам может соответствовать одно и то же число x. Если все значения случайной величины совпадают, то будем говорить, что случайная величина постоянна.
Пусть Аk — множество всех элементарных исходов, каждому из которых соответствует значение xk (k = 1,2,,n) случайной величины . Этот факт можно записать в виде формулы
![]()
Таким образом, Аk – это событие (строго говоря, это верно лишь в случае конечного или счётного числа исходов). Для каждого события Аk определим число рk 0, равное вероятности этого события: рk = P(Ak). Очевидно, что
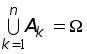 ,
Ai∩Aj =
(i,j = 1,2,,n,
ij),
,
Ai∩Aj =
(i,j = 1,2,,n,
ij),
 .
.
Теперь каждому значению xk случайной величины можно поставить в соответствие вероятность рk = P(Ak) события Аk. Если такое соответствие определено то будем говорить, что задан закон распределения дискретной случайной величины . Обычно закон распределения дискретной случайной величины представляется в виде таблицы
| |
х1 |
х2 |
х3 |
|
хn |
(1) |
| P |
p1 |
p2 |
p3 |
|
pn |
В дальнейшем для краткости будем называть величину pi вероятностью значения хi случайной величины. Отметим, что закон распределения содержит всю информацию о случайной величине, и задать случайную величину можно, просто представив её закон распределения.
Пусть две случайные величины
= {x1,x2,,xn}; = {у1, у2,,уm} (2)
определены
на одном и том
же пространстве
элементарных
исходов. Если
Аi (i = 1,2,,n)
– событие,
объединяющее
все исходы,
приводящие
к значению хi
случайной
величины ,
а Вj (j = 1,2,,m)
– событие,
объединяющее
все исходы,
приводящие
к значению уi
случайной
величины ,
то можно определить
случайную
величину = + ,
которая принимает
все возможные
значения
![]() = xi + yj.
Каждому такому
значению
= xi + yj.
Каждому такому
значению
![]() случайной
величины
ставится в
соответствие
вероятность
случайной
величины
ставится в
соответствие
вероятность
![]() ,
равная вероятности
пересечения
событий Аi
и Вj:
,
равная вероятности
пересечения
событий Аi
и Вj:
![]() = P(Ai∩Bj).
= P(Ai∩Bj).
Таким образом
определяется
закон распределения
суммы двух
случайных
величин. Также
можно определить
законы распределения
разности – ,
произведения и
частного
![]() случайных
величин (последний
лишь в случае,
если
не принимает
нулевого значения).
случайных
величин (последний
лишь в случае,
если
не принимает
нулевого значения).
Две случайные величины
= {x1,x2,,xn}; = {у1, у2,,уm},
определённые на одном и том же пространстве элементарных исходов, имеющие законы распределения
| |
х1 |
|
xi |
| |
y1 |
|
yj |
| |
|
Р |
|
|
|
|
Р |
|
|
|
|
называются независимыми, если при любых i и j выполняется равенство
Р(( = хi) ∩ ( = yj)) = ![]()
![]()
Пример1. Брошены две игральных кости. Число очков, выпавшее на первой кости, – случайная величина . Число очков, выпавшее на второй кости – случайная величина . Считаем, что все исходы (( = i)∩( = j)) (i = 1,2,,6; j = 1,2, ,6) равновероятны, всего их 36, поэтому
P(( = i)∩( = j)) = ![]()
Так как
P( = i) = ![]() и P( = j)) =
и P( = j)) = ![]() ,
очевидно, что
по определению
и – независимые
случайные
величины.
,
очевидно, что
по определению
и – независимые
случайные
величины.
Пример 2. Даны две независимые случайные величины и с заданными законами распределения
| | 0 | 1 | | 1 | 2 | |
|
Р |
|
|
Р |
|
|
Определим случайные величины и следующим образом: = + , = . Выясним, являются ли независимыми случайные величины и .
Составим
закон распределения
.
Наименьшее
значение
равняется 1.
Вероятность
события = 1
равна вероятности
события ( = 0)∩( = 1),
которая в силу
независимости
и
равна
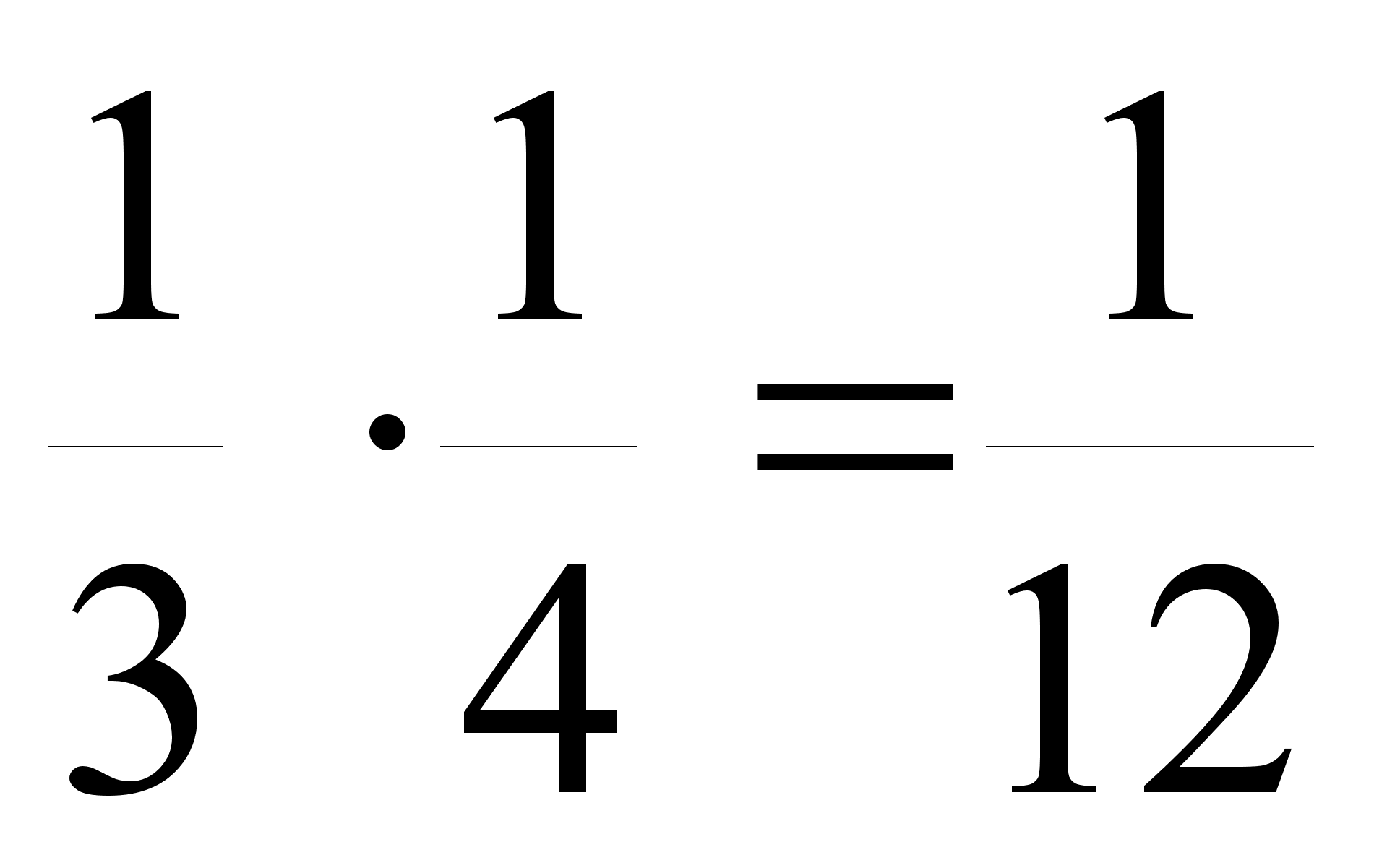 .
Событие = 2
совпадает с
событием
(( = 0)∩( = 2))
.
Событие = 2
совпадает с
событием
(( = 0)∩( = 2))![]() (( = 1)∩( = 1)).
Его вероятность
равна
(( = 1)∩( = 1)).
Его вероятность
равна
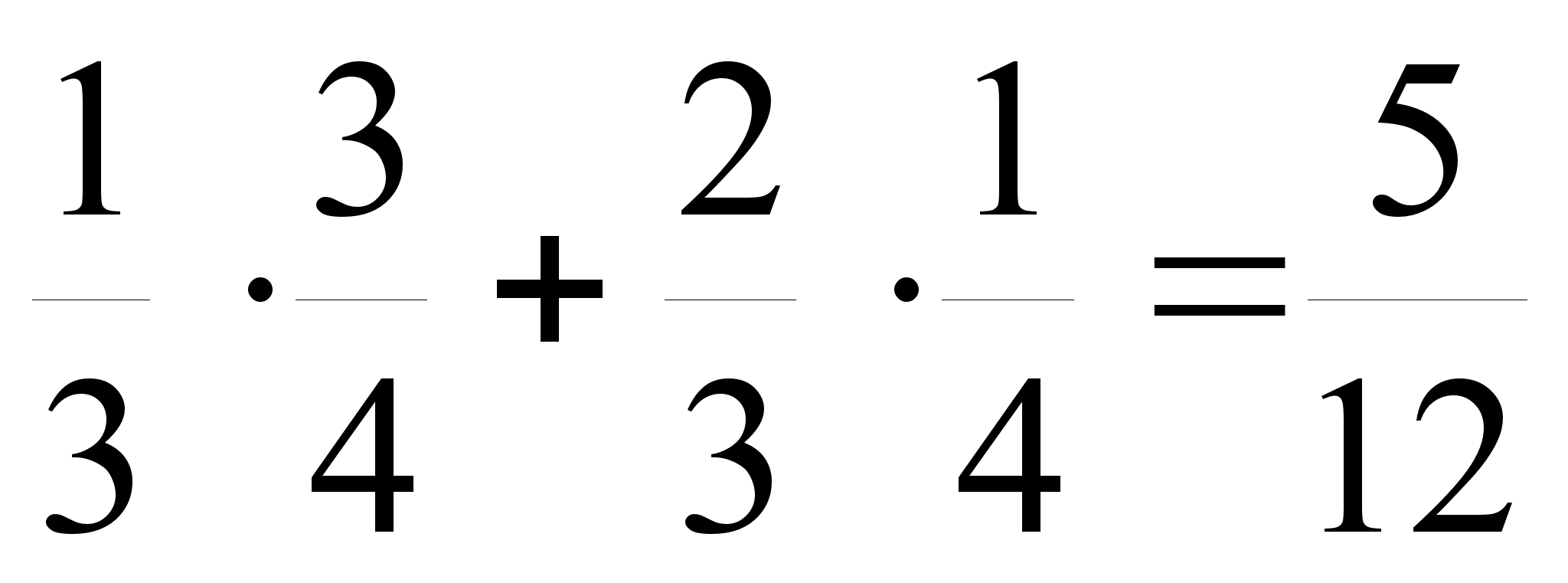 .
.
Максимальное
значение ,
равное 3, имеет
вероятность
![]() .
Таким образом,
закон распределения
случайной
величины
можно представить
таблицей
.
Таким образом,
закон распределения
случайной
величины
можно представить
таблицей
| | 1 | 2 | 3 |
|
Р |
|
|
|
Закон распределения представляется таблицей
| | 0 | 1 | 2 |
|
Р |
|
|
|
Рассмотрим события = 3 и = 0. Очевидно, что
Р( = 3)
Р( = 0) = 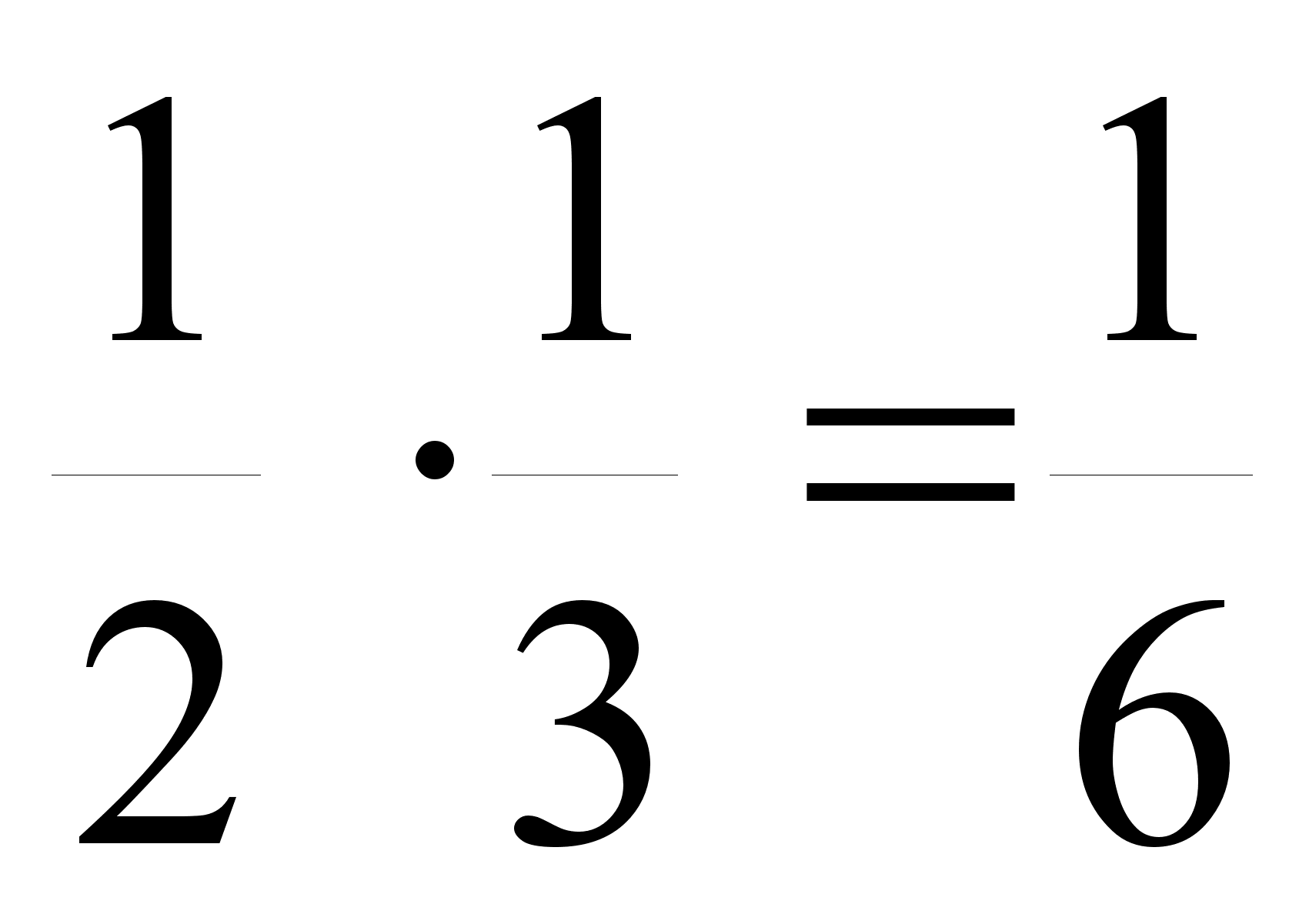
С другой стороны, событие ( = 3)∩( = 0) – невозможное, так как = 3 только при = 1, а = 0 лишь при = 0. Отсюда следует, что
Р(( = 3)∩( = 0)) = 0,
и теперь ясно, что, по крайней мере, в одном случае условие определения независимости для случайных величин и не выполняется. Отсюда следует, что эти случайные величины зависимы.
Математическое ожидание случайной величины.
Пусть задан закон распределения случайной величины .
| |
х1 |
х2 |
х3 |
|
хn |
| P |
p1 |
p2 |
p3 |
|
pn |
Математическое ожидание М (или М()) случайной величины определяется формулой
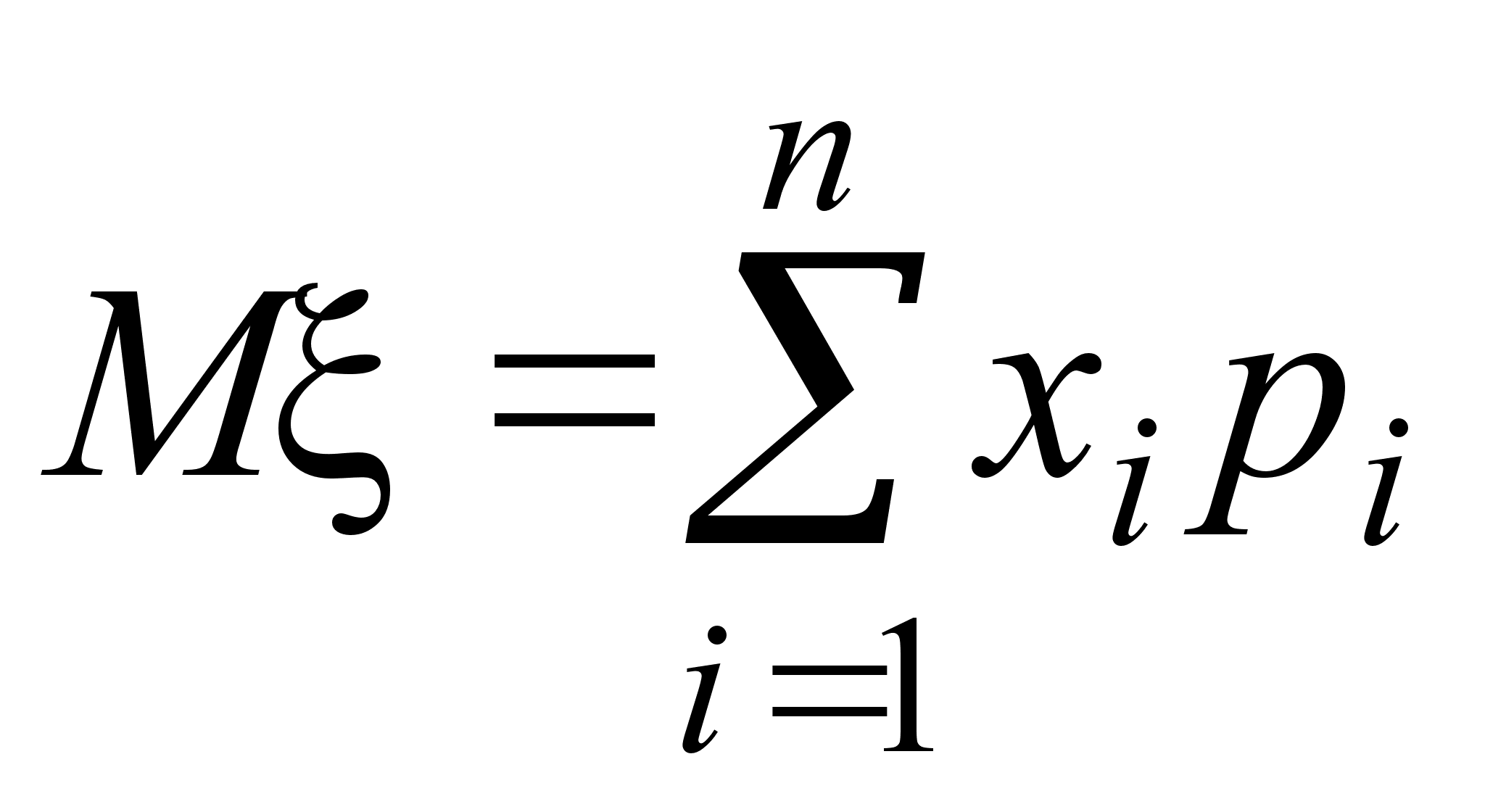
Рассмотрим пример. Пусть в некотором магазине, торгующем электробытовой техникой, получены статистические данные о числе проданных холодильников в каждый день месяца (условно считаем, что месяц состоит из 30 рабочих дней). Эти данные собраны в таблицу
| Количество проданных холодильников | 0 | 1 | 2 | 3 | 4 | 5 |
| Число дней, в которые было продано столько холодильников | 3 | 7 | 8 | 9 | 2 | 1 |
По этой таблице легко подсчитать число холодильников, проданных в магазине за месяц: 0*1+1*7+2*8+3*9+4*2+5*1 = 63. Чтобы подсчитать среднее число холодильников, продававшихся в один день месяца, нужно эту сумму разделить на 30, в результате получим 2,1. Если в приведенной таблице каждое число второй строки поделить на 30, то получится последовательность дробей
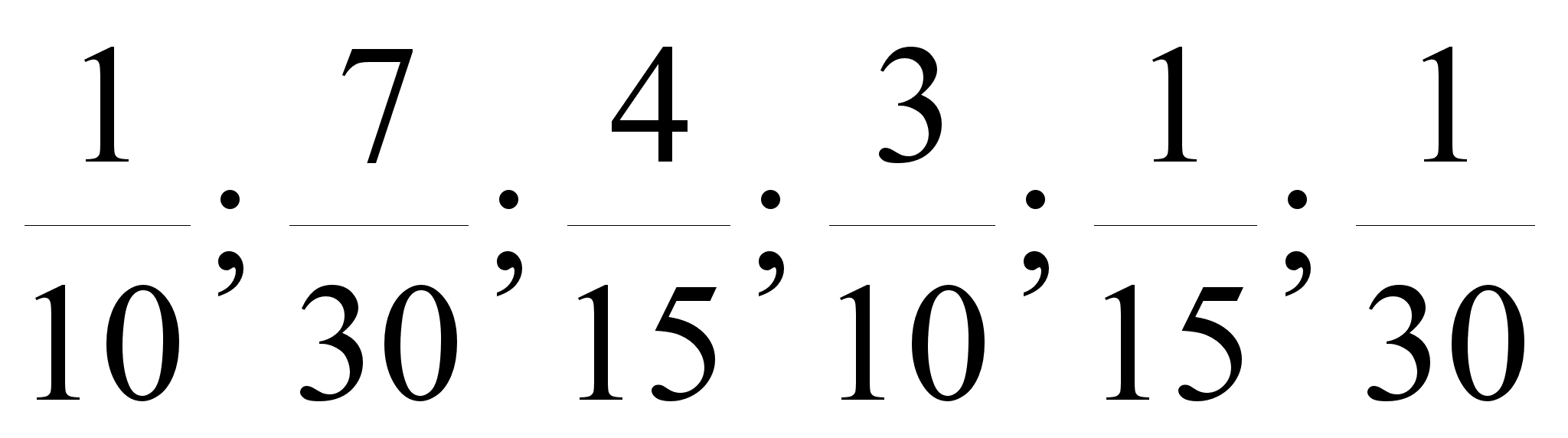 ,
,
каждая из которых представляет собой так называемую относительную частоту, с которой в данный месяц появлялся приведенный в верхней строке объём продаж. Очевидно, что если просуммировать все произведения чисел, стоящих в первой строке таблицы, на их относительные частоты, то получится то же среднее число продававшихся в один день холодильников:
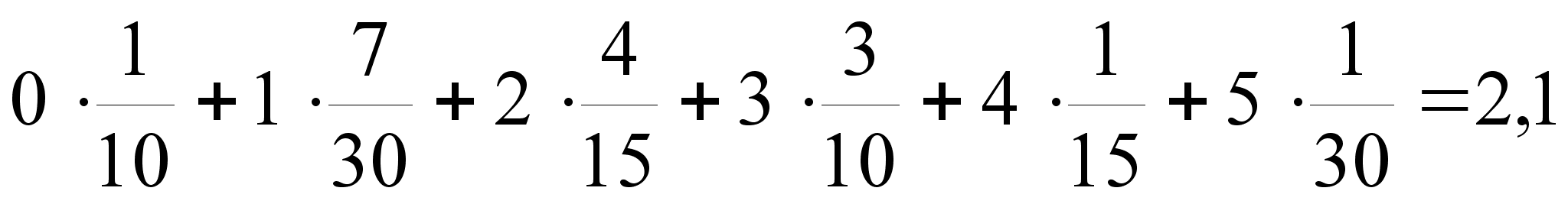
Если бы в последней формуле относительные частоты рассчитывались не для одного месяца, а для существенно большего срока, то при некоторых условиях (например, при отсутствии кризисных явлений, существенно влияющих на спрос населения на дорогостоящие товары) эти относительные частоты можно было бы считать довольно близкими к вероятностям соответствующих значений объёма продаж. Таким образом, приходим к выводу, что математическое ожидание случайной величины – это в некотором смысле её среднее значение. Следует отметить, что случайная величина может вообще не принимать значения, равного её математическому ожиданию. Так, например, случайная величина, принимающая только значения 1 и –1, каждое – с вероятностью 0,5, имеет математическое ожидание, равное нулю.
Пример. Найти математическое ожидание случайной величины, заданной законом распределения
| | 1 | 0 |
|
Р |
p | q |
Здесь p + q = 1.
M = 1р + 0q = р
Свойства математического ожидания.
Если случайная величина принимает одно и то же значение при всех исходах случайного эксперимента, то есть С, то её математическое ожидание равно С.
Если М = а, и k – константа, то М(k) = kM (математическое ожидание случайной величины, умноженной на число, равно математическому ожиданию случайной величины, умноженному на это число).
Если М = а, и k – константа, то М(k + ) = k + M (математическое ожидание суммы случайной величины и числа равно сумме этого числа и математического ожидания случайной величины).
Выведем формулу для математического ожидания суммы двух случайных величин и , определённых на одном и том же пространстве элементарных исходов и заданных законами распределения
| |
х1 |
|
xn |
|
y1 |
|
yk |
|
|
Р |
|
|
|
Р |
|
|
|
М( + )
=
(х1 + у1)Р(( = х1) ∩ ( = у1))+ (х2 + у1)Р(( = х2) ∩ ( = у1)) +
+(хi + уj)Р(( = хi) ∩ ( = уj)) + + (хn + уk)Р(( = хn) ∩ ( = уk))
Очевидно, что сумма в правой части последней формулы содержит nk слагаемых. Преобразуем эту сумму следующим образом:
М( + ) = х1 Р((=х1)∩(=у1)) + х1 Р((=х1)∩(=у2)) ++х1 Р((=х1)∩(=уk)) + + х2Р((=х2)∩(=у1)) + х2Р((=х2)∩(=у2)) + + х2Р((=х2)∩(=уk)) +
+ хnР((=хn)∩(=у1)) + хnР((=хn)∩(=у2)) + + хnР((=хn)∩(=уk)) +
+ у1Р((=х1)∩(=у1)) + у1Р((=х2)∩(=у1)) + + у1Р((=хn)∩(=у1)) +
+ у2Р((=х1)∩(=у2)) + у2Р((=х2)∩(=у2)) + + у2Р((=хn)∩(=у2)) +
+ уkР((=х1)∩(=уk)) + уkР((=х2)∩(=уk)) + + уkР((=хn)∩(=уk)) =
= х1(Р((=х1)∩(=у1)) + Р((=х1)∩(=у2)) + + Р((=х1)∩(=уk))) +
+ х2(Р((=х2)∩(=у1)) + Р((=х2)∩(=у2)) + + Р((=х2)∩(=уk))) + +
+ хn(Р((=хn)∩(=у1)) + Р((=хn)∩(=у2)) + + Р((=хn)∩(=уk))) +
+ у1(Р((=х1)∩(=у1)) + Р((=х2)∩(=у1)) + + Р((=хn)∩(=у1))) +
+ у2(Р((=х1)∩(=у2)) + Р((=х2)∩(=у2)) + + Р((=хn)∩(=у2))) +
+ уk(Р((=х1)∩(=уk)) + Р((=х2)∩(=уk)) + + Р((=хn)∩(=уk))) =
= х1Р(=х1) + х2Р(=х2) ++ хn Р(=хn) +
+ у1Р(=у1) + у2Р(=у2) ++ у1Р(=у1) = M + M
При выводе этой формулы использован очевидный факт, что, например, событие =х1 можно представить в виде объединения несовместных событий (=х1)∩(=у1), (=х1)∩(=у2), , (=х1)∩(=уn).
Пример.
Заданы n одинаково распределённых случайных величин 1, 2, , n с законом распределения
|
i |
1 | 0 |
|
P |
p |
q |
Найти математическое ожидание суммы этих случайных величин.
Решение.
M(![]() ) =
) = 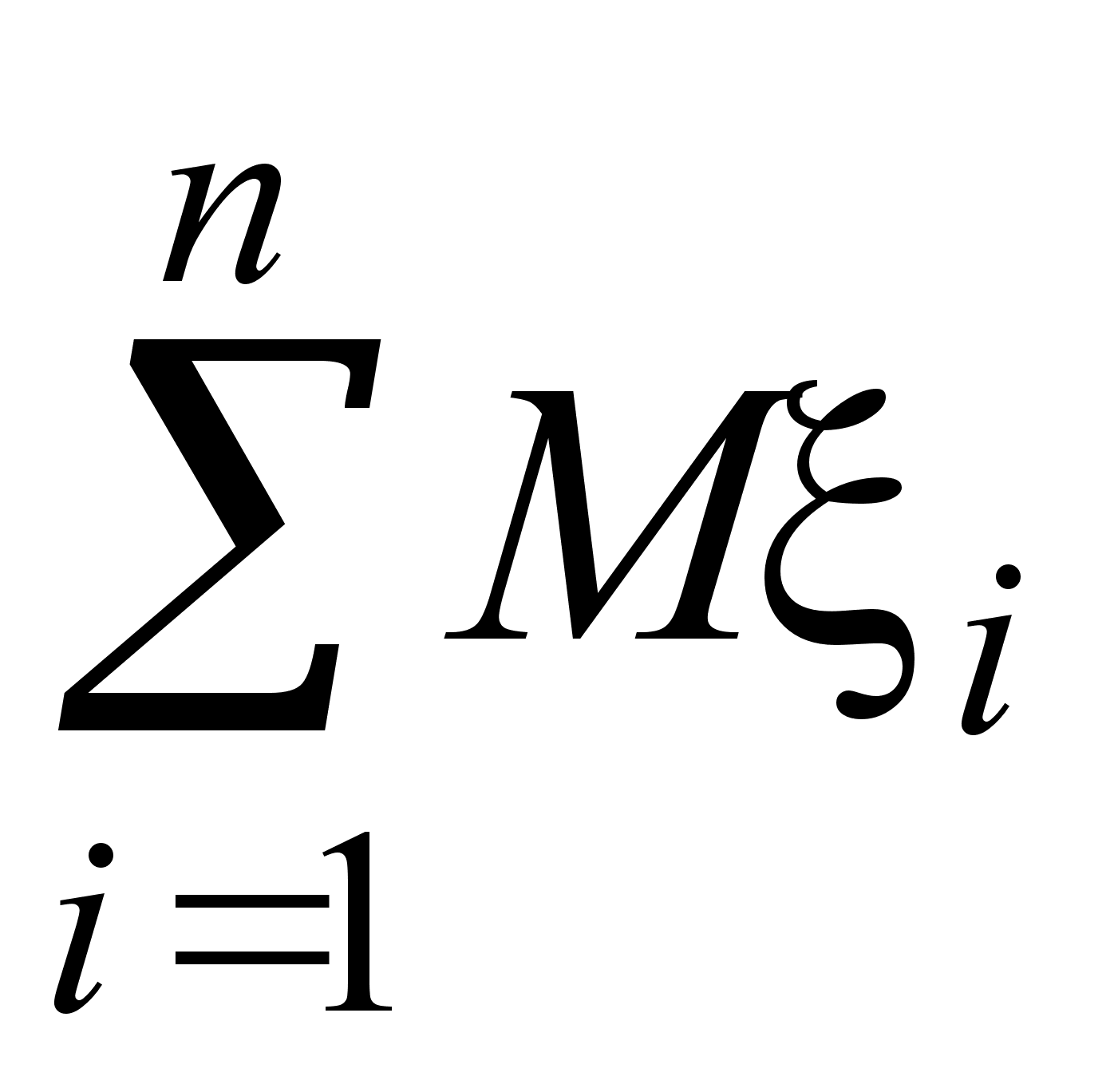 = np
= np
Теорема.
Если случайные величины и независимы, то
М() = ММ
Доказательство.
Если заданы законы распределения двух независимых случайных величин и
| |
х1 |
|
xi |
|
xn |
|
y1 |
|
yj |
|
yk |
|
|
Р |
|
|
|
|
|
Р |
|
|
|
|
|
то математическое ожидание произведения этих случайных величин можно представить следующим образом:
М() = 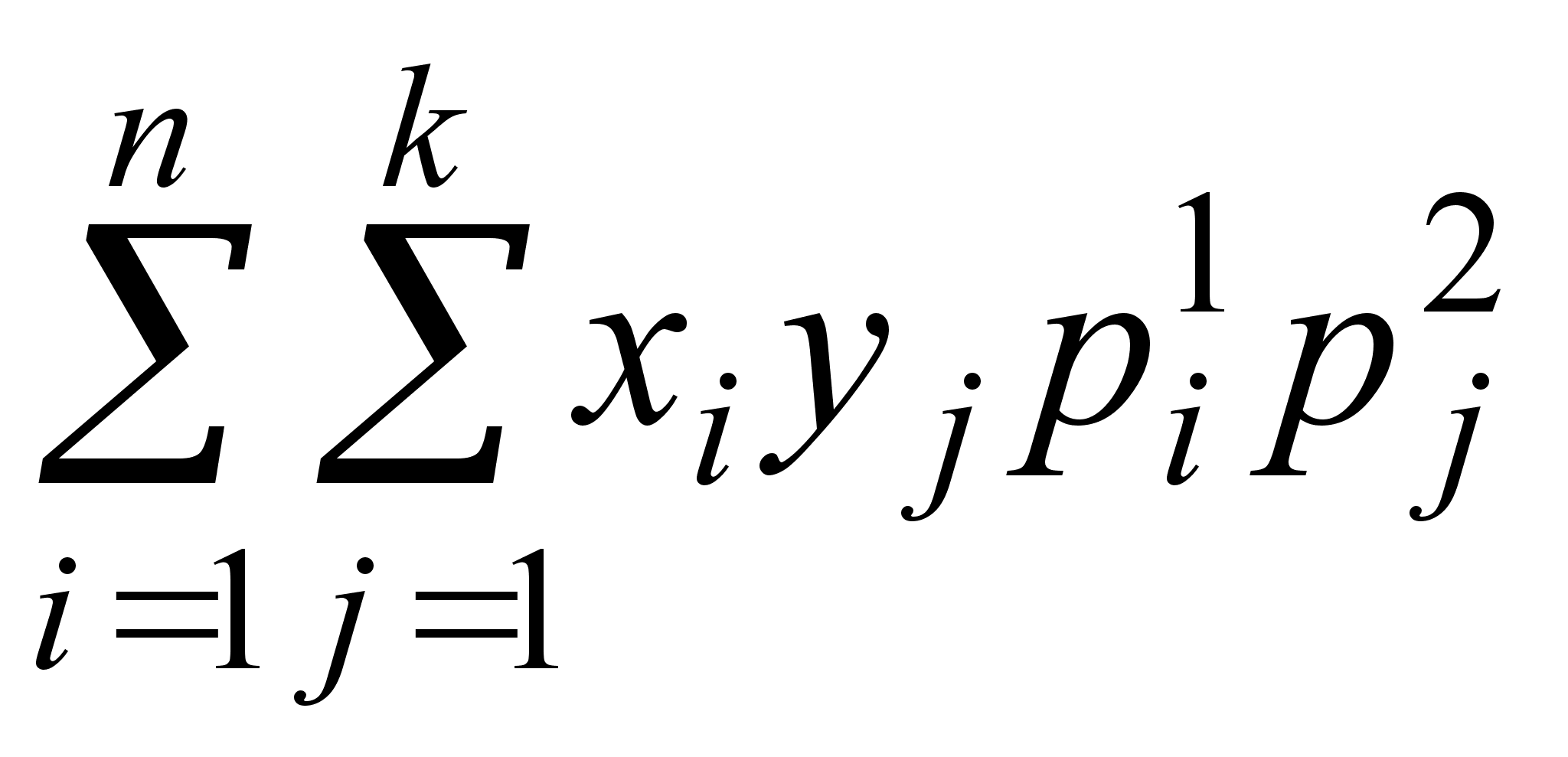 =
=
= х1![]()
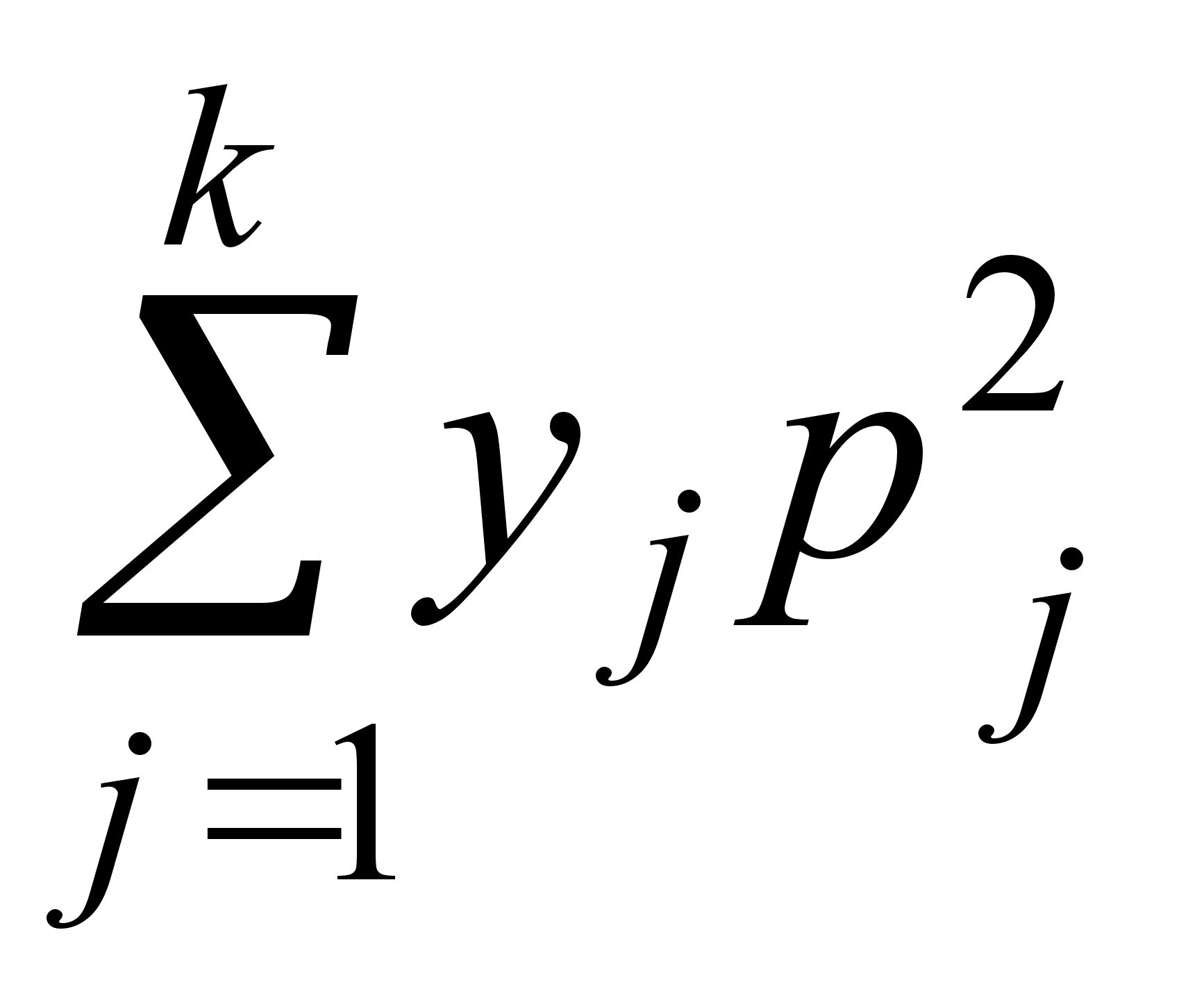 +х2
+х2![]()
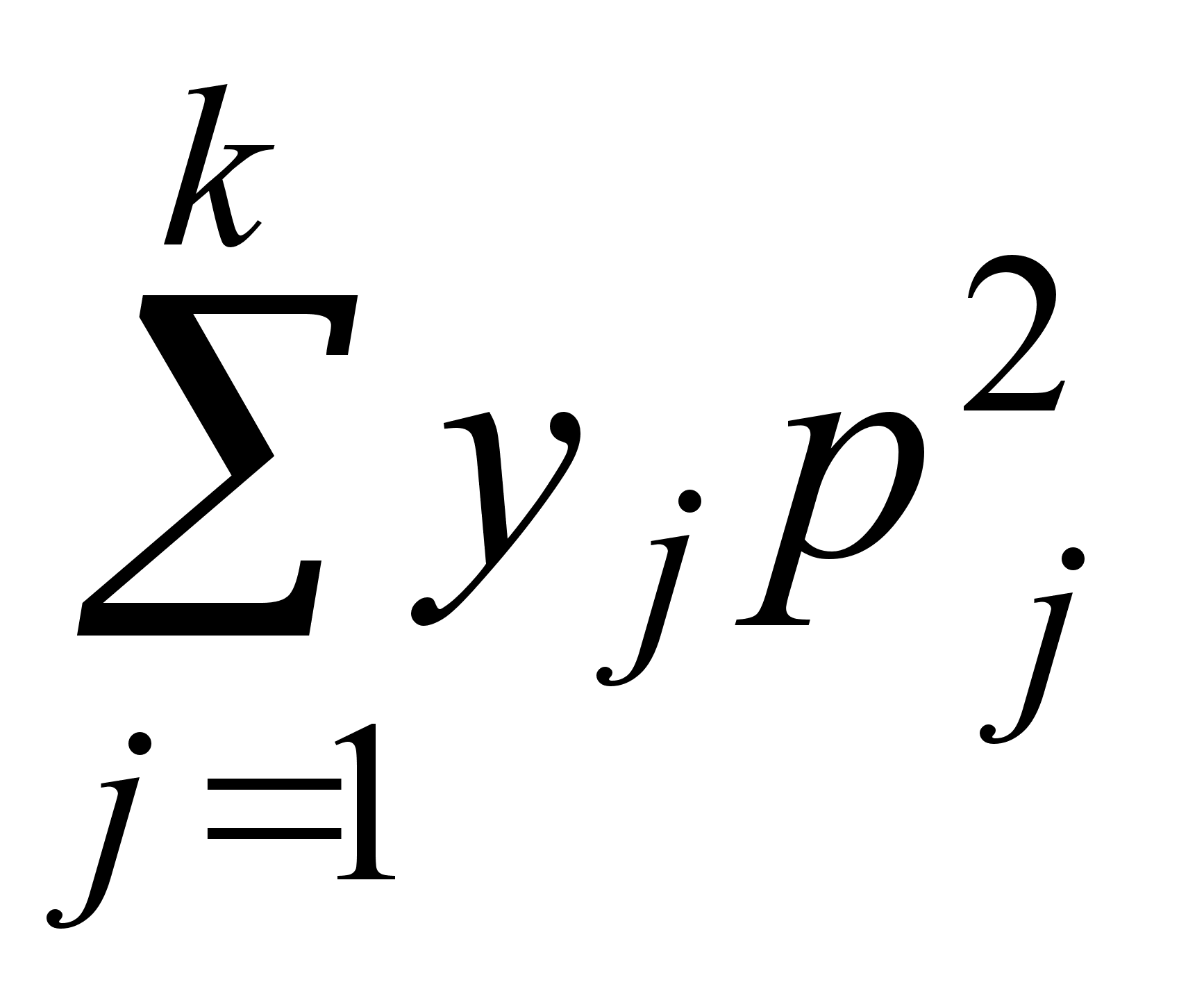 ++ хi
++ хi![]()
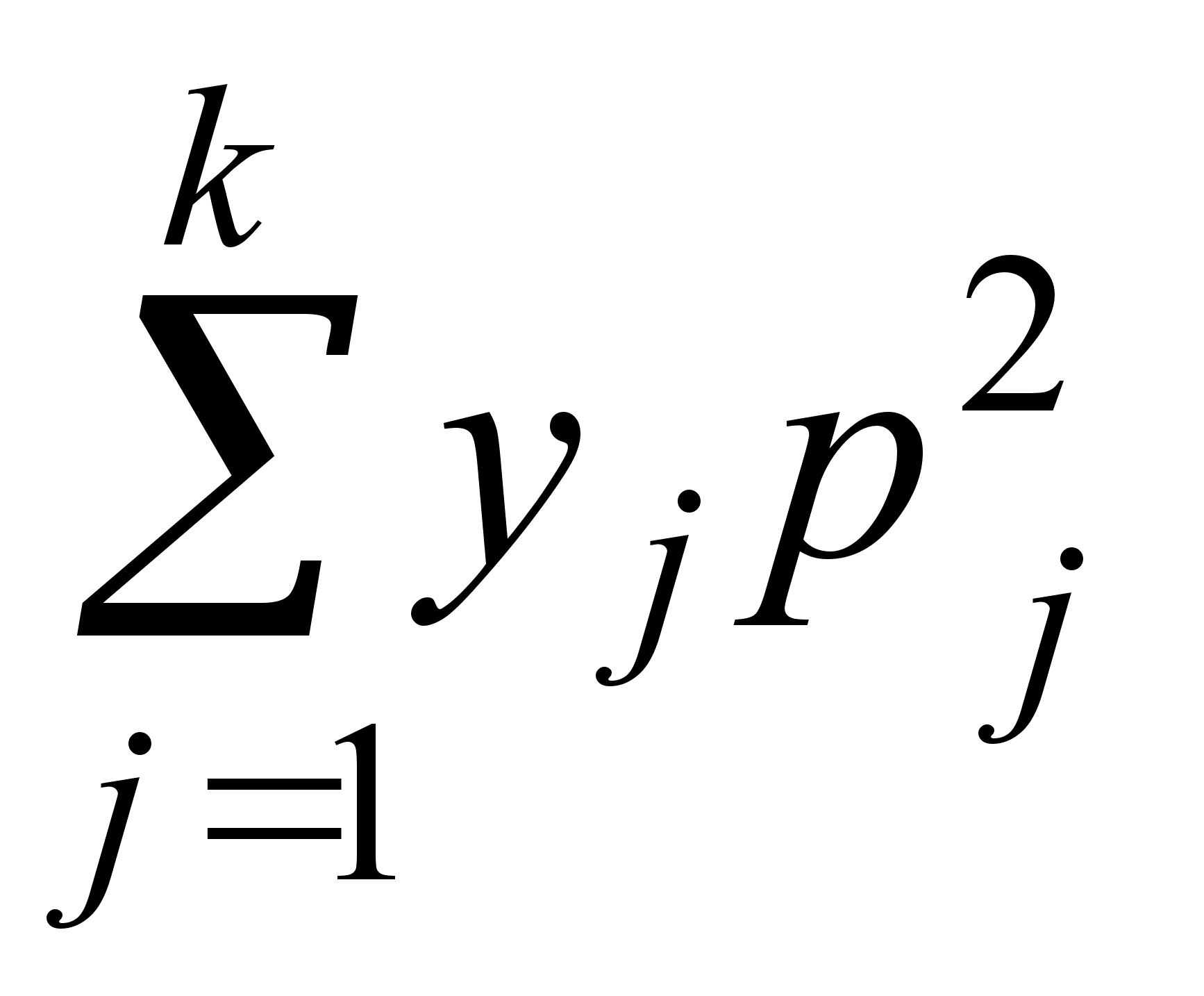 + хn
+ хn![]()
 =
=
= х1![]() M + х2
M + х2![]() M + + хi
M + + хi![]() M+ хn
M+ хn![]() M = M
M = M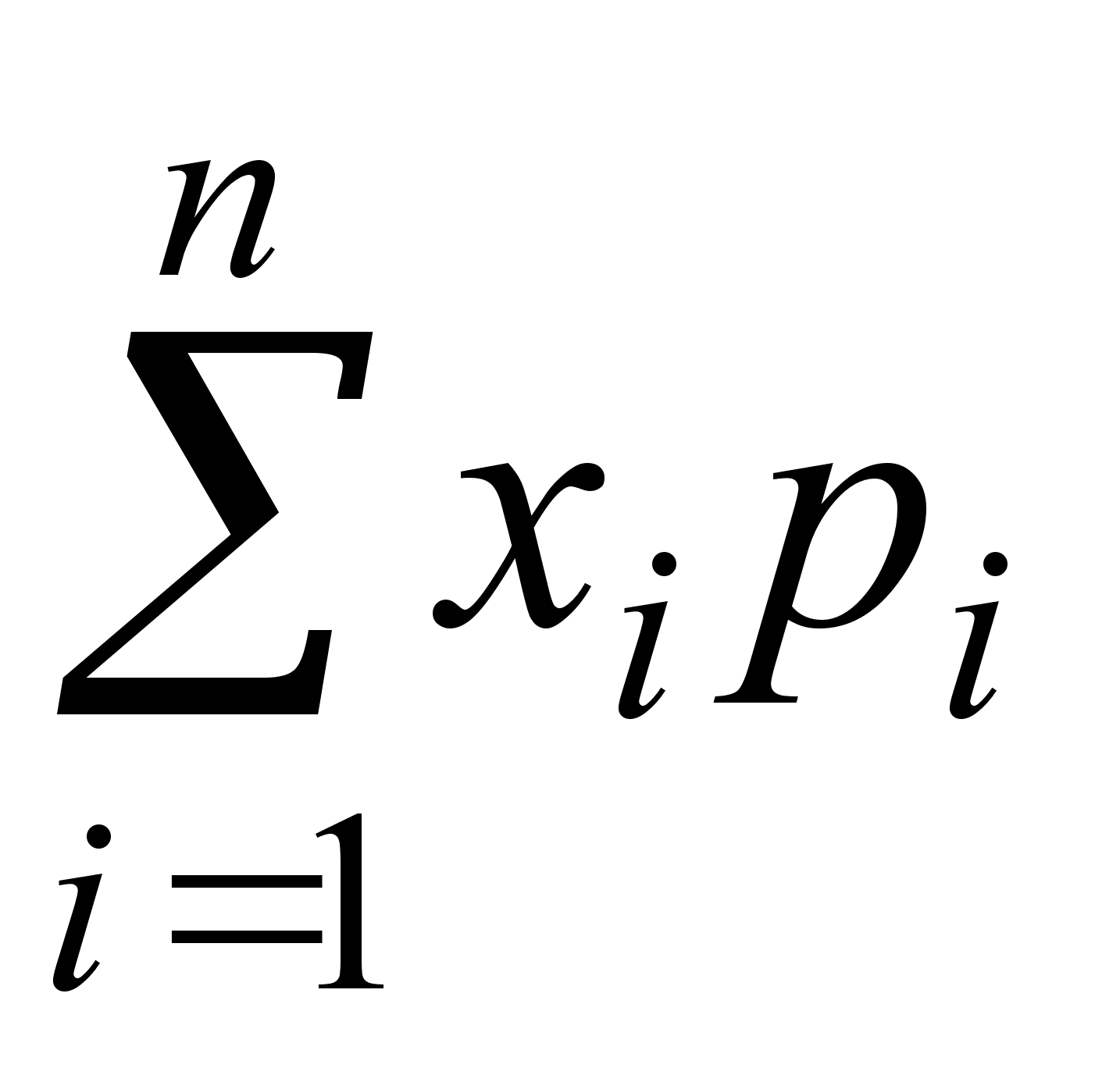 = ММ
= ММ
Дисперсия случайной величины.
Дисперсия D случайной величины определяется формулой
D = M( – M)2
Дисперсия случайной величины — это математическое ожидание квадрата отклонения случайной величины от её математического ожидания.
Рассмотрим случайную величину с законом распределения
| | 1 | 2 | 3 |
|
Р |
|
|
|
Вычислим её математическое ожидание.
M = 1![]() + 2
+ 2![]() + 3
+ 3![]() =
= ![]()
Составим закон распределения случайной величины – M
|
– M |
|
|
|
|
Р |
|
|
|
а затем закон распределения случайной величины ( – M)2
|
(– M)2 |
|
|
|
|
Р |
|
|
|
Теперь можно рассчитать величину D :
D = ![]()
![]() +
+ ![]()
![]() +
+ ![]()
![]() =
= ![]()
Используя определение дисперсии, для дискретной случайной величины формулу вычисления дисперсии можно представить в таком виде:
D = 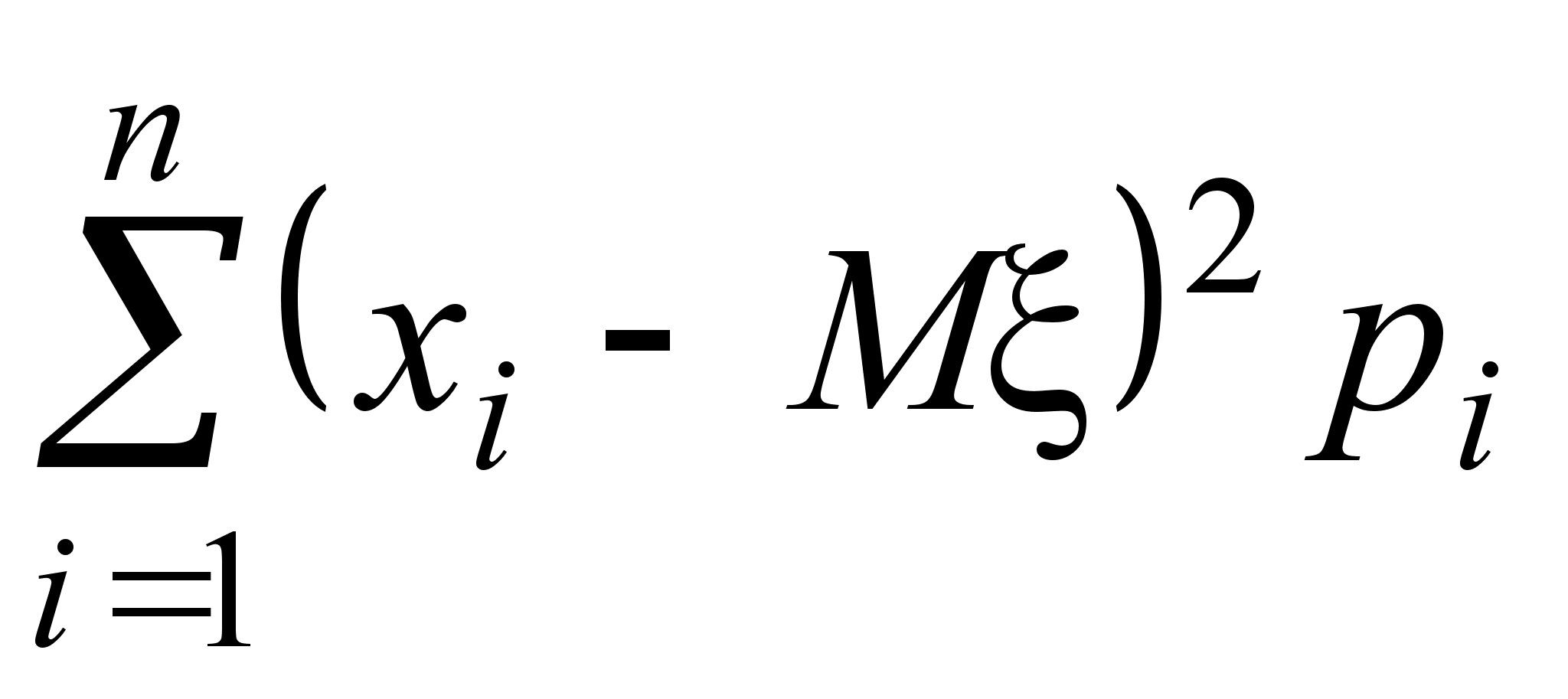
Можно вывести ещё одну формулу для вычисления дисперсии:
D = 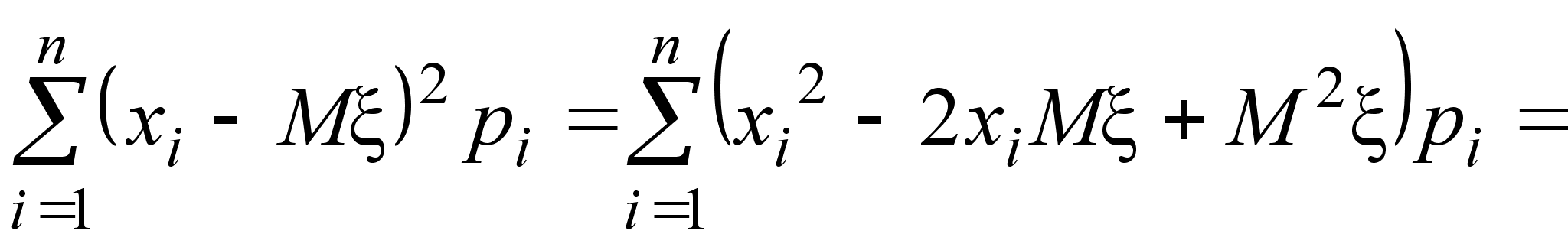
= 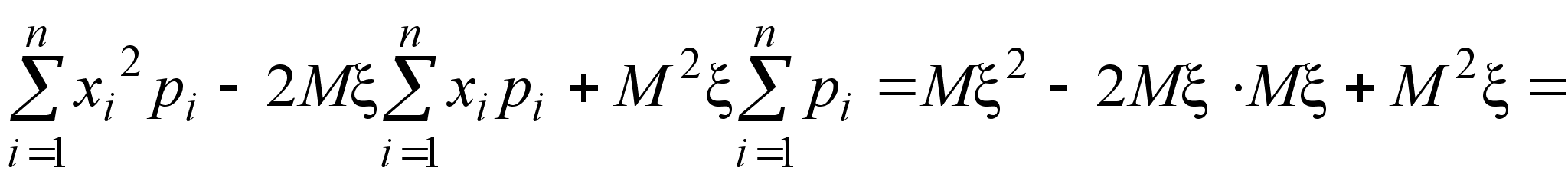
= M2 – M2
Таким образом, дисперсия случайной величины равна разности математического ожидания квадрата случайной величины и квадрата её математического ожидания.
Пример.
Найти дисперсию случайной величины, заданной законом распределения
| | 1 | 0 |
|
Р |
p |
q |
Выше было показано, что M = р. Легко видеть, что M2 = р. Таким образом, получается, что D = р – р2 = pq.
Дисперсия характеризует степень рассеяния значений случайной величины относительно её математического ожидания. Если все значения случайной величины тесно сконцентрированы около её математического ожидания и большие отклонения от математического ожидания маловероятны, то такая случайная величина имеет малую дисперсию. Если значения случайной величины рассеяны и велика вероятность больших отклонений от математического ожидания, то такая случайная величина имеет большую дисперсию.
Свойства дисперсии.
Если k – число, то D(k) = k2 D.
Доказательство.
D(k) = M(k – M(k))2 = M(k – k M)2 = M(k2 ( – M)2) = k2M( – M)2 =
= k2 D
Для попарно независимых случайных величин 1, 2,, n справедливо равенство
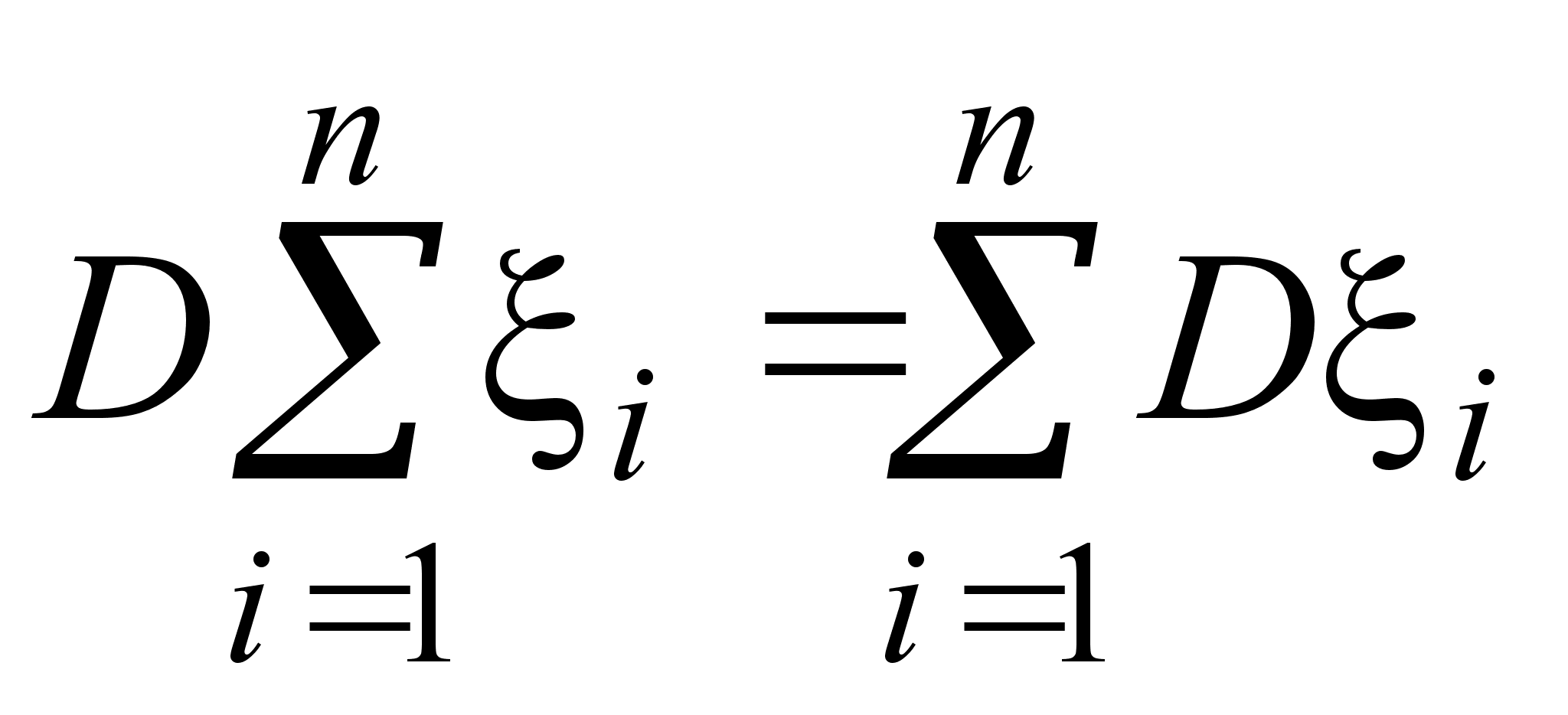
Это свойство оставим без доказательства. Рекомендуем читателю рассмотреть следующий пример.
Пусть и – независимые случайные величины с заданными законами распределения:
| |
0 |
1 |
|
1 |
2 |
|
|
Р |
0,25 |
0,75 |
Р |
0,7 |
0,7 |
Показать, что D( + ) = D + D.
3
Биномиальный закон распределения.
Пусть заданы числа n N и p (0 p 1). Тогда каждому целому числу из промежутка [0; n] можно поставить в соответствие вероятность, рассчитанную по формуле Бернулли. Получим закон распределения случайной величины (назовём её )
| |
0 |
|
k |
|
n |
|
Р |
| |
|
| |
Будем говорить, что случайная величина распределена по закону Бернулли. Такой случайной величиной является частота появления события А в n повторных независимых испытаниях, если в каждом испытании событие А происходит с вероятностью p.
Рассмотрим отдельное i-е испытание. Пространство элементарных исходов для него имеет вид
![]()
Определим на этом пространстве случайную величину i следующим образом:
i = 1, если происходит событие А;
i
= 0,
если происходит
событие
![]()
Закон распределения случайной величины i рассматривался в предыдущем параграфе.
|
i |
1 |
0 |
|
Р |
p |
q = 1–p |
M = р; D = рq
Для
i = 1,2,,n
получаем систему
из n
независимых
случайных
величин i,
имеющих одинаковые
законы распределения.
Если теперь
сравнить законы
распределения
двух случайных
величин
и
![]() ,
то можно сделать
очевидный
вывод:
=
,
то можно сделать
очевидный
вывод:
=
![]() .
Отсюда следует,
что для случайной
величины ,
имеющей закон
распределения
Бернулли,
математическое
ожидание и
дисперсия
определяются
формулами
.
Отсюда следует,
что для случайной
величины ,
имеющей закон
распределения
Бернулли,
математическое
ожидание и
дисперсия
определяются
формулами
M
= M![]() =
=
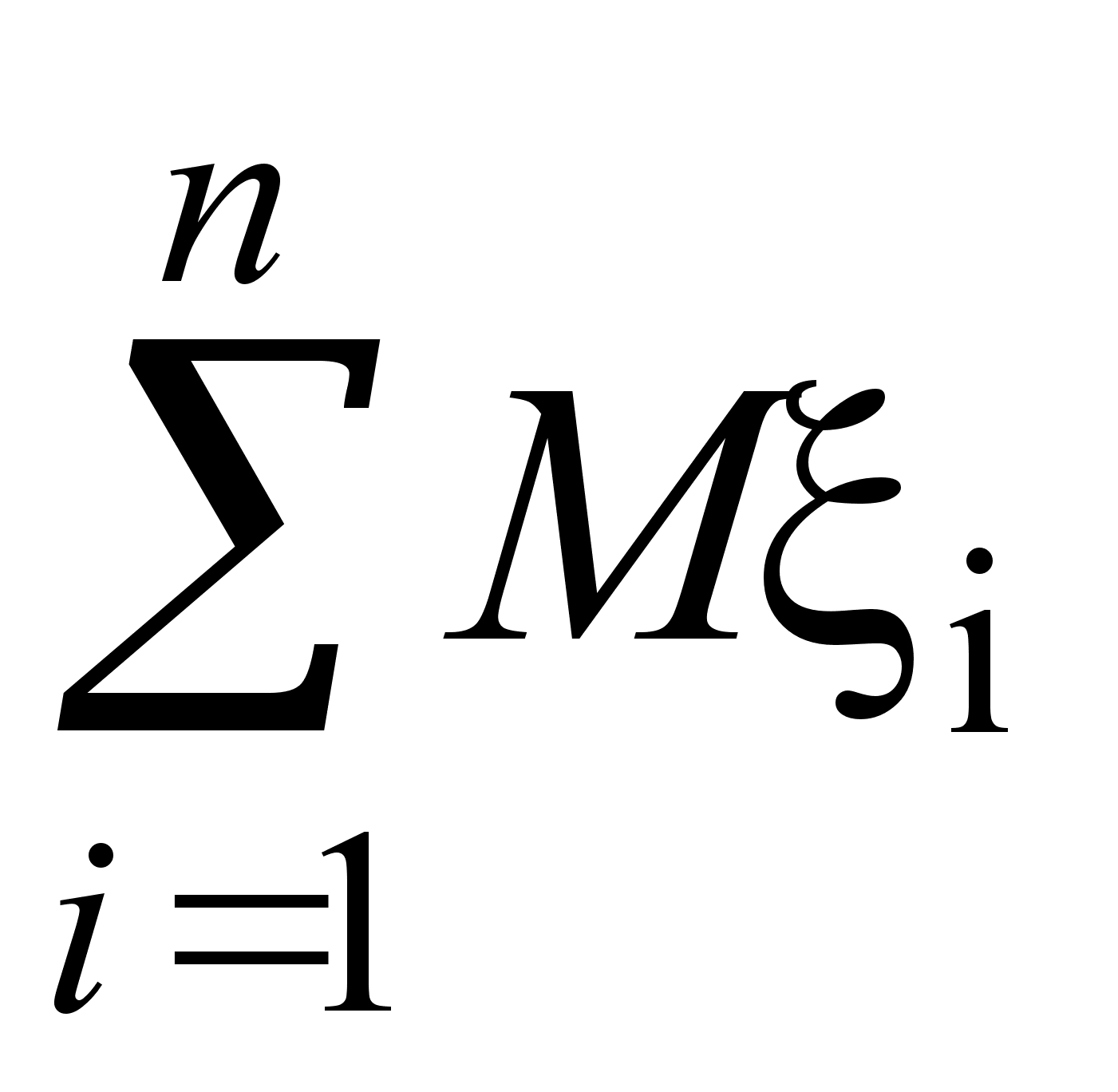 =
=
![]() =
np;
=
np;
D
= D![]() =
=
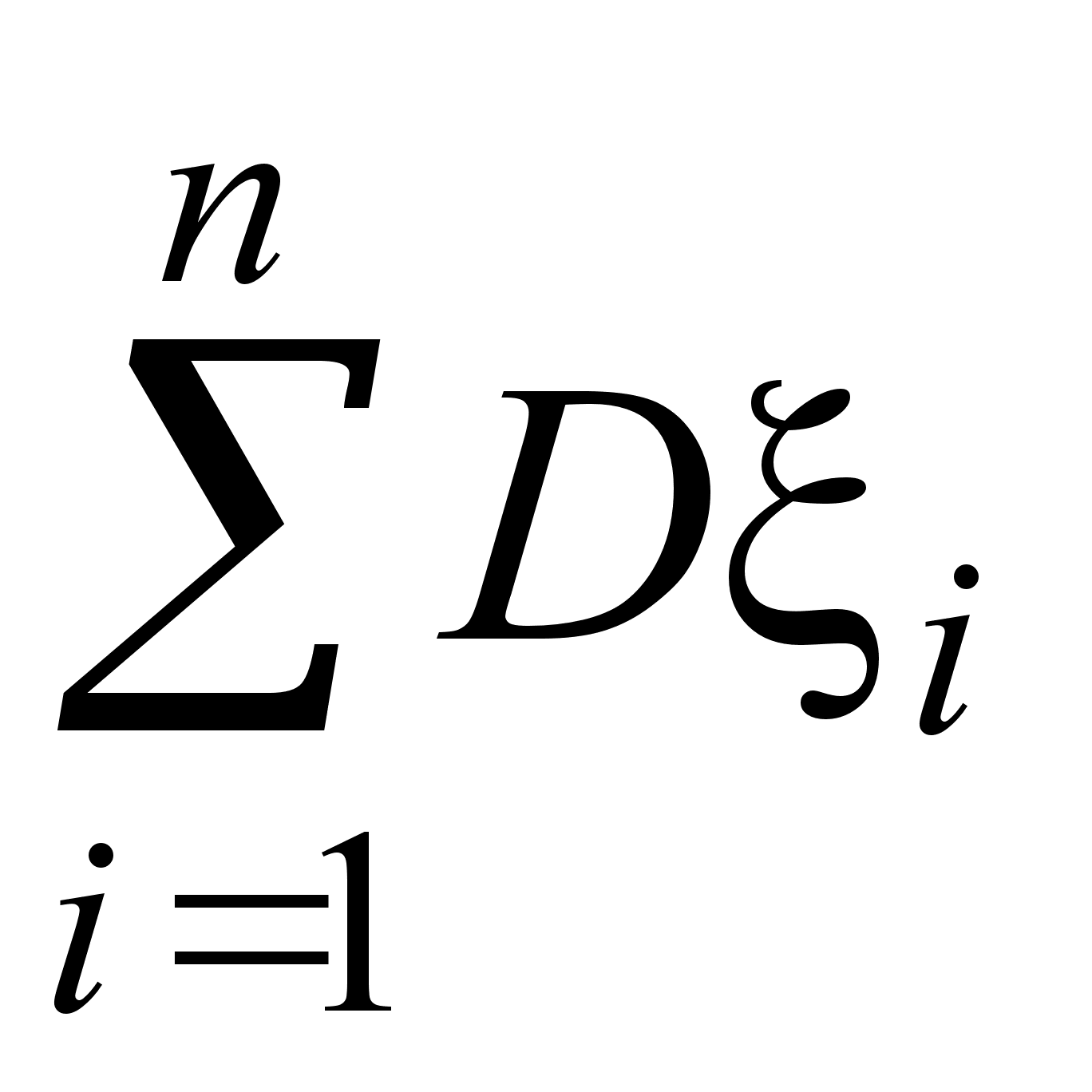 =
=
![]() =
npq
=
npq
Найдём
оценку величины
р — вероятности
успеха в одном
испытании
некоторого
биномиального
эксперимента.
Для этого проведём
n испытаний
и подсчитаем
х – число успехов.
Оценку р*
неизвестной
величины р
определим
формулой р*
=
![]() .
.
Пример.
Из 20 отобранных для контроля образцов продукции 4 оказались нестандартными. Оценим вероятность того, что случайно выбранный экземпляр продукции не отвечает стандарту отношением р* = 4/20 = 0,2.
Так
как х случайная
величина, р*
– тоже случайная
величина. Значения
р* могут
меняться от
одного эксперимента
к другому (в
рассматриваемом
случае экспериментом
является случайный
отбор и контроль
20-ти экземпляров
продукции).
Каково математическое
ожидание
р*? Поскольку
х
есть случайная
величина,
обозначающая
число успехов
в n
испытаниях
по схеме Бернулли,
Мx
= np.
Для математического
ожидания случайной
величины р*
по определению
получаем:
Mp* = M![]() ,
но n
здесь
является константой,
поэтому по
свойству
математического
ожидания
,
но n
здесь
является константой,
поэтому по
свойству
математического
ожидания
Mp* = 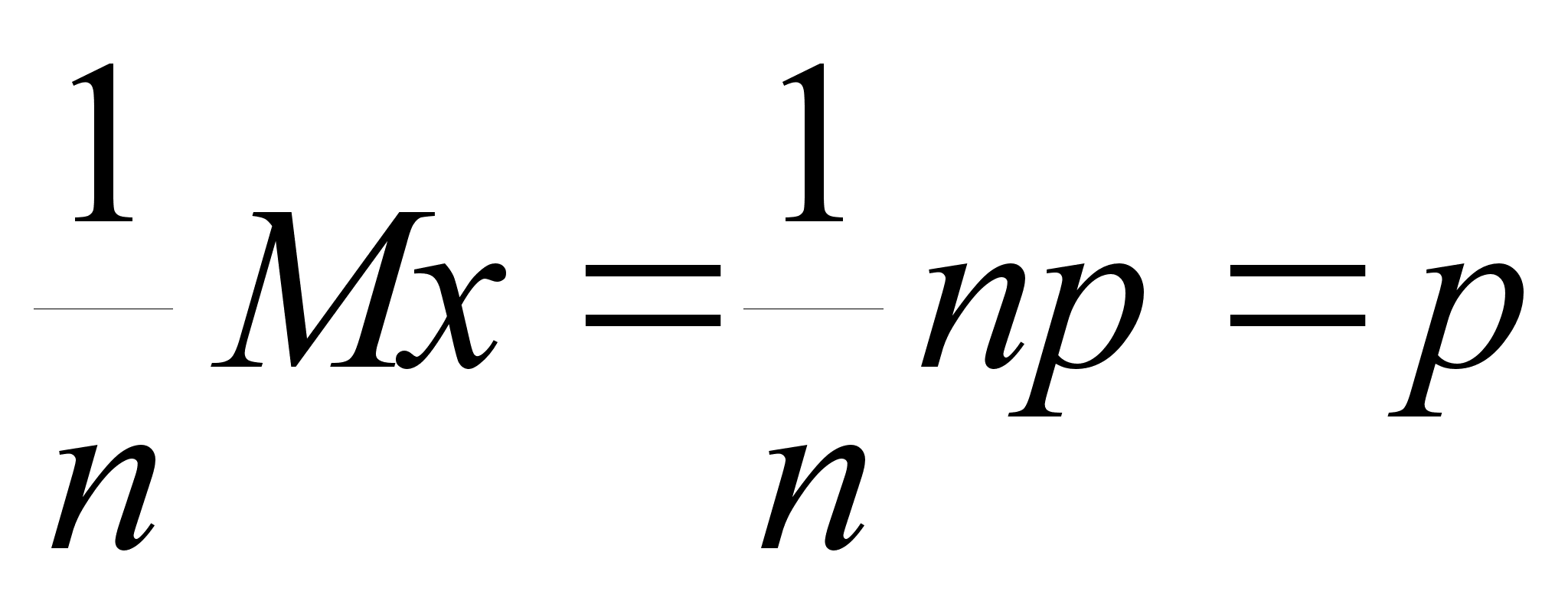
Таким образом, “в среднем” получается истинное значение р, чего и следовало ожидать. Это свойство оценки р* величины р имеет название: р* является несмещённой оценкой для р. Отсутствие систематического отклонения от величины оцениваемого параметра р подтверждает целесообразность использования величины р* в качестве оценки. Вопрос о точности оценки пока оставляем открытым.
3
Биномиальный закон распределения.
Пусть заданы числа n N и p (0 p 1). Тогда каждому целому числу из промежутка [0; n] можно поставить в соответствие вероятность, рассчитанную по формуле Бернулли. Получим закон распределения случайной величины (назовём её )
| |
0 |
|
k |
|
n |
|
Р |
| |
|
| |
Будем говорить, что случайная величина распределена по закону Бернулли. Такой случайной величиной является частота появления события А в n повторных независимых испытаниях, если в каждом испытании событие А происходит с вероятностью p.
Рассмотрим отдельное i-е испытание. Пространство элементарных исходов для него имеет вид
![]()
Определим на этом пространстве случайную величину i следующим образом:
i = 1, если происходит событие А;
i
= 0,
если происходит
событие
![]()
Закон распределения случайной величины i рассматривался в предыдущем параграфе.
|
i |
1 |
0 |
|
Р |
p |
q = 1–p |
M = р; D = рq
Для
i = 1,2,,n
получаем систему
из n
независимых
случайных
величин i,
имеющих одинаковые
законы распределения.
Если теперь
сравнить законы
распределения
двух случайных
величин
и
![]() ,
то можно сделать
очевидный
вывод:
=
,
то можно сделать
очевидный
вывод:
=
![]() .
Отсюда следует,
что для случайной
величины ,
имеющей закон
распределения
Бернулли,
математическое
ожидание и
дисперсия
определяются
формулами
.
Отсюда следует,
что для случайной
величины ,
имеющей закон
распределения
Бернулли,
математическое
ожидание и
дисперсия
определяются
формулами
M
= M![]() =
=
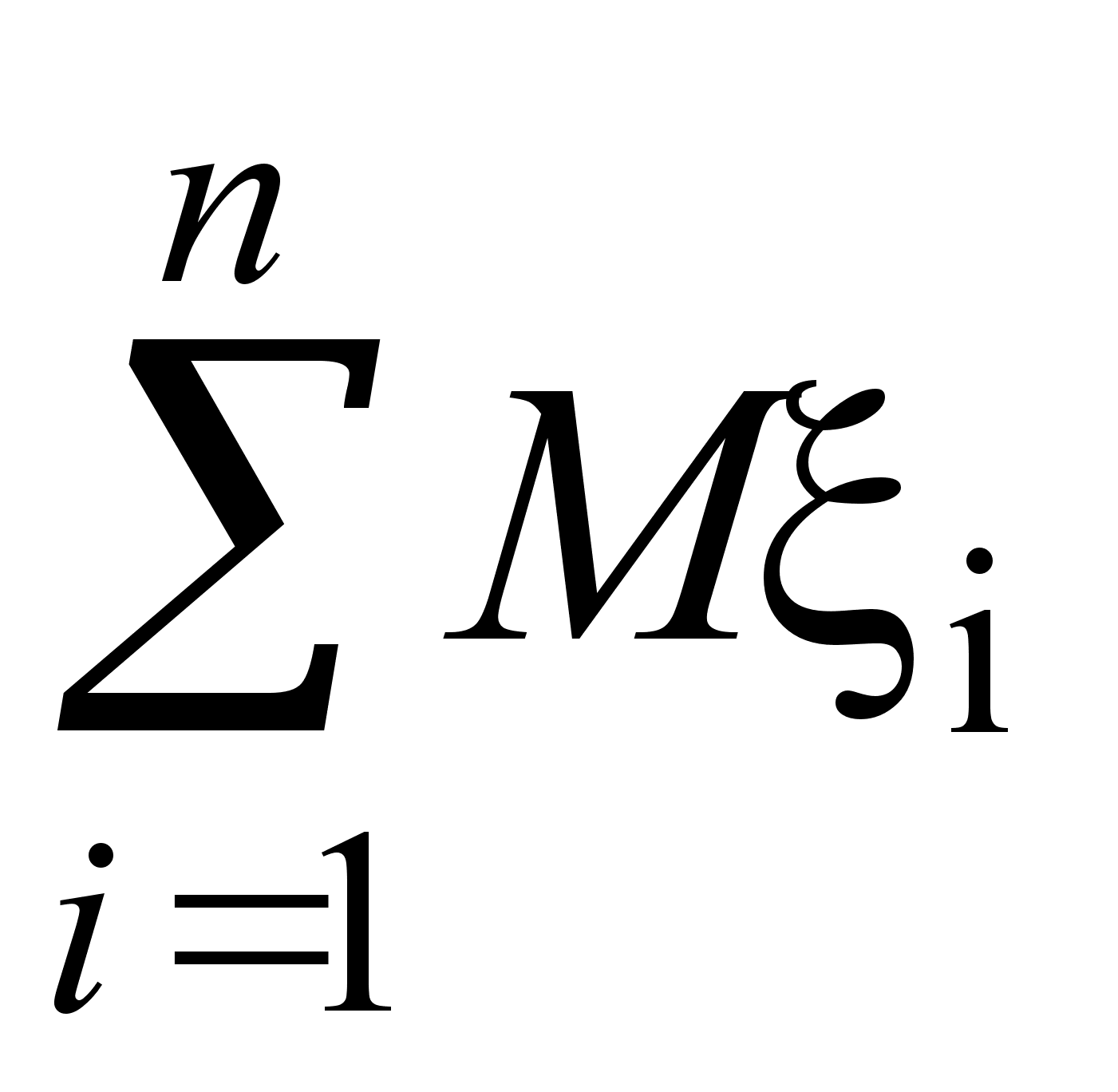 =
=
![]() =
np;
=
np;
D
= D![]() =
=
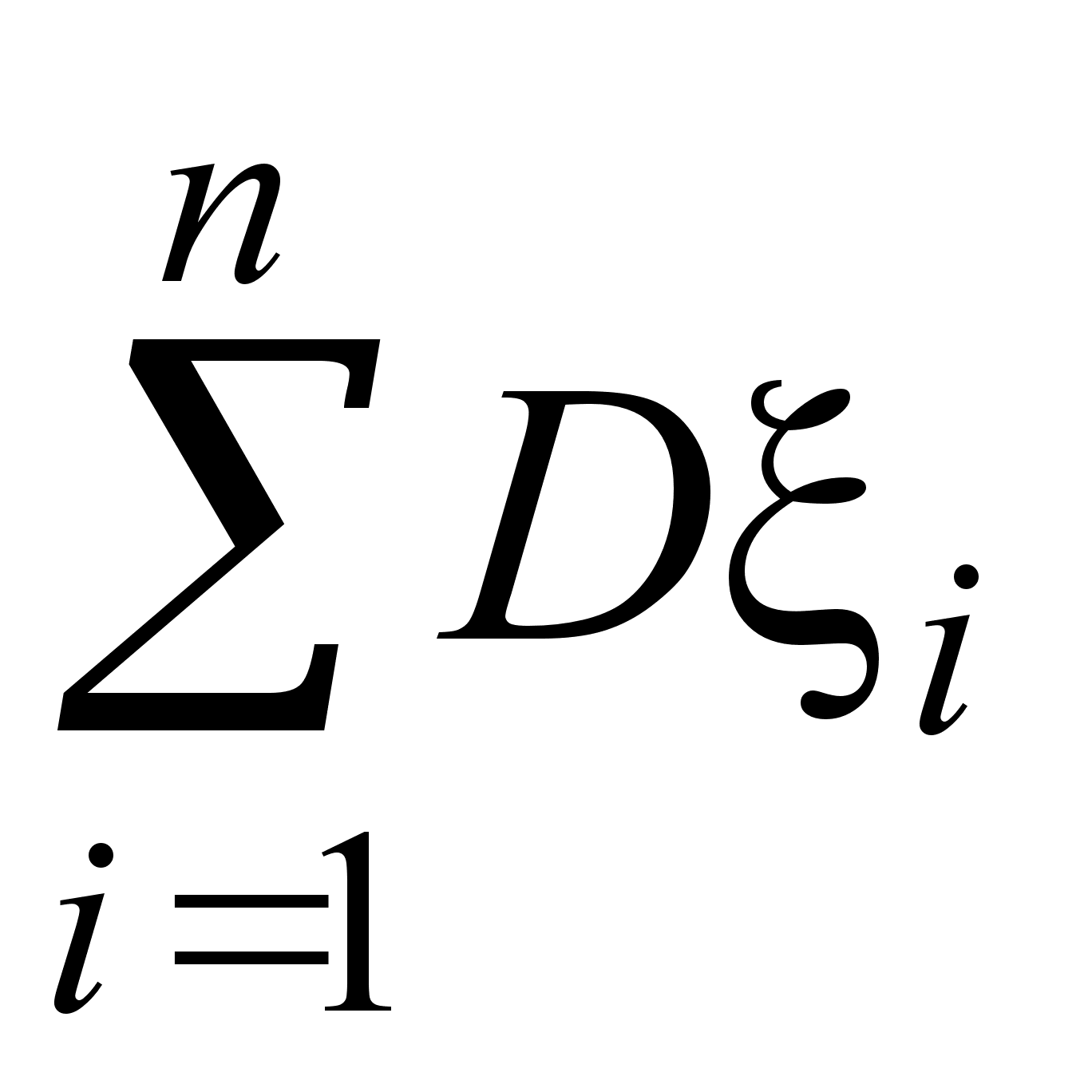 =
=
![]() =
npq
=
npq
Найдём
оценку величины
р — вероятности
успеха в одном
испытании
некоторого
биномиального
эксперимента.
Для этого проведём
n испытаний
и подсчитаем
х – число успехов.
Оценку р*
неизвестной
величины р
определим
формулой р*
=
![]() .
.
Пример.
Из 20 отобранных для контроля образцов продукции 4 оказались нестандартными. Оценим вероятность того, что случайно выбранный экземпляр продукции не отвечает стандарту отношением р* = 4/20 = 0,2.
Так
как х случайная
величина, р*
– тоже случайная
величина. Значения
р* могут
меняться от
одного эксперимента
к другому (в
рассматриваемом
случае экспериментом
является случайный
отбор и контроль
20-ти экземпляров
продукции).
Каково математическое
ожидание
р*? Поскольку
х
есть случайная
величина,
обозначающая
число успехов
в n
испытаниях
по схеме Бернулли,
Мx
= np.
Для математического
ожидания случайной
величины р*
по определению
получаем:
Mp* = M![]() ,
но n
здесь
является константой,
поэтому по
свойству
математического
ожидания
,
но n
здесь
является константой,
поэтому по
свойству
математического
ожидания
Mp* = 
Таким образом, “в среднем” получается истинное значение р, чего и следовало ожидать. Это свойство оценки р* величины р имеет название: р* является несмещённой оценкой для р. Отсутствие систематического отклонения от величины оцениваемого параметра р подтверждает целесообразность использования величины р* в качестве оценки. Вопрос о точности оценки пока оставляем открытым.
5
Непрерывные случайные величины.
Случайная величина, значения которой заполняют некоторый промежуток, называется непрерывной.
В частных случаях это может быть не один промежуток, а объединение нескольких промежутков. Промежутки могут быть конечными, полубесконечными или бесконечными, например: (a; b], (– ; a), [b;), (–; ).
Вообще непрерывная случайная величина – это абстракция. Снаряд, выпущенный из пушки, может пролететь любое расстояние, скажем, от 5 до 5,3 километров, но никому не придёт в голову измерять эту величину с точностью до 0,0000001 километра (то есть до миллиметра), не говоря уже об абсолютной точности. В практике такое расстояние будет дискретной случайной величиной, у которой одно значение от другого отличается по крайней мере на 1 метр.
При описании непрерывной случайной величины принципиально невозможно выписать и занумеровать все её значения, принадлежащие даже достаточно узкому интервалу. Эти значения образуют несчётное множество, называемое «континуум».
Если – непрерывная случайная величина, то равенство = х представляет собой, как и в случае дискретной случайной величины, некоторое случайное событие, но для непрерывной случайной величины это событие можно связать лишь с вероятностью, равной нулю, что однако не влечёт за собой невозможности события. Так например, можно говорить, что только с вероятностью «нуль» снаряд пролетит 5245,7183 метра, или что отклонение действительного размера детали от номинального составит 0,001059 миллиметра. В этих случаях практически невозможно установить, произошло событие или нет, так как измерения величин проводятся с ограниченной точностью, и в качестве результата измерения можно фактически указать лишь границы более или менее узкого интервала, внутри которого находится измеренное значение.
Значениям непрерывной случайной величины присуща некоторая неопределенность. Например, нет практического смысла различать два отклонения от номинального размера, равные 0,5 мм и 0,5000025 мм. Вероятность, отличная от нуля, может быть связана только с попаданием величины в заданный, хотя бы и весьма узкий, интервал. Здесь можно привести сравнение с распределением массы вдоль стержня. Отсутствует масса, сосредоточенная, скажем, в сечении, расположенном на расстоянии 20 см от левого конца стержня, имеет смысл говорить лишь о массе, заключённой между сечениями, проходящими через концы некоторого промежутка.
Пусть – непрерывная случайная величина. Рассмотрим для некоторого числа х вероятность неравенства х < < х + х
P(х < < х + х).
Здесь х – величина малого интервала.
Очевидно, что если х 0, то P(х < < х + х) 0. Обозначим р(х) предел отношения P(х < < х + х) к при х 0, если такой предел существует:
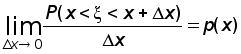 (1)
(1)
Функция р(х) называется плотностью распределения случайной величины. Из формулы (1) следует равенство, справедливое для малых величин х, которое также можно считать определением функции р(х):
P(х < < х + х) ![]() p(x)х (2)
p(x)х (2)
Очевидно, что p(x) – неотрицательная функция. Для определения вероятности того, что случайная величина примет значение из промежутка [a, b] конечной длины, нужно выбрать на промежутке произвольные числа x1, х2,, хn удовлетворяющие условию а=х0х1x2xnb=xn+1. Эти числа разобьют промежуток [a, b] на n+1 частей, представляющих собой промежутки [х0, х1), [х1, х2), ,[хn, b]. Введём обозначения:
х0= х1 – х0, х1= х2 – х1, , хn = b – хn,
и
составим сумму .
Рассмотрим
процесс, при
котором число
точек разбиения
неограниченно
возрастает
таким образом,
что максимальная
величина хi
стремится к
нулю. Будем
считать функцию
p(x)
непрерывной
на промежутке
(а; b),
тогда пределом
суммы
.
Рассмотрим
процесс, при
котором число
точек разбиения
неограниченно
возрастает
таким образом,
что максимальная
величина хi
стремится к
нулю. Будем
считать функцию
p(x)
непрерывной
на промежутке
(а; b),
тогда пределом
суммы
![]()
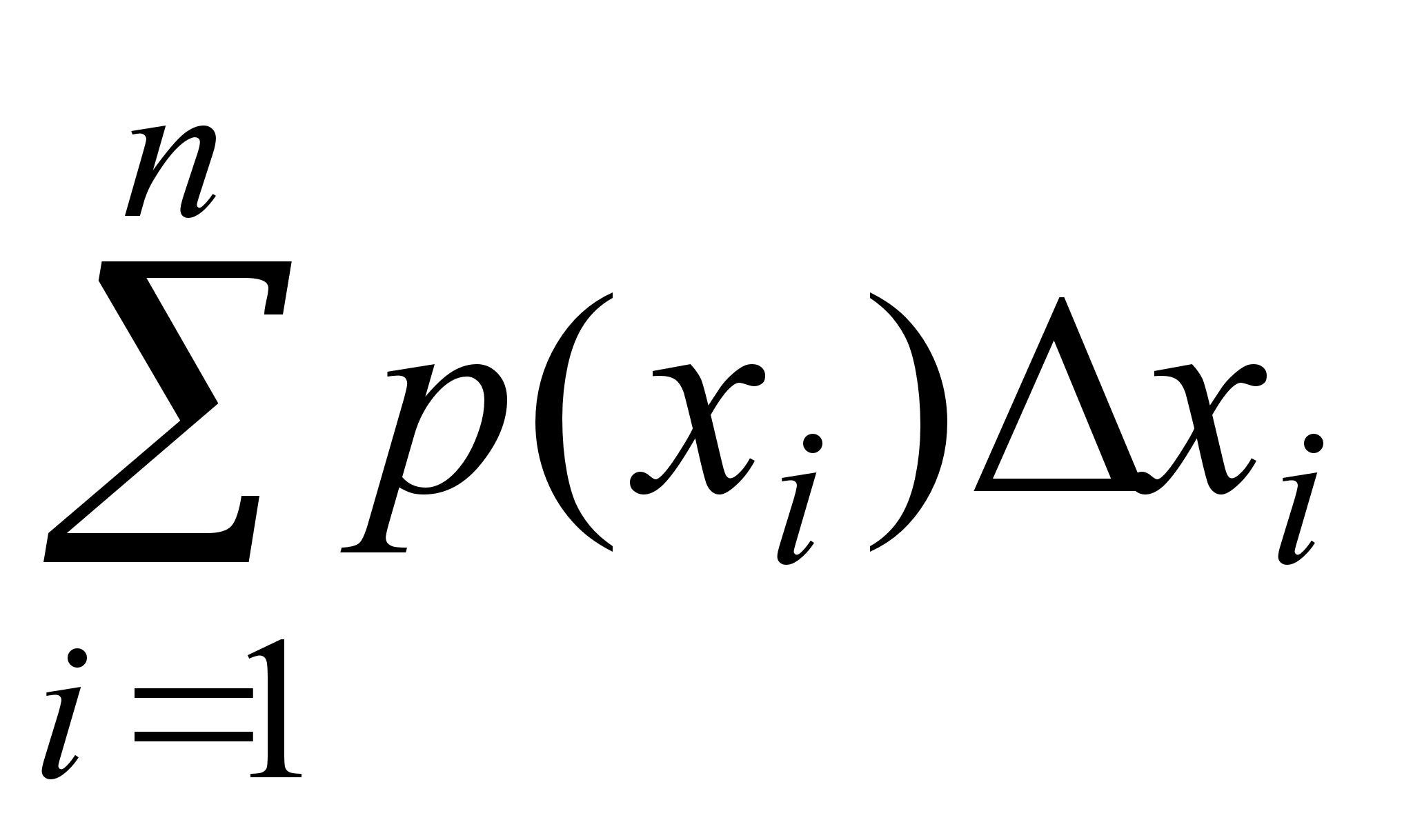 будет
определённый
интеграл по
промежутку
[a;
b]
от функции
p(x),
равный искомой
вероятности:
будет
определённый
интеграл по
промежутку
[a;
b]
от функции
p(x),
равный искомой
вероятности:
P(a b) = 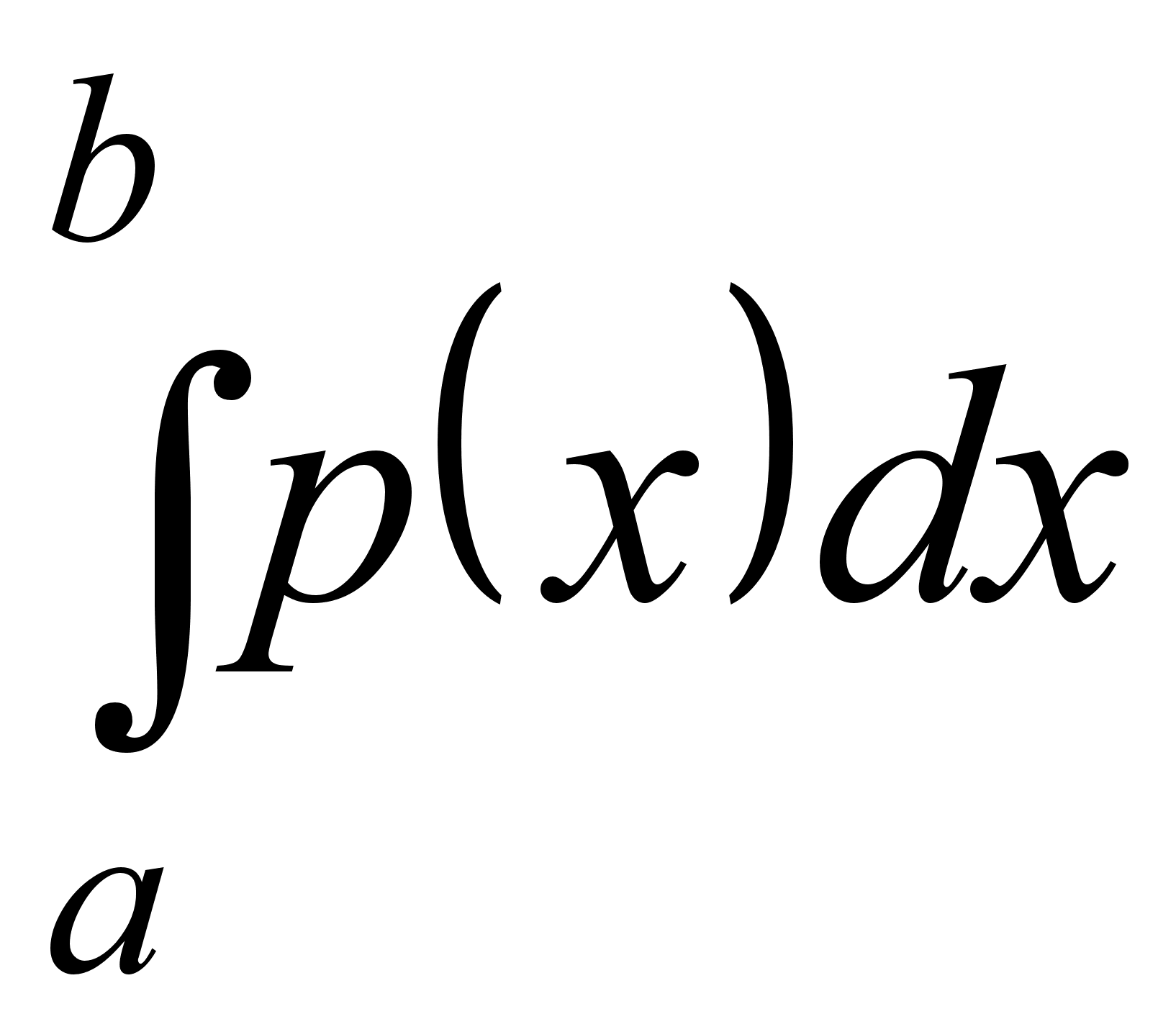 (3)
(3)
Э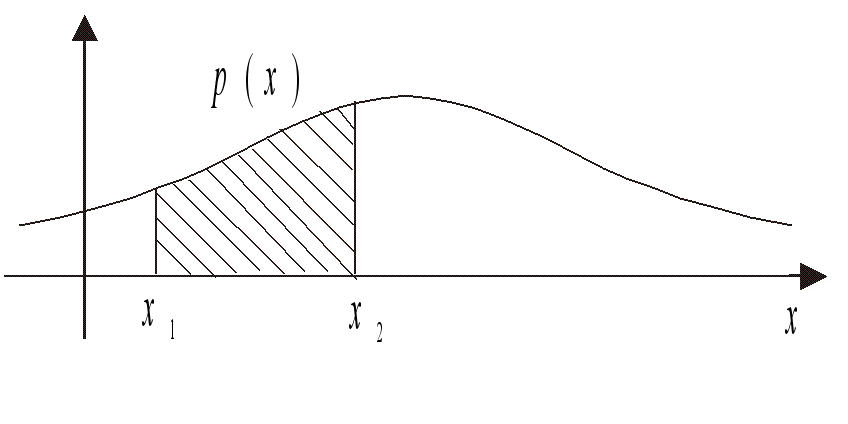
Рис. 1
то равенство можно также рассматривать как определение функции р(х). Отсюда следует, что вероятность попадания случайной величины в любой интервал (х1, х2) равна площади фигуры, образованной отрезком [х1, х2] оси х, графиком функции р(х) и вертикальными прямыми х = х1, х = х2, как изображено на рисунке 1.Если все возможные значения случайной величины принадлежат интервалу (а; b), то для р(х) – её плотности распределения справедливо равенство
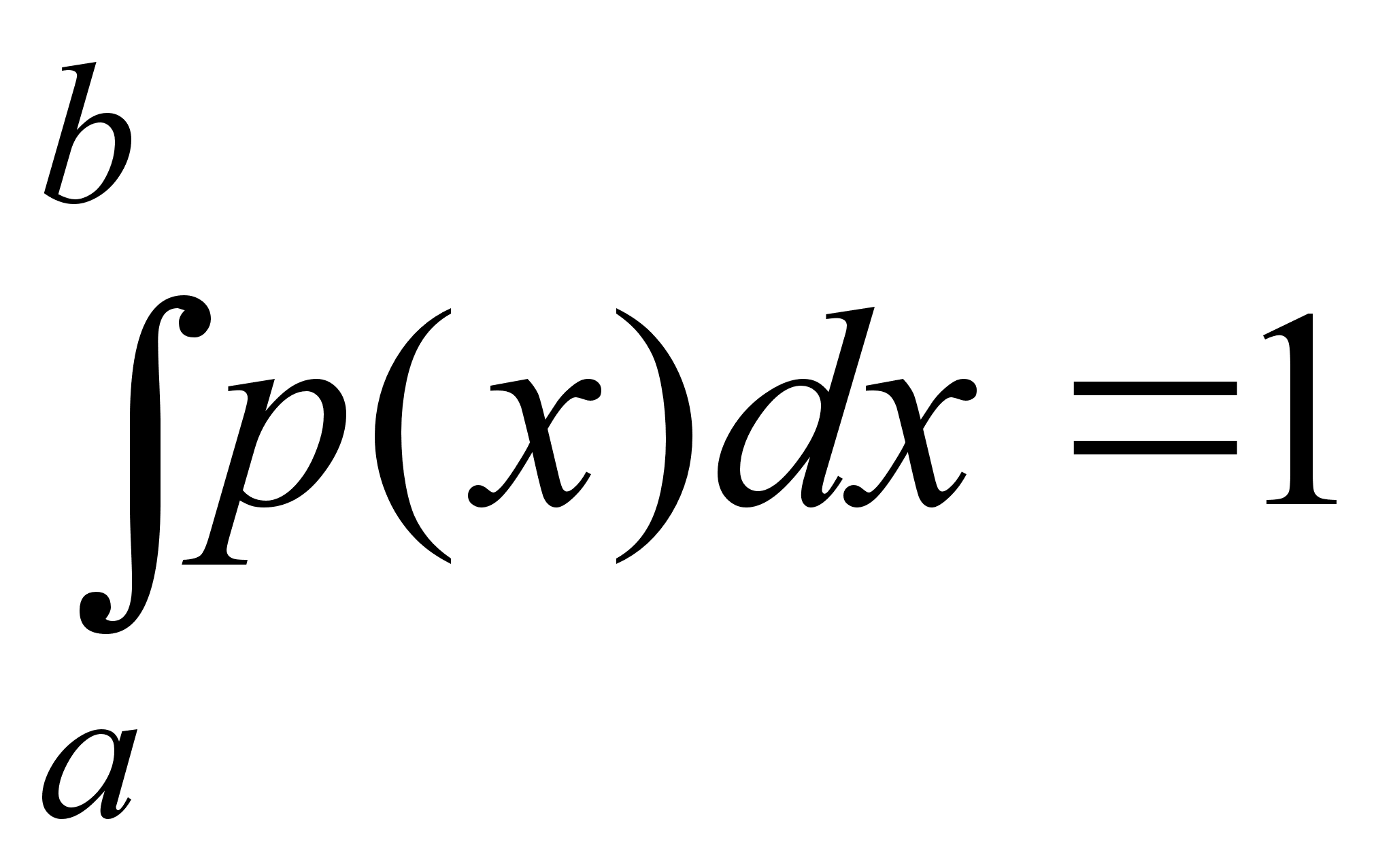
Для удобства иногда считают функцию р(х) определённой для всех значений х, полагая её равной нулю в тех точках х, которые не являются возможными значениями этой случайной величины.
Плотностью распределения может служить любая интегрируемая функция р(х), удовлетворяющая двум условиям:
р(х) 0;
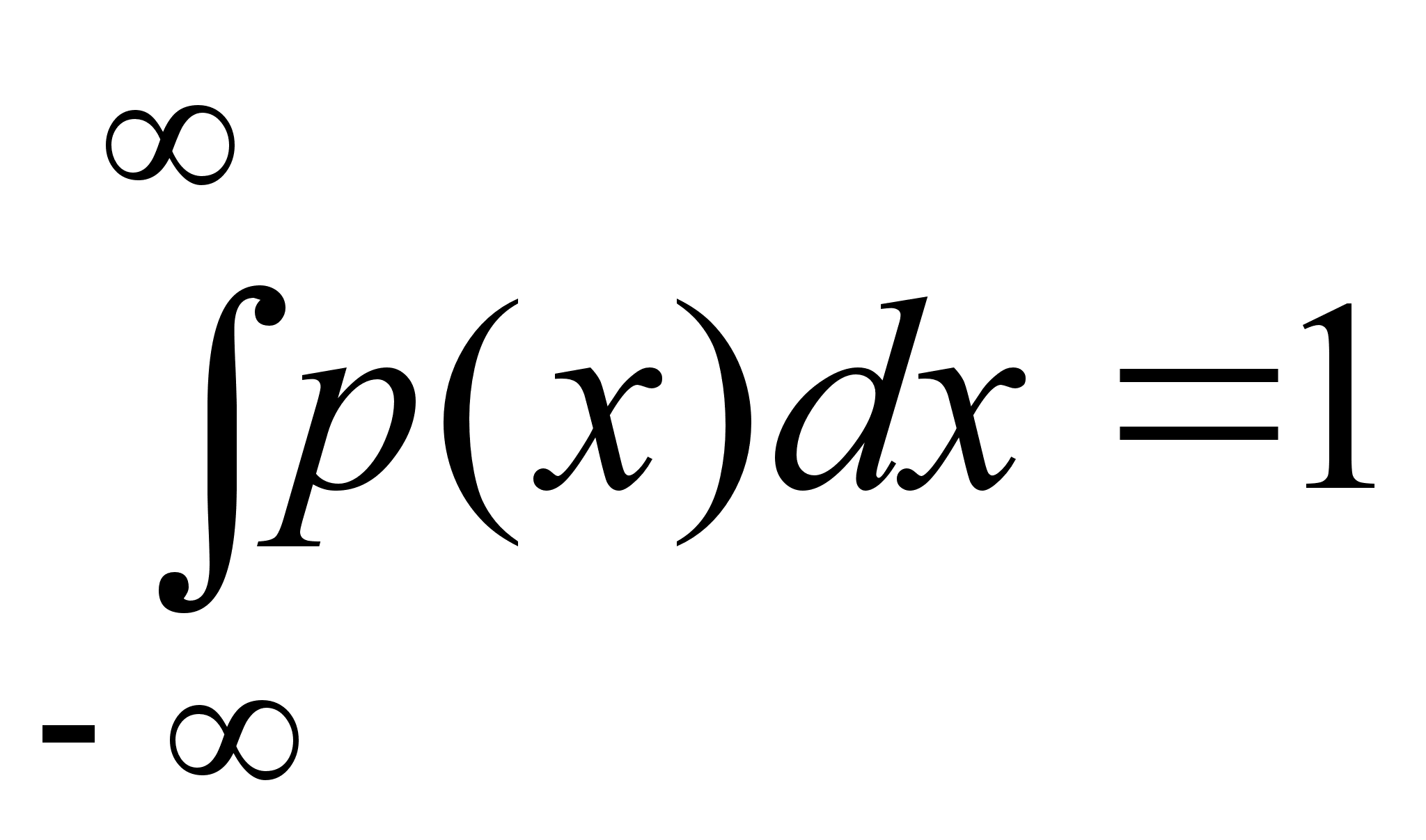
Можно задавать случайную величину, задавая функцию р(х), удовлетворяющую этим условиям.
В качестве примера рассмотрим случайную величину , равномерно распределённую на промежутке [a; b]. В этом случае р(х) постоянна внутри этого промежутка:
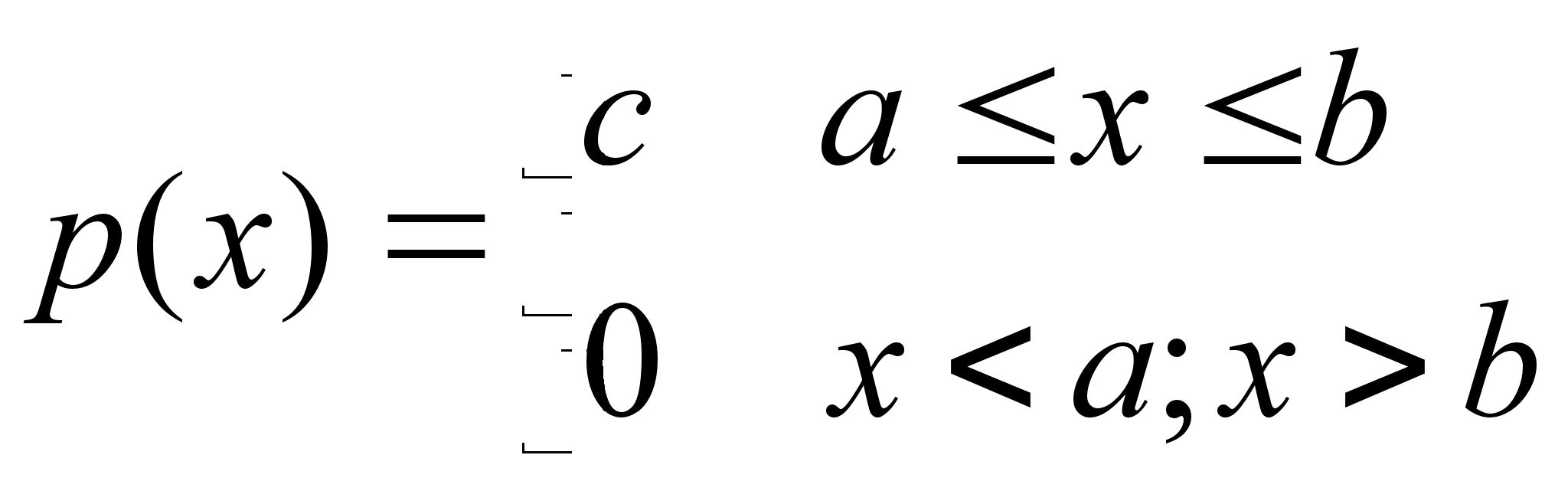
По свойству 2) функции р(х)
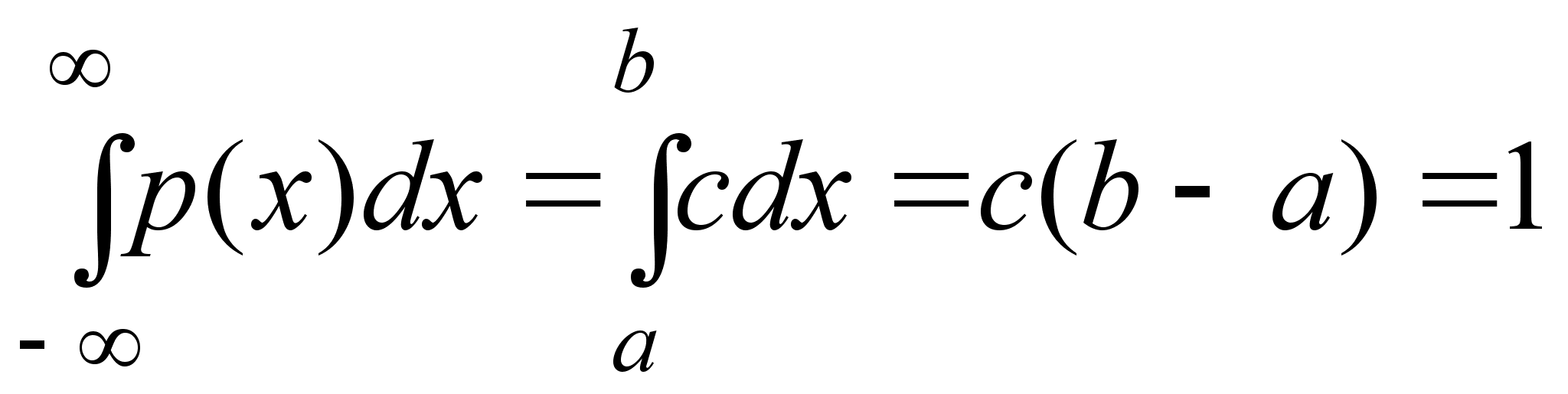
О
Рис. 2
тсюда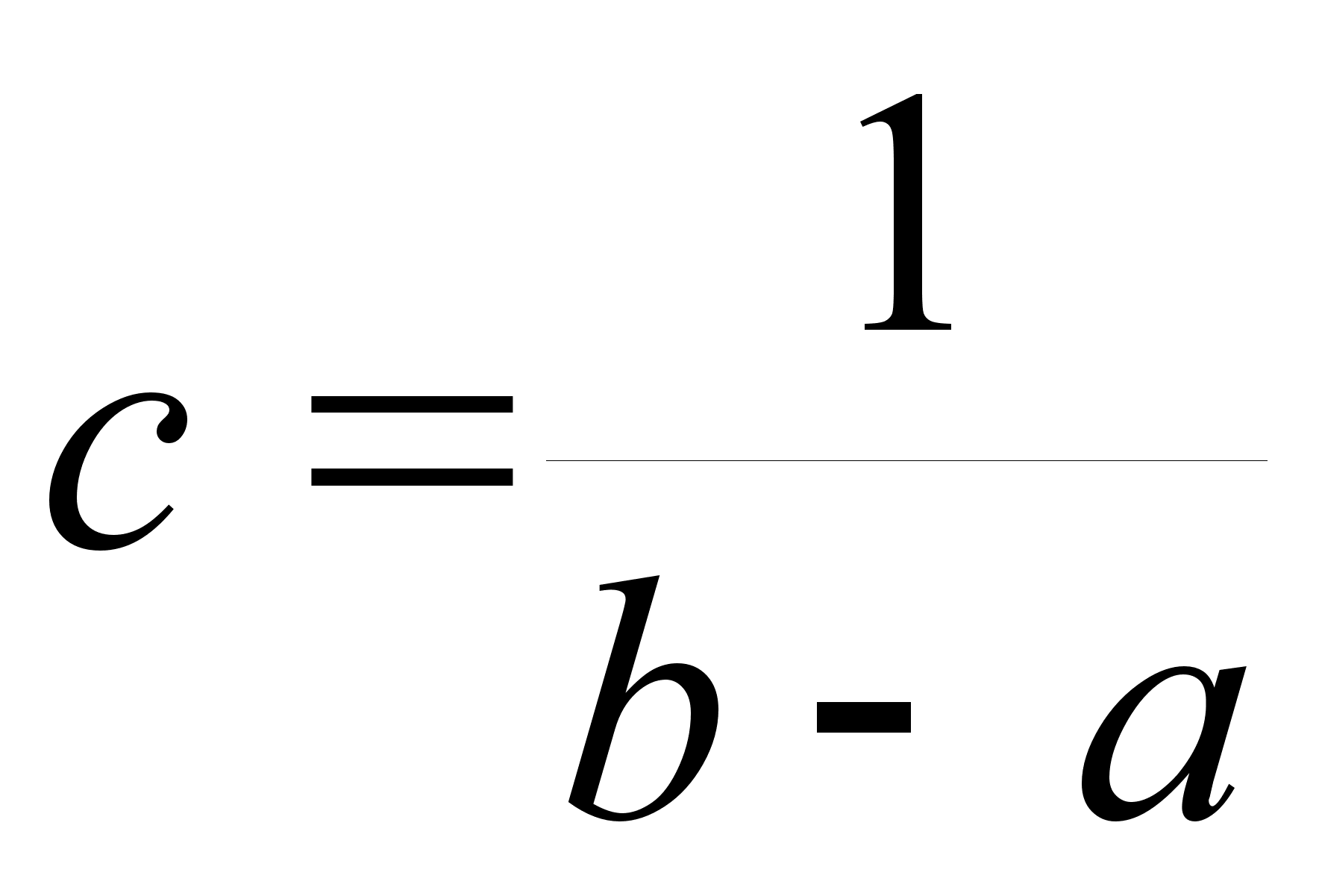 .
График функции
р(х) представлен
на рисунке 2.
.
График функции
р(х) представлен
на рисунке 2.
Во многих практических задачах встречаются случайные величины, у которых возможные значения не ограничены сверху и снизу. В этом случае кривая распределения располагается над осью х и при х и х – асимптотически приближается к этой оси, как изображено на рисунке 1. Вероятность того, что случайная величина примет значение, меньшее некоторого числа а, равна площади фигуры, заключённой между кривой распределения и горизонтальной координатной осью слева от точки а. Будем считать, что такая площадь существует.
Пусть – непрерывная случайная величина. Функция F(x), которая определяется равенством
![]() ,
,
называется
интегральной
функцией
распределения
или просто
функцией
распределения
случайной
величины .
Непосредственно
из определения
следует равенство
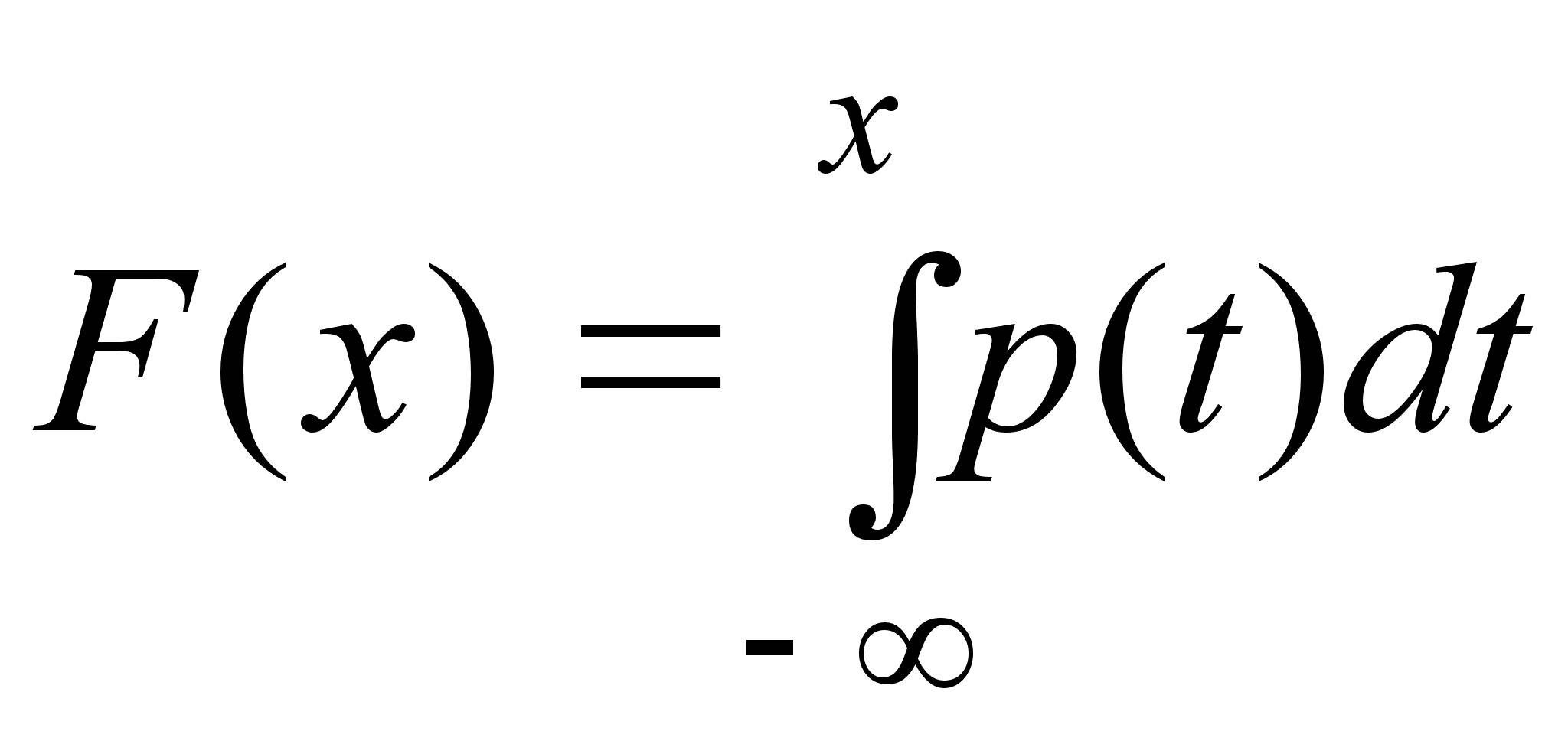 .
Формула производной
определённого
интеграла по
верхнему пределу
в данном случае
приводит к
соотношению
.
Формула производной
определённого
интеграла по
верхнему пределу
в данном случае
приводит к
соотношению
![]() .
Плотность
распределения
р(х)
называют
дифференциальной
функцией
распределения.
.
Плотность
распределения
р(х)
называют
дифференциальной
функцией
распределения.
Функция распределения F(x) случайной величины имеет следующие свойства.
F(x) — непрерывная возрастающая функция.
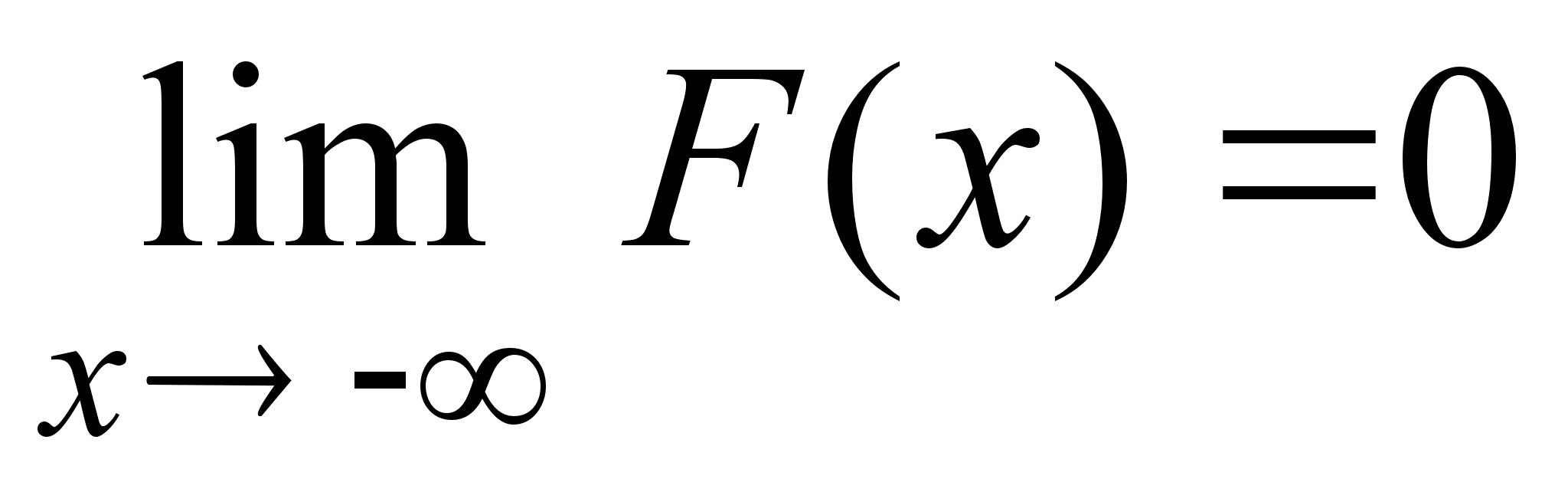 ;
;
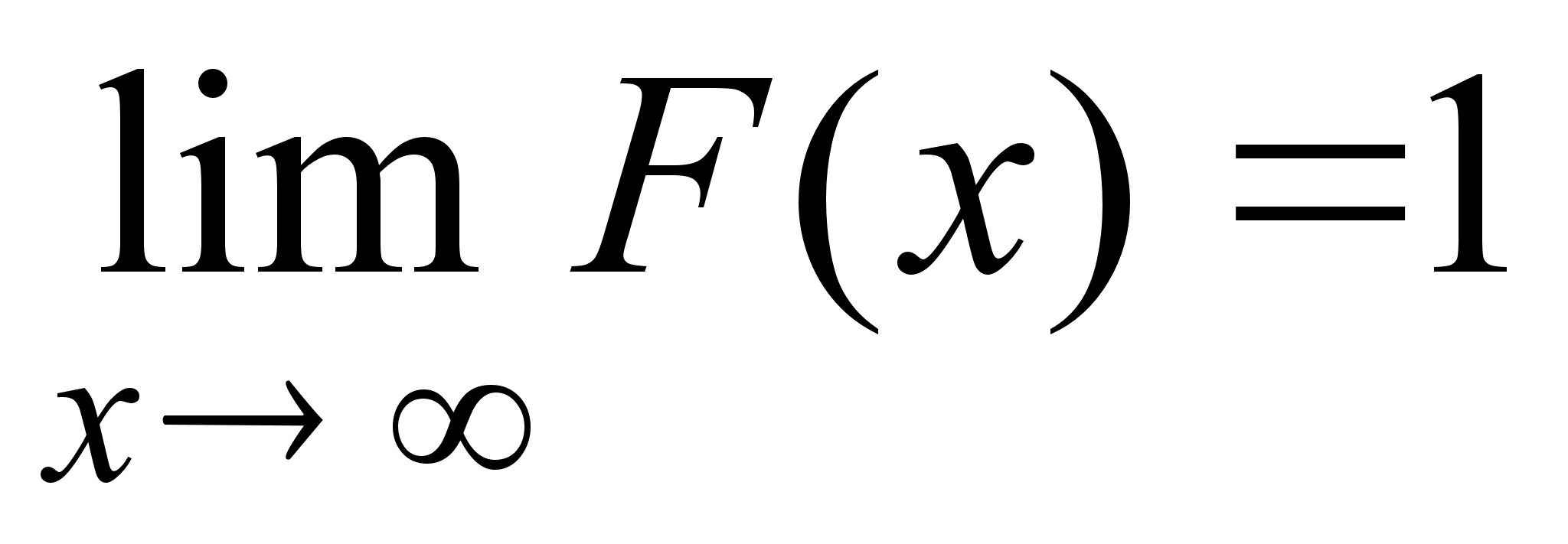
Свойства 1 и 2 вытекают непосредственно из определения функции F(x).
Приращение F(x) на промежутке (х1; х2) равно вероятности того, что случайная величина принимает значение из этого промежутка:
F(x2) – F(x1) = P(x1 < x2)
Доказательство.
F(x2) = P( x2) = P( x1) + P(x1 < x2) = F(x1) + P(x1 < x2)
Отсюда
P(x1 < x2) = F(x2) – F(x1)
Заметим, что для непрерывной случайной величины справедливы равенства
P(x1 < x2) = P(x1 < x2) = P(x1 x2) = P(x1 x2)
Для равномерного распределения функция F(x) имеет вид:

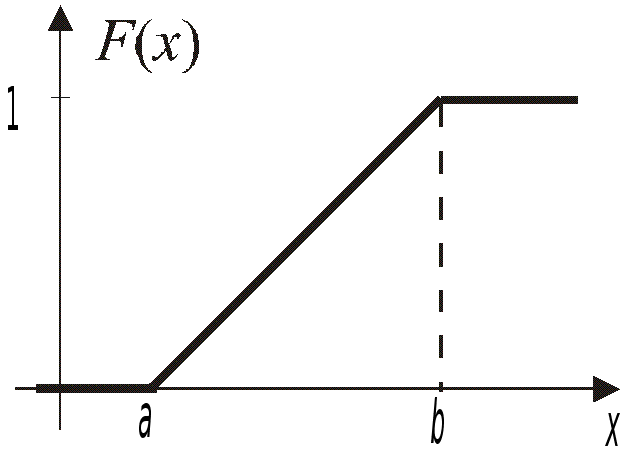
Рис. 3
График функции F(x) представлен на рисунке 3.Закон распределения непрерывной случайной величины можно определить заданием либо функции р(х), либо функции F(x).
9
Правило 3-х (трех “сигм”).
Пусть имеется нормально распределённая случайная величина с математическим ожиданием, равным а и дисперсией 2. Определим вероятность попадания в интервал (а – 3; а + 3), то есть вероятность того, что принимает значения, отличающиеся от математического ожидания не более, чем на три среднеквадратических отклонения.
P(а – 3< < а + 3)=Ф(3) – Ф(–3)=2Ф(3)
По таблице находим Ф(3)=0,49865, откуда следует, что 2Ф(3) практически равняется единице. Таким образом, можно сделать важный вывод: нормальная случайная величина принимает значения, отклоняющиеся от ее математического ожидания не более чем на 3.
(Выбор числа 3 здесь условен и никак не обосновывается: можно было выбрать 2,8, 2,9 или 3,2 и получить тот же вероятностный результат. Учитывая, что Ф(2)=0,477, можно было бы говорить и о правиле 2–х “сигм”.)
Совместное распределение двух случайных величин.
Пусть пространство элементарных исходов случайного эксперимента таково, что каждому исходу ij ставиться в соответствие значение случайной величины , равное xi и значение случайной величины , равное yj.
Примеры:
Представим себе большую совокупность деталей, имеющих вид стержня. Случайный эксперимент заключается в случайном выборе одного стержня. Этот стержень имеет длину, которую будем обозначать и толщину— (можно указать другие параметры—объем, вес, чистота обработки, выраженная в стандартных единицах).
Если результат эксперимента—случайный выбор какого–либо предприятия в данной области, то за можно принимать объем производства отнесенный к количеству сотрудников, а за —объем продукции, идущей на экспорт, тоже отнесенной к числу сотрудников.
В этом случае мы можем говорить о совместном распределении случайных величин и или о “двумерной” случайной величине.
Если и дискретны и принимают конечное число значений ( – n значений, а – k значений), то закон совместного распределения случайных величин и можно задать, если каждой паре чисел xi, yj (где xi принадлежит множеству значений , а y j—множеству значений ) поставить в соответствие вероятность pij, равную вероятности события, объединяющего все исходы ij (и состоящего лишь из этих исходов), которые приводят к значениям
= xi; = y j.
Такой закон распределения можно задать в виде таблицы:
|
|
y1 |
y2 |
|
yj |
|
yk |
||
|
x1 |
р11 |
р12 |
|
р1j |
|
р1k |
P1 |
|
|
|
|
|
|
|
|
|
|
|
|
xi |
рi1 |
рi2 |
|
рij |
|
рik |
Pi |
(*) |
|
|
|
|
|
|
|
|
|
|
|
xn |
рn1 |
рn2 |
|
рnj |
|
рnk |
Pn |
|
|
P1 |
P2 |
|
Pj |
|
Pk |
|
Очевидно
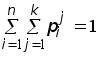
Если просуммировать все рij в i–й строке, то получим
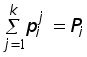
вероятность того, что случайная величина примет значение xi. Аналогично, если просуммировать все рij в j–м столбце, то получим
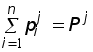
вероятность того, что принимает значение y j.
Соответствие xi Pi (i = 1,2,,n) определяет закон распределения , также как соответствие yj P j (j = 1,2,,k) определяет закон распределения случайной величины .
Очевидно
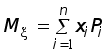 ,
,
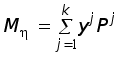 .
.
Раньше мы говорили, что случайные величины и независимы, если
pij=PiP j (i=1,2,,n; j=1,2,,k).
Если это не выполняется, то и зависимы.
В чем проявляется зависимость случайных величин и и как ее выявить из таблицы?
Рассмотрим столбец y1. Каждому числу xi поставим в соответствие число
pi/1=![]() (1)
(1)
которое
будем называть
условной вероятностью
=
xi при
=y1.
Обратите внимание
на то, что это
не вероятность
Pi
события =
xi, и
сравните формулу
(1) с уже известной
формулой условной
вероятности
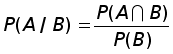 .
.
Соответствие
xiрi/1, (i=1,2,,n)
будем
называть условным
распределением
случайной
величины
при =y1.
Очевидно
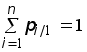 .
.
Аналогичные
условные законы
распределения
случайной
величины
можно построить
при всех остальных
значениях ,
равных y2;
y3,,
yn
,ставя в соответствие
числу xi
условную вероятность
pi/j =![]() (
(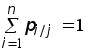 ).
).
В таблице приведён условный закон распределения случайной величины при =yj
|
|
x1 |
x2 |
|
xi |
|
xn |
|
pi/j |
|
|
|
|
|
|
Можно ввести понятие условного математического ожидания при = yj
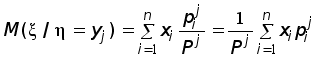
Заметим, что и равноценны. Можно ввести условное распределение при =xi соответствием
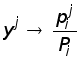 (j = 1,2,,k)
(j = 1,2,,k)
Также можно ввести понятие условного математического ожидания случайной величины при =xi :

Из определения следует, что если и независимы, то все условные законы распределения одинаковы и совпадают с законом распределения (напоминаем, что закон распределения определяется в таблице (*) первым и последним столбцом). При этом очевидно, совпадают все условные математические ожидания М(/ = yj) при j = 1,2,,k, которые равны М.
Если условные законы распределения при различных значениях различны, то говорят, что между и имеет место статистическая зависимость.
Пример I. Пусть закон совместного распределения двух случайных величин и задан следующей таблицей. Здесь, как говорилось ранее, первый и последний столбцы определяют закон распределения случайной величины , а первая и последняя строки – закон распределения случайной величины .
|
|
1 |
2 |
3 |
|
|
10 |
1/36 |
0 |
0 |
1/36 |
|
20 |
2/36 |
1/36 |
0 |
3/36 |
|
30 |
2/36 |
3/36 |
2/36 |
7/36 |
|
40 |
1/36 |
8/36 |
16/36 |
25/36 |
|
6/36 |
12/36 |
18/36 |
Полигоны условных распределений можно изобразить на трехмерном графике (рис. 1).
Пример II. (Уже встречавшийся).
Пусть даны две независимые случайные величины и с законами распределения
|
|
0 |
1 |
|
1 |
2 |
|
|
Р |
1/3 |
2/3 |
Р |
3/4 |
1/4 |
Найдем законы распределений случайных величин =+ и =
|
|
1 |
2 |
3 |
|
0 |
1 |
2 |
|
|
Р |
3/12 |
7/12 |
2/12 |
Р |
4/12 |
6/12 |
2/12 |
Построим таблицу закона совместного распределения и .
|
|
0 |
1 |
2 |
|
|
1 |
3/12 |
0 |
0 |
3/12 |
|
2 |
1/12 |
6/12 |
0 |
7/12 |
|
3 |
0 |
0 |
2/12 |
2/12 |
|
4/12 |
6/12 |
2/12 |
Чтобы получить =2 и =0, нужно чтобы приняла значение 0, а приняла значение 2. Так как и независимы, то
Р(=2; =0)= Р(=0; =2)=Р(=0)Р(=2)=1/12.
Очевидно также Р(=3; =0)=0.

Пример III.
Рассмотрим закон совместного распределения и , заданный таблицей
|
|
0 |
1 |
2 |
|
|
1 |
1/30 |
3/30 |
2/30 |
1/5 |
|
2 |
3/30 |
9/30 |
6/30 |
3/5 |
|
3 |
1/30 |
3/30 |
2/30 |
1/5 |
|
1/6 |
3/6 |
2/6 |
В этом случае выполняется условие P(=xi; =yj)=P(=xi)P(=yj), i=1,2,3; j=1,2,3,
Построим законы условных распределений
|
|
1 |
2 |
3 |
|
|
1/5 |
3/5 |
1/5 |
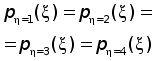
Законы условных распределений не отличаются друг от друга при =1,2,3 и совпадают с законом распределения случайной величины .
В данном случае и независимы.
Характеристикой зависимости между случайными величинами и служит математическое ожидание произведения отклонений и от их центров распределений (так иногда называют математическое ожидание случайной величины), которое называется коэффициентом ковариации или просто ковариацией.
cov(; ) = M((–M)(–M))
Пусть = x1, x2, x3,, xn, = y1, y2, y3,,yn. Тогда
cov(;
)= (2)
(2)
Эту формулу можно интерпретировать так. Если при больших значениях более вероятны большие значения , а при малых значениях более вероятны малые значения , то в правой части формулы (2) положительные слагаемые доминируют, и ковариация принимает положительные значения.
Если же более вероятны произведения (xi – M)(yj – M), состоящие из сомножителей разного знака, то есть исходы случайного эксперимента, приводящие к большим значениям в основном приводят к малым значениям и наоборот, то ковариация принимает большие по модулю отрицательные значения.
В первом случае принято говорить о прямой связи: с ростом случайная величина имеет тенденцию к возрастанию.
Во втором случае говорят об обратной связи: с ростом случайная величина имеет тенденцию к уменьшению или падению.
Если примерно одинаковый вклад в сумму дают и положительные и отрицательные произведения (xi – M)(yj – M)pij, то можно сказать, что в сумме они будут “гасить” друг друга и ковариация будет близка к нулю. В этом случае не просматривается зависимость одной случайной величины от другой.
Легко показать, что если
P(( = xi)∩( = yj)) = P( = xi)P( = yj) (i = 1,2,,n; j = 1,2,,k),
то cov(; )= 0.
Действительно из (2) следует
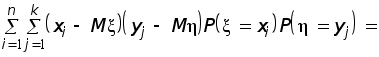
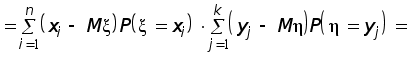
![]()
Здесь использовано очень важное свойство математического ожидания: математическое ожидание отклонения случайной величины от ее математического ожидания равно нулю.
Доказательство (для дискретных случайных величин с конечным числом значений).
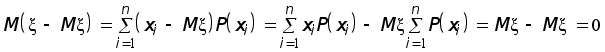
Ковариацию удобно представлять в виде
cov(; )=M(–M–M+MM)=M()–M(M)–M(M)+M(MM)=
=M()–MM–MM+MM=M()–MM
Ковариация двух случайных величин равна математическому ожиданию их произведения минус произведение математических ожиданий.
Легко
доказывается
следующее
свойство
математического
ожидания: если
и —независимые
случайные
величины, то
М()=ММ.
(Доказать самим,
используя
формулу M() = 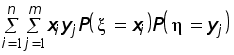 )
)
Таким образом, для независимых случайных величин и cov(;)=0.
5
Лекция 9Коэффициент корреляции.
Величина cov(;) зависит от единиц измерения, в которых выражаются и . (Например, пусть и —линейные размеры некоторой детали. Если за единицу измерения принять 1 см, то cov(;) примет одно значение, а если за единицу измерения принять 1 мм, то cov(;) примет другое, большее значение (при условии cov(;)0)). Поэтому cov(;) неудобно принимать за показатель связи.
Чтобы иметь дело с безразмерным показателем, рассмотрим случайные величины
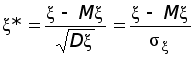 ;
;
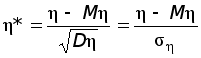
Такие случайные величины называются нормированными отклонениями случайных величин и .
Каждая из случайных величин * и * имеет центром (математическое ожидание) нуль и дисперсию, равную единице. Приведём доказательство для случайной величины *.
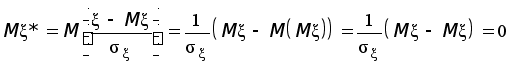
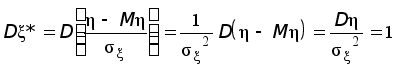
Ковариация * и * называется коэффициентом корреляции случайных величин и (обозначается ).
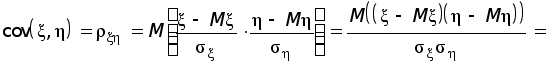
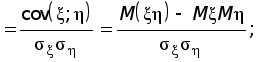
![]()
Для независимых и =0, так как в этом случае cov(;)=0
Обратного заключения сделать нельзя. Случайные величины могут быть связаны даже функциональной зависимостью (каждому значению одной случайной величины соответствует единственное значение другой случайной величины), но коэффициент их корреляции будет равен нулю.
Примеры:
1. Пусть
случайная
величина
симметрично
распределена
около нуля.
Тогда М=0.
Пусть =2.
Тогда М(
)=М(3)=0,
так 3
тоже симметрично
распределена
около нуля. С
другой стороны
ММ=0,
так как М=0.
Таким образом
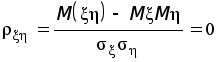 .
.
2. Пусть закон совместного распределения случайных величин и задан таблицей
|
|
1 |
2 |
|
|
1 |
1/5 |
0 |
1/5 |
|
2 |
0 |
3/5 |
3/5 |
|
3 |
1/5 |
0 |
1/5 |
|
2/5 |
3/5 |
Проведём вычисления:
![]() ;
;
![]() ;
;
![]() ;
;
![]() .
.
Отсюда следует, что =0. При этом очевидно, что имеет место функциональная зависимость случайной величины от случайной величины .
Коэффициент корреляции не меняет своей величины, если вместо случайной величины рассматривать случайную величину 1=+а или 2=k (а и
k—постоянные числа, k > 0), так как при перемене начала координат или при изменении масштаба величины нормированное отклонение не меняется. Сказанное в равной мере относится и к .
Вставка! Полезно запомнить формулу
D()=D+D+2cov(;)
Отсюда следует свойство дисперсии для независимых и :
D()=D+D
Свойства коэффициента корреляции.
–11
Если =1, то =k+b, где k и b—константы, k>0.
Если = –1, то = k+b, где k
Если =k+b, (k0) или =k1+b1, то
=1 при k>0
= – 1 при k
Коэффициент корреляции достигает своих предельных значений –1 и 1 в том и только в том случае, если совместное распределение и все концентрируется на некоторой прямой в плоскости ; , то есть между и имеется такая линейная зависимость.
Если к единице совместное распределение ; имеет тенденцию концентрироваться вблизи некоторой прямой линии и величину можно считать мерой близости к полной линейной зависимости между и .
Пример. Рассчитаем коэффициент корреляции для случайных величин при заданном законе совместного распределения
|
|
1 |
2 |
3 |
|
|
10 |
1/36 |
0 |
0 |
1/36 |
|
20 |
2/36 |
1/36 |
0 |
3/36 |
|
30 |
2/36 |
2/36 |
2/36 |
6/36 |
|
40 |
1/36 |
9/36 |
16/36 |
26/36 |
|
6/36 |
12/36 |
18/36 |
![]()
![]()
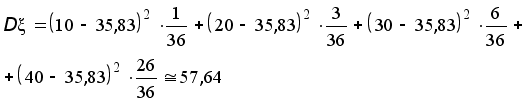
7,6
![]()
0,746
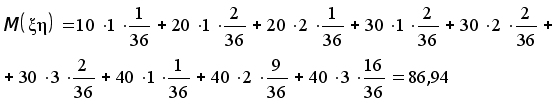
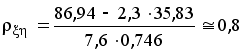
Введем понятие корреляционной зависимости между и .
Пусть задан закон совместного распределения двух случайных величин и (как в вышеприведенном примере), и условное математическое ожидание меняется в зависимости от значения . Тогда принято говорить о корреляционной зависимости от . Если условное математическое ожидание есть линейная функция от , то между и имеется линейная корреляционная связь или зависимость.
Как правило, говоря о корреляционной зависимости, имеют в виду линейную корреляционную зависимость. Если имеется в виду нелинейная корреляционная зависимость, то это особо оговаривают.
Можно дать определение корреляционной зависимости двух случайных величин и как связи между тенденциями роста и . Например, между и существует прямая корреляционная зависимость, если с ростом случайная величина имеет тенденцию возрастать. (Это означает, что при больших значениях с большей вероятностью встречаются большие значения ). Если большим значениям с большей вероятностью соответствуют меньшие значения , то есть с ростом случайная величина имеет тенденцию убывать, говорят, что между и существует обратная корреляционная зависимость.
Глубина (или теснота) корреляционной зависимости (или связи) характеризуется коэффициентом . Чем ближе к единице, тем теснее глубина корреляционной зависимости.
Чем ближе зависимость между условным математическим ожиданием и случайной величиной к линейной, и чем теснее значения группируются около условных математических ожиданий, тем глубже (теснее) корреляционная связь.
Можно говорить о совместном распределении двух непрерывных случайных величин. В большинстве случаев возможен переход от непрерывных случайных величин к совместному распределению двух дискретных случайных величин следующим образом.
Нужно разбить отрезок a; b изменения случайной величины на равные отрезки c0=a; c1; c1; c2; c2; c3,,cn-1; cn=b. За значение случайной величины принять середину каждого отрезка.
Также надо поступить со случайной величиной , разбив ее область значений e; f на равные отрезки g0 = e; g1; g1; ge…gk-1; gk=f, и приняв за возможные значения середины отрезков gk-1; gk. Таким образом мы получили дискретные случайные величины *=x1; x2; …xn и *=y1; y2; …yk, причем каждой паре (xi; yj) ставится в соответствие вероятность
Pij = P(([ci–1; ci])∩([gi–1; gi]))
Таким образом мы придем к уже изученному материалу.